 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-Omni: A Unified Autoregressive Model for Any-to-Any Generation
Jan 25, 2026Real-world perception and interaction are inherently multimodal, encompassing not only language but also vision and speech, which motivates the development of "Omni" MLLMs that support both multimodal inputs and multimodal outputs. While a sequence of omni MLLMs has emerged, most existing systems still rely on additional expert components to achieve multimodal generation, limiting the simplicity of unified training and inference. Autoregressive (AR) modeling, with a single token stream, a single next-token objective, and a single decoder, is an elegant and scalable foundation in the text domain. Motivated by this, we present AR-Omni, a unified any-to-any model in the autoregressive paradigm without any expert decoders. AR-Omni supports autoregressive text and image generation, as well as streaming speech generation, all under a single Transformer decoder. We further address three practical issues in unified AR modeling: modality imbalance via task-aware loss reweighting, visual fidelity via a lightweight token-level perceptual alignment loss for image tokens, and stability-creativity trade-offs via a finite-state decoding mechanism. Empirically, AR-Omni achieves strong quality across three modalities while remaining real-time, achieving a 0.88 real-time factor for speech generation.
Omni-R1: Towards the Unified Generative Paradigm for Multimodal Reasoning
Jan 14, 2026Multimodal Large Language Models (MLLMs) are making significant progress in multimodal reasoning. Early approaches focus on pure text-based reasoning. More recent studies have incorporated multimodal information into the reasoning steps; however, they often follow a single task-specific reasoning pattern, which limits their generalizability across various multimodal tasks. In fact, there are numerous multimodal tasks requiring diverse reasoning skills, such as zooming in on a specific region or marking an object within an image. To address this, we propose unified generative multimodal reasoning, which unifies diverse multimodal reasoning skills by generating intermediate images during the reasoning process. We instantiate this paradigm with Omni-R1, a two-stage SFT+RL framework featuring perception alignment loss and perception reward, thereby enabling functional image generation. Additionally, we introduce Omni-R1-Zero, which eliminates the need for multimodal annotations by bootstrapping step-wise visualizations from text-only reasoning data. Empirical results show that Omni-R1 achieves unified generative reasoning across a wide range of multimodal tasks, and Omni-R1-Zero can match or even surpass Omni-R1 on average, suggesting a promising direction for generative multimodal reasoning.
Evaluating Hallucination in Text-to-Image Diffusion Models with Scene-Graph based Question-Answering Agent
Dec 07, 2024



Contemporary Text-to-Image (T2I) models frequently depend on qualitative human evaluations to assess the consistency between synthesized images and the text prompts. There is a demand for quantitative and automatic evaluation tools, given that human evaluation lacks reproducibility. We believe that an effective T2I evaluation metric should accomplish the following: detect instances where the generated images do not align with the textual prompts, a discrepancy we define as the `hallucination problem' in T2I tasks; record the types and frequency of hallucination issues, aiding users in understanding the causes of errors; and provide a comprehensive and intuitive scoring that close to human standard. To achieve these objectives, we propose a method based on large language models (LLMs) for conducting question-answering with an extracted scene-graph and created a dataset with human-rated scores for generated images. From the methodology perspective, we combine knowledge-enhanced question-answering tasks with image evaluation tasks, making the evaluation metrics more controllable and easier to interpret. For the contribution on the dataset side, we generated 12,000 synthesized images based on 1,000 composited prompts using three advanced T2I models. Subsequently, we conduct human scoring on all synthesized images and prompt pairs to validate the accuracy and effectiveness of our method as an evaluation metric. All generated images and the human-labeled scores will be made publicly available in the future to facilitate ongoing research on this crucial issue. Extensive experiments show that our method aligns more closely with human scoring patterns than other evaluation metrics.
