 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedLoc-R1: Performance-Aware Curriculum Reward Scheduling for GRPO-Based Medical Visual Grounding
Mar 30, 2026Medical visual grounding serves as a crucial foundation for fine-grained multimodal reasoning and interpretable clinical decision support. Despite recent advances in reinforcement learning (RL) for grounding tasks, existing approaches such as Group Relative Policy Optimization~(GRPO) suffer from severe reward sparsity when directly applied to medical images, primarily due to the inherent difficulty of localizing small or ambiguous regions of interest, which is further exacerbated by the rigid and suboptimal nature of fixed IoU-based reward schemes in RL. This leads to vanishing policy gradients and stagnated optimization, particularly during early training. To address this challenge, we propose MedLoc-R1, a performance-aware reward scheduling framework that progressively tightens the reward criterion in accordance with model readiness. MedLoc-R1 introduces a sliding-window performance tracker and a multi-condition update rule that automatically adjust the reward schedule from dense, easily obtainable signals to stricter, fine-grained localization requirements, while preserving the favorable properties of GRPO without introducing auxiliary networks or additional gradient paths. Experiments on three medical visual grounding benchmarks demonstrate that MedLoc-R1 consistently improves both localization accuracy and training stability over GRPO-based baselines. Our framework offers a general, lightweight, and effective solution for RL-based grounding in high-stakes medical applications. Code \& checkpoints are available at \hyperlink{}{https://github.com/MembrAI/MedLoc-R1}.
Improving Medical Visual Reinforcement Fine-Tuning via Perception and Reasoning Augmentation
Feb 11, 2026While recent advances in Reinforcement Fine-Tuning (RFT) have shown that rule-based reward schemes can enable effective post-training for large language models, their extension to cross-modal, vision-centric domains remains largely underexplored. This limitation is especially pronounced in the medical imaging domain, where effective performance requires both robust visual perception and structured reasoning. In this work, we address this gap by proposing VRFT-Aug, a visual reinforcement fine-tuning framework tailored for the medical domain. VRFT-Aug introduces a series of training strategies designed to augment both perception and reasoning, including prior knowledge injection, perception-driven policy refinement, medically informed reward shaping, and behavioral imitation. Together, these methods aim to stabilize and improve the RFT process. Through extensive experiments across multiple medical datasets, we show that our approaches consistently outperform both standard supervised fine-tuning and RFT baselines. Moreover, we provide empirically grounded insights and practical training heuristics that can be generalized to other medical image tasks. We hope this work contributes actionable guidance and fresh inspiration for the ongoing effort to develop reliable, reasoning-capable models for high-stakes medical applications.
Guiding Medical Vision-Language Models with Explicit Visual Prompts: Framework Design and Comprehensive Exploration of Prompt Variations
Jan 04, 2025



With the recent advancements in vision-language models (VLMs) driven by large language models (LLMs), many researchers have focused on models that comprised of an image encoder, an image-to-language projection layer, and a text decoder architectures, leading to the emergence of works like LLava-Med. However, these works primarily operate at the whole-image level, aligning general information from 2D medical images without attending to finer details. As a result, these models often provide irrelevant or non-clinically valuable information while missing critical details. Medical vision-language tasks differ significantly from general images, particularly in their focus on fine-grained details, while excluding irrelevant content. General domain VLMs tend to prioritize global information due to their design, which compresses the entire image into a multi-token representation that is passed into the LLM decoder. Therefore, current VLMs all lack the capability to restrict their attention to particular areas. To address this critical issue in the medical domain, we introduce MedVP, an visual prompt generation and fine-tuning framework, which involves extract medical entities, generate visual prompts, and adapt datasets for visual prompt guided fine-tuning. To the best of our knowledge, this is the first work to explicitly introduce visual prompt into medical VLMs, and we successfully outperform recent state-of-the-art large models across multiple medical VQA datasets. Extensive experiments are conducted to analyze the impact of different visual prompt forms and how they contribute to performance improvement. The results demonstrate both the effectiveness and clinical significance of our approach
