 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing SAM Zero-Shot Performance on Multimodal Medical Images Using GPT-4 Generated Descriptive Prompts Without Human Annotation
Paper and Code
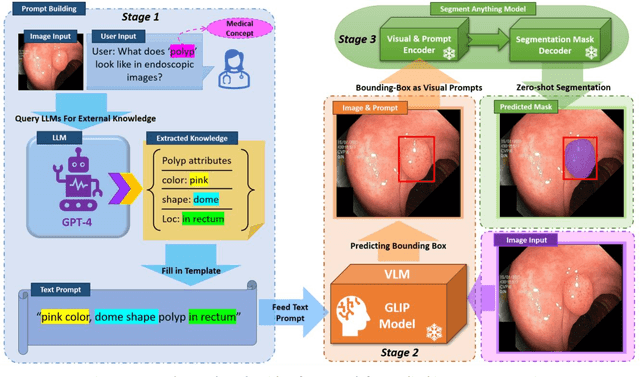
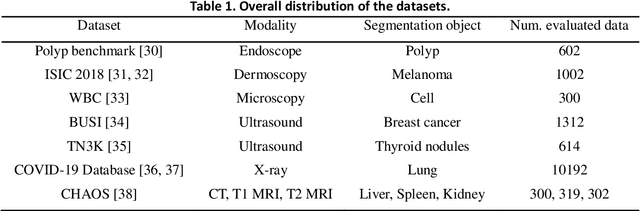
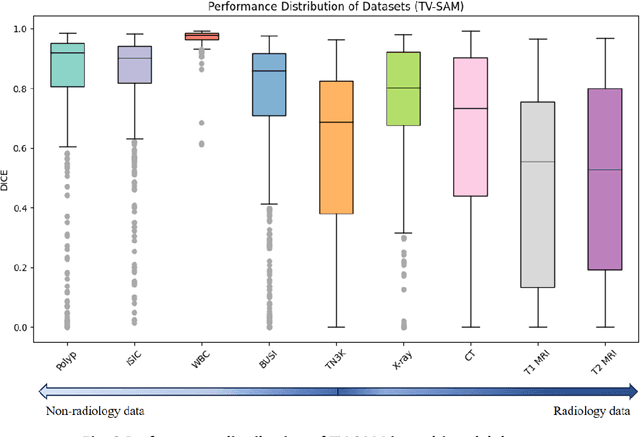
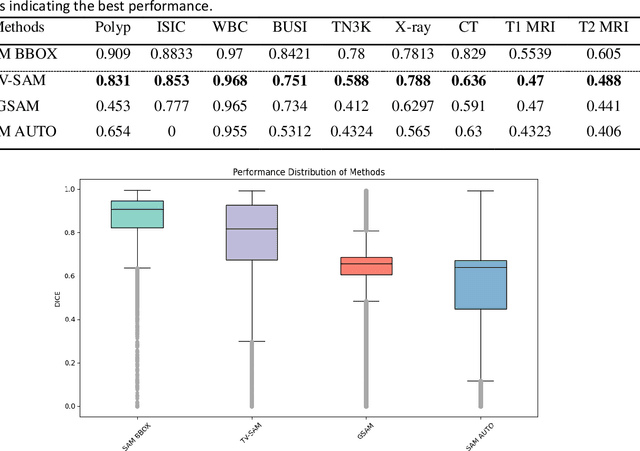
This study develops and evaluates a novel multimodal medical image zero-shot segmentation algorithm named Text-Visual-Prompt SAM (TV-SAM) without any manual annotations. TV-SAM incorporates and integrates large language model GPT-4, Vision Language Model GLIP, and Segment Anything Model (SAM), to autonomously generate descriptive text prompts and visual bounding box prompts from medical images, thereby enhancing SAM for zero-shot segmentation. Comprehensive evaluations are implemented on seven public datasets encompassing eight imaging modalities to demonstrate that TV-SAM can effectively segment unseen targets across various modalities without additional training, significantly outperforming SAM AUTO and GSAM, closely matching the performance of SAM BBOX with gold standard bounding box prompts, and surpassing the state-of-the-art on specific datasets like ISIC and WBC. The study indicates that TV-SAM serves as an effective multimodal medical image zero-shot segmentation algorithm, highlighting the significant contribution of GPT-4 to zero-shot segmentation. By integrating foundational models such as GPT-4, GLIP, and SAM, it could enhance the capability to address complex problems in specialized domains. The code is available at: https://github.com/JZK00/TV-SAM.