Calibrated Self-Rewarding Vision Language Models
May 23, 2024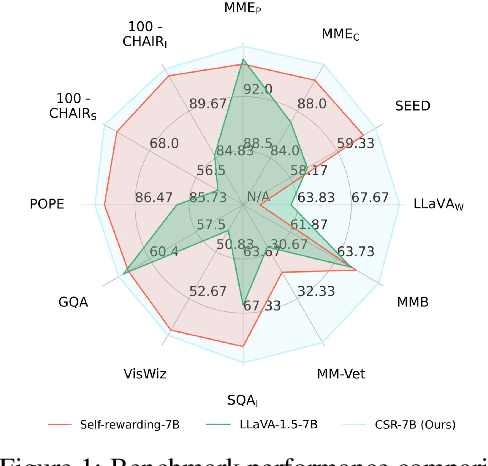
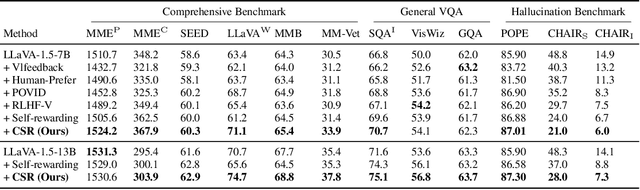
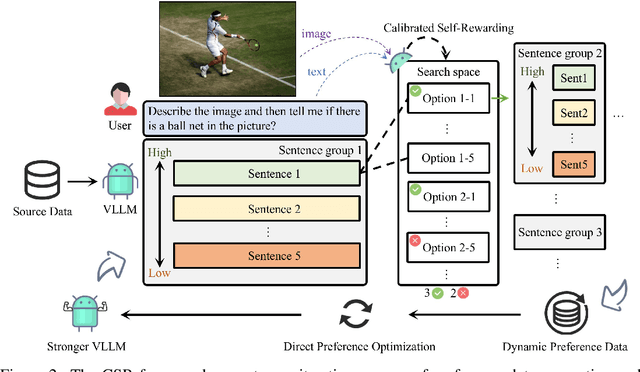
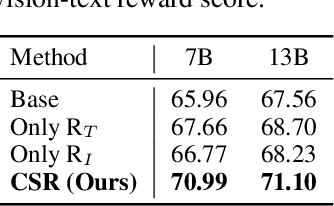
Large Vision-Language Models (LVLMs) have made substantial progress by integrating pre-trained large language models (LLMs) and vision models through instruction tuning. Despite these advancements, LVLMs often exhibit the hallucination phenomenon, where generated text responses appear linguistically plausible but contradict the input image, indicating a misalignment between image and text pairs. This misalignment arises because the model tends to prioritize textual information over visual input, even when both the language model and visual representations are of high quality. Existing methods leverage additional models or human annotations to curate preference data and enhance modality alignment through preference optimization. These approaches may not effectively reflect the target LVLM's preferences, making the curated preferences easily distinguishable. Our work addresses these challenges by proposing the Calibrated Self-Rewarding (CSR) approach, which enables the model to self-improve by iteratively generating candidate responses, evaluating the reward for each response, and curating preference data for fine-tuning. In the reward modeling, we employ a step-wise strategy and incorporate visual constraints into the self-rewarding process to place greater emphasis on visual input. Empirical results demonstrate that CSR enhances performance and reduces hallucinations across ten benchmarks and tasks, achieving substantial improvements over existing methods by 7.62%. Our empirical results are further supported by rigorous theoretical analysis, under mild assumptions, verifying the effectiveness of introducing visual constraints into the self-rewarding paradigm. Additionally, CSR shows compatibility with different vision-language models and the ability to incrementally improve performance through iterative fine-tuning. Our data and code are available at https://github.com/YiyangZhou/CSR.