Towards Explaining Uncertainty Estimates in Point Cloud Registration
Dec 29, 2024Iterative Closest Point (ICP) is a commonly used algorithm to estimate transformation between two point clouds. The key idea of this work is to leverage recent advances in explainable AI for probabilistic ICP methods that provide uncertainty estimates. Concretely, we propose a method that can explain why a probabilistic ICP method produced a particular output. Our method is based on kernel SHAP (SHapley Additive exPlanations). With this, we assign an importance value to common sources of uncertainty in ICP such as sensor noise, occlusion, and ambiguous environments. The results of the experiment show that this explanation method can reasonably explain the uncertainty sources, providing a step towards robots that know when and why they failed in a human interpretable manner
Evaluating Hallucination in Text-to-Image Diffusion Models with Scene-Graph based Question-Answering Agent
Dec 07, 2024



Contemporary Text-to-Image (T2I) models frequently depend on qualitative human evaluations to assess the consistency between synthesized images and the text prompts. There is a demand for quantitative and automatic evaluation tools, given that human evaluation lacks reproducibility. We believe that an effective T2I evaluation metric should accomplish the following: detect instances where the generated images do not align with the textual prompts, a discrepancy we define as the `hallucination problem' in T2I tasks; record the types and frequency of hallucination issues, aiding users in understanding the causes of errors; and provide a comprehensive and intuitive scoring that close to human standard. To achieve these objectives, we propose a method based on large language models (LLMs) for conducting question-answering with an extracted scene-graph and created a dataset with human-rated scores for generated images. From the methodology perspective, we combine knowledge-enhanced question-answering tasks with image evaluation tasks, making the evaluation metrics more controllable and easier to interpret. For the contribution on the dataset side, we generated 12,000 synthesized images based on 1,000 composited prompts using three advanced T2I models. Subsequently, we conduct human scoring on all synthesized images and prompt pairs to validate the accuracy and effectiveness of our method as an evaluation metric. All generated images and the human-labeled scores will be made publicly available in the future to facilitate ongoing research on this crucial issue. Extensive experiments show that our method aligns more closely with human scoring patterns than other evaluation metrics.
EEG-DIF: Early Warning of Epileptic Seizures through Generative Diffusion Model-based Multi-channel EEG Signals Forecasting
Oct 22, 2024



Multi-channel EEG signals are commonly used for the diagnosis and assessment of diseases such as epilepsy. Currently, various EEG diagnostic algorithms based on deep learning have been developed. However, most research efforts focus solely on diagnosing and classifying current signal data but do not consider the prediction of future trends for early warning. Additionally, since multi-channel EEG can be essentially regarded as the spatio-temporal signal data received by detectors at different locations in the brain, how to construct spatio-temporal information representations of EEG signals to facilitate future trend prediction for multi-channel EEG becomes an important problem. This study proposes a multi-signal prediction algorithm based on generative diffusion models (EEG-DIF), which transforms the multi-signal forecasting task into an image completion task, allowing for comprehensive representation and learning of the spatio-temporal correlations and future developmental patterns of multi-channel EEG signals. Here, we employ a publicly available epilepsy EEG dataset to construct and validate the EEG-DIF. The results demonstrate that our method can accurately predict future trends for multi-channel EEG signals simultaneously. Furthermore, the early warning accuracy for epilepsy seizures based on the generated EEG data reaches 0.89. In general, EEG-DIF provides a novel approach for characterizing multi-channel EEG signals and an innovative early warning algorithm for epilepsy seizures, aiding in optimizing and enhancing the clinical diagnosis process. The code is available at https://github.com/JZK00/EEG-DIF.
