 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Medical Vision-Language Models with Explicit Visual Prompts: Framework Design and Comprehensive Exploration of Prompt Variations
Jan 04, 2025



With the recent advancements in vision-language models (VLMs) driven by large language models (LLMs), many researchers have focused on models that comprised of an image encoder, an image-to-language projection layer, and a text decoder architectures, leading to the emergence of works like LLava-Med. However, these works primarily operate at the whole-image level, aligning general information from 2D medical images without attending to finer details. As a result, these models often provide irrelevant or non-clinically valuable information while missing critical details. Medical vision-language tasks differ significantly from general images, particularly in their focus on fine-grained details, while excluding irrelevant content. General domain VLMs tend to prioritize global information due to their design, which compresses the entire image into a multi-token representation that is passed into the LLM decoder. Therefore, current VLMs all lack the capability to restrict their attention to particular areas. To address this critical issue in the medical domain, we introduce MedVP, an visual prompt generation and fine-tuning framework, which involves extract medical entities, generate visual prompts, and adapt datasets for visual prompt guided fine-tuning. To the best of our knowledge, this is the first work to explicitly introduce visual prompt into medical VLMs, and we successfully outperform recent state-of-the-art large models across multiple medical VQA datasets. Extensive experiments are conducted to analyze the impact of different visual prompt forms and how they contribute to performance improvement. The results demonstrate both the effectiveness and clinical significance of our approach
MMedPO: Aligning Medical Vision-Language Models with Clinical-Aware Multimodal Preference Optimization
Dec 09, 2024



The advancement of Large Vision-Language Models (LVLMs) has propelled their application in the medical field. However, Medical LVLMs (Med-LVLMs) encounter factuality challenges due to modality misalignment, where the models prioritize textual knowledge over visual input, leading to hallucinations that contradict information in medical images. Previous attempts to enhance modality alignment in Med-LVLMs through preference optimization have inadequately mitigated clinical relevance in preference data, making these samples easily distinguishable and reducing alignment effectiveness. To address this challenge, we propose MMedPO, a novel multimodal medical preference optimization approach that considers the clinical relevance of preference samples to enhance Med-LVLM alignment. MMedPO curates multimodal preference data by introducing two types of dispreference: (1) plausible hallucinations injected through target Med-LVLMs or GPT-4o to produce medically inaccurate responses, and (2) lesion region neglect achieved through local lesion-noising, disrupting visual understanding of critical areas. We then calculate clinical relevance for each sample based on scores from multiple Med-LLMs and visual tools, and integrate these scores into the preference optimization process as weights, enabling effective alignment. Our experiments demonstrate that MMedPO significantly enhances factual accuracy in Med-LVLMs, achieving substantial improvements over existing preference optimization methods by averaging 14.2% and 51.7% across the Med-VQA and report generation tasks. Our code are available in https://github.com/aiming-lab/MMedPO.
MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models
Oct 16, 2024