Increasing SAM Zero-Shot Performance on Multimodal Medical Images Using GPT-4 Generated Descriptive Prompts Without Human Annotation
Feb 24, 2024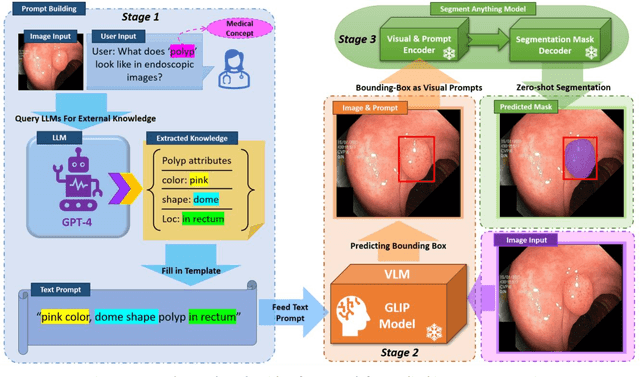
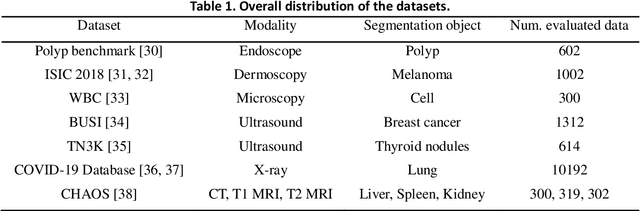
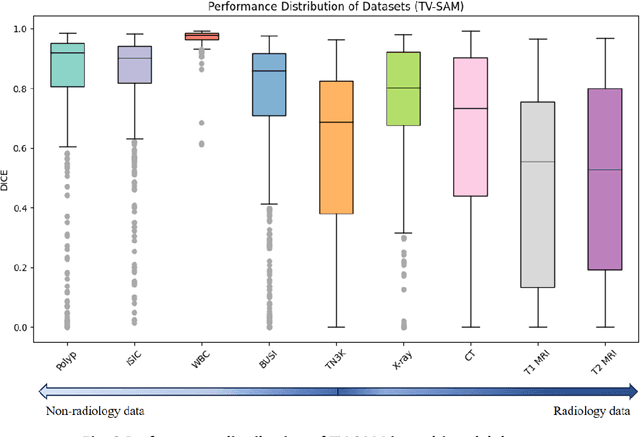
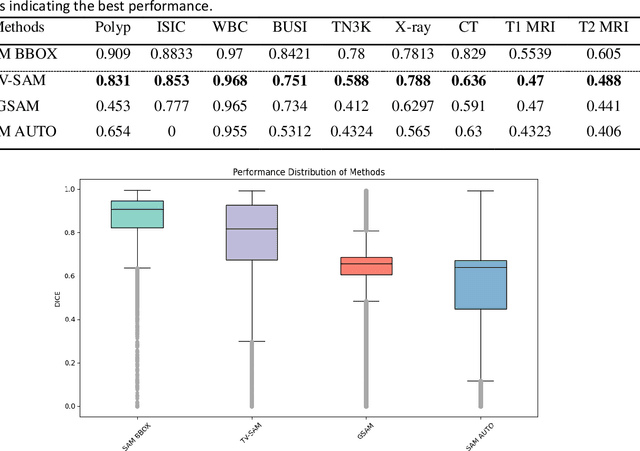
This study develops and evaluates a novel multimodal medical image zero-shot segmentation algorithm named Text-Visual-Prompt SAM (TV-SAM) without any manual annotations. TV-SAM incorporates and integrates large language model GPT-4, Vision Language Model GLIP, and Segment Anything Model (SAM), to autonomously generate descriptive text prompts and visual bounding box prompts from medical images, thereby enhancing SAM for zero-shot segmentation. Comprehensive evaluations are implemented on seven public datasets encompassing eight imaging modalities to demonstrate that TV-SAM can effectively segment unseen targets across various modalities without additional training, significantly outperforming SAM AUTO and GSAM, closely matching the performance of SAM BBOX with gold standard bounding box prompts, and surpassing the state-of-the-art on specific datasets like ISIC and WBC. The study indicates that TV-SAM serves as an effective multimodal medical image zero-shot segmentation algorithm, highlighting the significant contribution of GPT-4 to zero-shot segmentation. By integrating foundational models such as GPT-4, GLIP, and SAM, it could enhance the capability to address complex problems in specialized domains. The code is available at: https://github.com/JZK00/TV-SAM.