TARGO: Benchmarking Target-driven Object Grasping under Occlusions
Jul 08, 2024Recent advances in predicting 6D grasp poses from a single depth image have led to promising performance in robotic grasping. However, previous grasping models face challenges in cluttered environments where nearby objects impact the target object's grasp. In this paper, we first establish a new benchmark dataset for TARget-driven Grasping under Occlusions, named TARGO. We make the following contributions: 1) We are the first to study the occlusion level of grasping. 2) We set up an evaluation benchmark consisting of large-scale synthetic data and part of real-world data, and we evaluated five grasp models and found that even the current SOTA model suffers when the occlusion level increases, leaving grasping under occlusion still a challenge. 3) We also generate a large-scale training dataset via a scalable pipeline, which can be used to boost the performance of grasping under occlusion and generalized to the real world. 4) We further propose a transformer-based grasping model involving a shape completion module, termed TARGO-Net, which performs most robustly as occlusion increases. Our benchmark dataset can be found at https://TARGO-benchmark.github.io/.
Increasing SAM Zero-Shot Performance on Multimodal Medical Images Using GPT-4 Generated Descriptive Prompts Without Human Annotation
Feb 24, 2024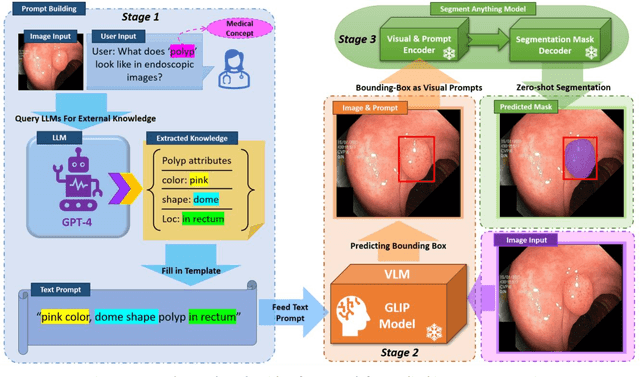
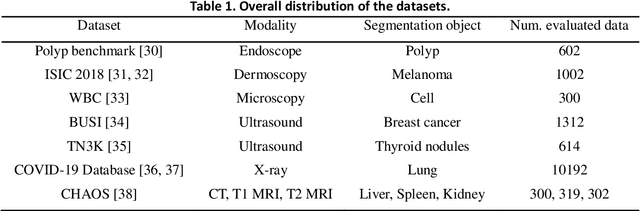
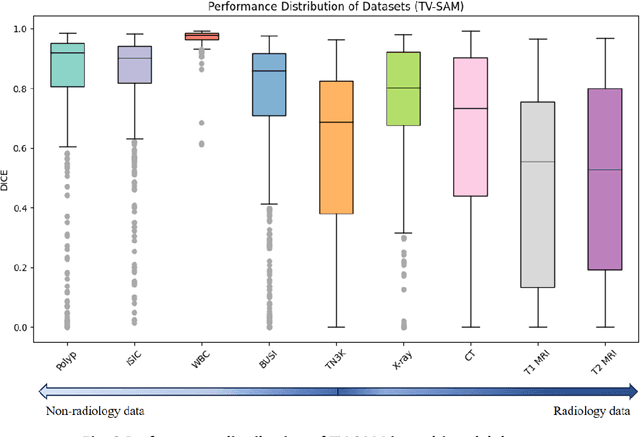
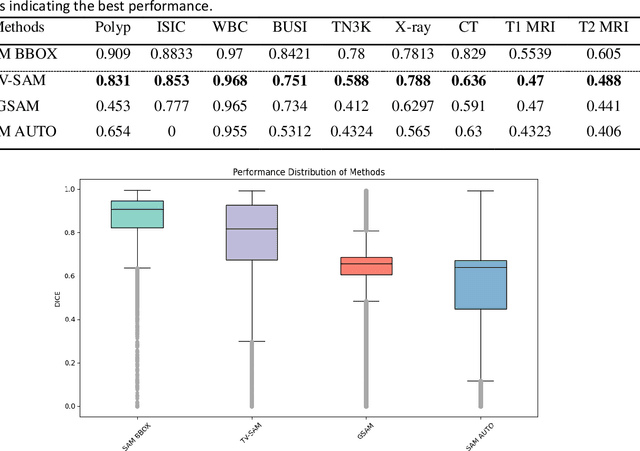
This study develops and evaluates a novel multimodal medical image zero-shot segmentation algorithm named Text-Visual-Prompt SAM (TV-SAM) without any manual annotations. TV-SAM incorporates and integrates large language model GPT-4, Vision Language Model GLIP, and Segment Anything Model (SAM), to autonomously generate descriptive text prompts and visual bounding box prompts from medical images, thereby enhancing SAM for zero-shot segmentation. Comprehensive evaluations are implemented on seven public datasets encompassing eight imaging modalities to demonstrate that TV-SAM can effectively segment unseen targets across various modalities without additional training, significantly outperforming SAM AUTO and GSAM, closely matching the performance of SAM BBOX with gold standard bounding box prompts, and surpassing the state-of-the-art on specific datasets like ISIC and WBC. The study indicates that TV-SAM serves as an effective multimodal medical image zero-shot segmentation algorithm, highlighting the significant contribution of GPT-4 to zero-shot segmentation. By integrating foundational models such as GPT-4, GLIP, and SAM, it could enhance the capability to address complex problems in specialized domains. The code is available at: https://github.com/JZK00/TV-SAM.
Edge Generation Scheduling for DAG Tasks using Deep Reinforcement Learning
Aug 28, 2023