Artificial Intelligence (AI) has demonstrated significant potential in healthcare, particularly in disease diagnosis and treatment planning. Recent progress in Medical Large Vision-Language Models (Med-LVLMs) has opened up new possibilities for interactive diagnostic tools. However, these models often suffer from factual hallucination, which can lead to incorrect diagnoses. Fine-tuning and retrieval-augmented generation (RAG) have emerged as methods to address these issues. However, the amount of high-quality data and distribution shifts between training data and deployment data limit the application of fine-tuning methods. Although RAG is lightweight and effective, existing RAG-based approaches are not sufficiently general to different medical domains and can potentially cause misalignment issues, both between modalities and between the model and the ground truth. In this paper, we propose a versatile multimodal RAG system, MMed-RAG, designed to enhance the factuality of Med-LVLMs. Our approach introduces a domain-aware retrieval mechanism, an adaptive retrieved contexts selection method, and a provable RAG-based preference fine-tuning strategy. These innovations make the RAG process sufficiently general and reliable, significantly improving alignment when introducing retrieved contexts. Experimental results across five medical datasets (involving radiology, ophthalmology, pathology) on medical VQA and report generation demonstrate that MMed-RAG can achieve an average improvement of 43.8% in the factual accuracy of Med-LVLMs. Our data and code are available in https://github.com/richard-peng-xia/MMed-RAG.
RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models
Jul 06, 2024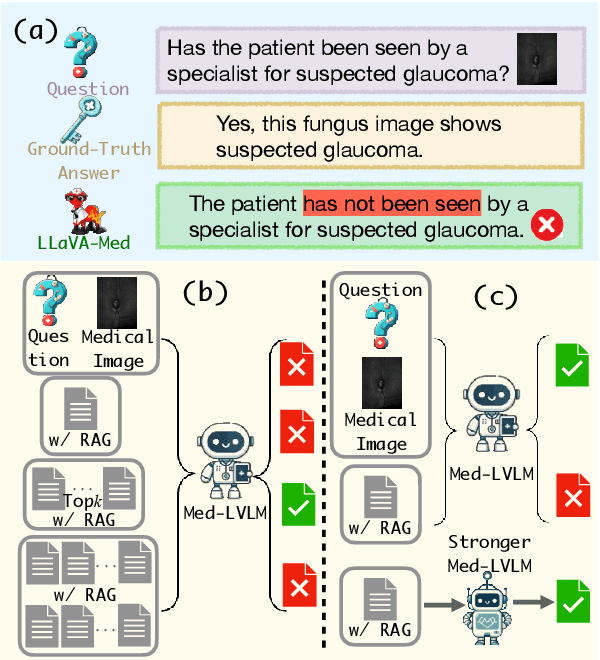



The recent emergence of Medical Large Vision Language Models (Med-LVLMs) has enhanced medical diagnosis. However, current Med-LVLMs frequently encounter factual issues, often generating responses that do not align with established medical facts. Retrieval-Augmented Generation (RAG), which utilizes external knowledge, can improve the factual accuracy of these models but introduces two major challenges. First, limited retrieved contexts might not cover all necessary information, while excessive retrieval can introduce irrelevant and inaccurate references, interfering with the model's generation. Second, in cases where the model originally responds correctly, applying RAG can lead to an over-reliance on retrieved contexts, resulting in incorrect answers. To address these issues, we propose RULE, which consists of two components. First, we introduce a provably effective strategy for controlling factuality risk through the calibrated selection of the number of retrieved contexts. Second, based on samples where over-reliance on retrieved contexts led to errors, we curate a preference dataset to fine-tune the model, balancing its dependence on inherent knowledge and retrieved contexts for generation. We demonstrate the effectiveness of RULE on three medical VQA datasets, achieving an average improvement of 20.8% in factual accuracy. We publicly release our benchmark and code in https://github.com/richard-peng-xia/RULE.
CARES: A Comprehensive Benchmark of Trustworthiness in Medical Vision Language Models
Jun 10, 2024
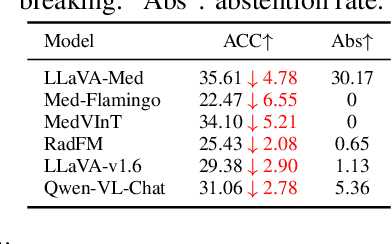
Artificial intelligence has significantly impacted medical applications, particularly with the advent of Medical Large Vision Language Models (Med-LVLMs), sparking optimism for the future of automated and personalized healthcare. However, the trustworthiness of Med-LVLMs remains unverified, posing significant risks for future model deployment. In this paper, we introduce CARES and aim to comprehensively evaluate the Trustworthiness of Med-LVLMs across the medical domain. We assess the trustworthiness of Med-LVLMs across five dimensions, including trustfulness, fairness, safety, privacy, and robustness. CARES comprises about 41K question-answer pairs in both closed and open-ended formats, covering 16 medical image modalities and 27 anatomical regions. Our analysis reveals that the models consistently exhibit concerns regarding trustworthiness, often displaying factual inaccuracies and failing to maintain fairness across different demographic groups. Furthermore, they are vulnerable to attacks and demonstrate a lack of privacy awareness. We publicly release our benchmark and code in https://github.com/richard-peng-xia/CARES.