SAM on Medical Images: A Comprehensive Study on Three Prompt Modes
Apr 28, 2023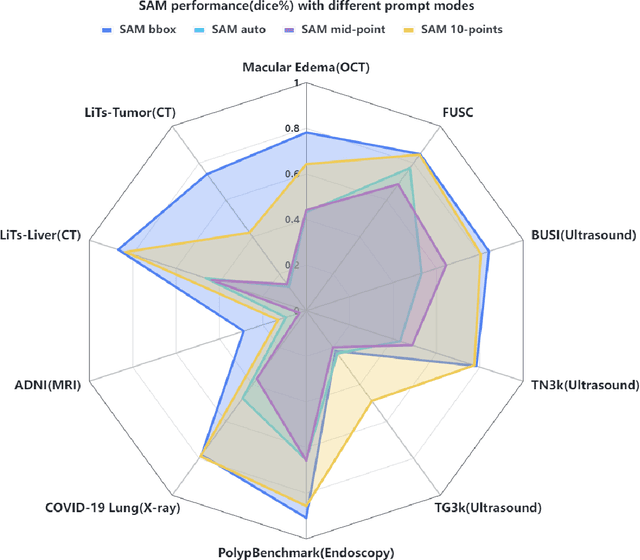
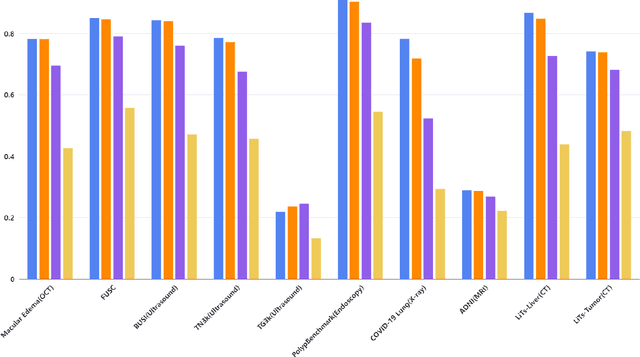
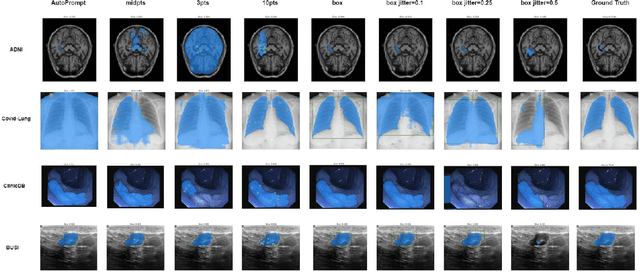

The Segment Anything Model (SAM) made an eye-catching debut recently and inspired many researchers to explore its potential and limitation in terms of zero-shot generalization capability. As the first promptable foundation model for segmentation tasks, it was trained on a large dataset with an unprecedented number of images and annotations. This large-scale dataset and its promptable nature endow the model with strong zero-shot generalization. Although the SAM has shown competitive performance on several datasets, we still want to investigate its zero-shot generalization on medical images. As we know, the acquisition of medical image annotation usually requires a lot of effort from professional practitioners. Therefore, if there exists a foundation model that can give high-quality mask prediction simply based on a few point prompts, this model will undoubtedly become the game changer for medical image analysis. To evaluate whether SAM has the potential to become the foundation model for medical image segmentation tasks, we collected more than 12 public medical image datasets that cover various organs and modalities. We also explore what kind of prompt can lead to the best zero-shot performance with different modalities. Furthermore, we find that a pattern shows that the perturbation of the box size will significantly change the prediction accuracy. Finally, Extensive experiments show that the predicted mask quality varied a lot among different datasets. And providing proper prompts, such as bounding boxes, to the SAM will significantly increase its performance.