Directed acyclic graph (DAG) tasks are currently adopted in the real-time domain to model complex applications from the automotive, avionics, and industrial domain that implement their functionalities through chains of intercommunicating tasks. This paper studies the problem of scheduling real-time DAG tasks by presenting a novel schedulability test based on the concept of trivial schedulability. Using this schedulability test, we propose a new DAG scheduling framework (edge generation scheduling -- EGS) that attempts to minimize the DAG width by iteratively generating edges while guaranteeing the deadline constraint. We study how to efficiently solve the problem of generating edges by developing a deep reinforcement learning algorithm combined with a graph representation neural network to learn an efficient edge generation policy for EGS. We evaluate the effectiveness of the proposed algorithm by comparing it with state-of-the-art DAG scheduling heuristics and an optimal mixed-integer linear programming baseline. Experimental results show that the proposed algorithm outperforms the state-of-the-art by requiring fewer processors to schedule the same DAG tasks.
ConES: Concept Embedding Search for Parameter Efficient Tuning Large Vision Language Models
May 30, 2023



Large pre-trained vision-language models have shown great prominence in transferring pre-acquired knowledge to various domains and downstream tasks with appropriate prompting or tuning. Existing prevalent tuning methods can be generally categorized into three genres: 1) prompt engineering by creating suitable prompt texts, which is time-consuming and requires domain expertise; 2) or simply fine-tuning the whole model, which is extremely inefficient; 3) prompt tuning through parameterized prompt embeddings with the text encoder. Nevertheless, all methods rely on the text encoder for bridging the modality gap between vision and language. In this work, we question the necessity of the cumbersome text encoder for a more lightweight and efficient tuning paradigm as well as more representative prompt embeddings closer to the image representations. To achieve this, we propose a Concept Embedding Search (ConES) approach by optimizing prompt embeddings -- without the need of the text encoder -- to capture the 'concept' of the image modality through a variety of task objectives. By dropping the text encoder, we are able to significantly speed up the learning process, \eg, from about an hour to just ten minutes in our experiments for personalized text-to-image generation without impairing the generation quality. Moreover, our proposed approach is orthogonal to current existing tuning methods since the searched concept embeddings can be further utilized in the next stage of fine-tuning the pre-trained large models for boosting performance. Extensive experiments show that our approach can beat the prompt tuning and textual inversion methods in a variety of downstream tasks including objection detection, instance segmentation, and image generation. Our approach also shows better generalization capability for unseen concepts in specialized domains, such as the medical domain.