 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of the Sampling-Based Alignment Method and Its Contributions
Paper and Code
Aug 21, 2013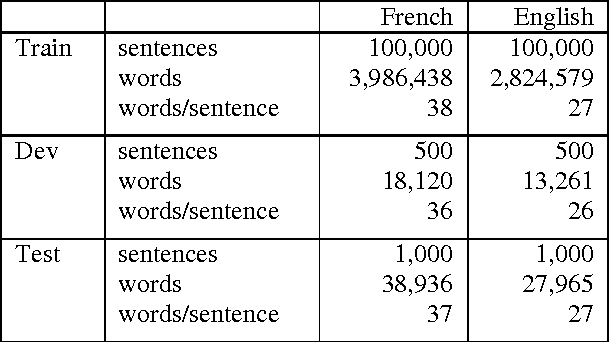
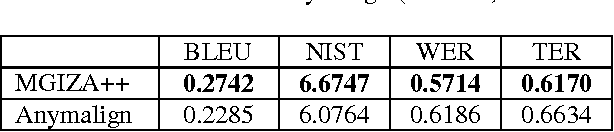

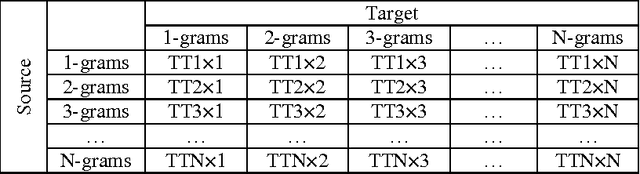
By investigating the distribution of phrase pairs in phrase translation tables, the work in this paper describes an approach to increase the number of n-gram alignments in phrase translation tables output by a sampling-based alignment method. This approach consists in enforcing the alignment of n-grams in distinct translation subtables so as to increase the number of n-grams. Standard normal distribution is used to allot alignment time among translation subtables, which results in adjustment of the distribution of n- grams. This leads to better evaluation results on statistical machine translation tasks than the original sampling-based alignment approach. Furthermore, the translation quality obtained by merging phrase translation tables computed from the sampling-based alignment method and from MGIZA++ is examined.