 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM on Medical Images: A Comprehensive Study on Three Prompt Modes
Paper and Code
Apr 28, 2023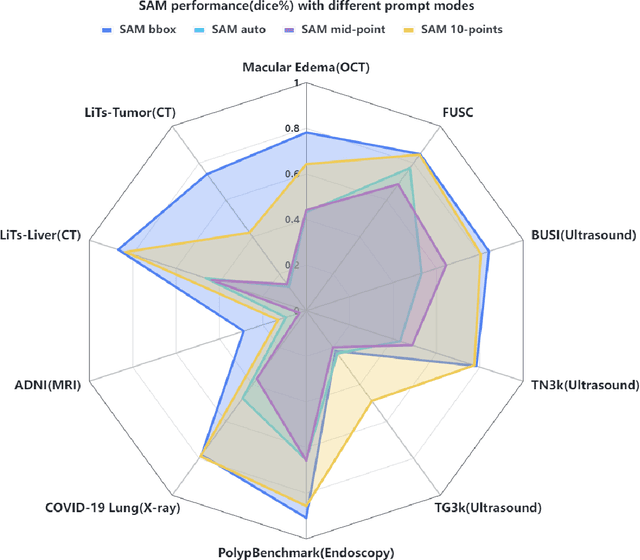
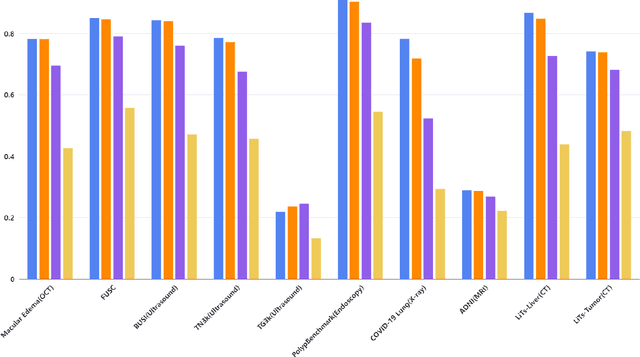
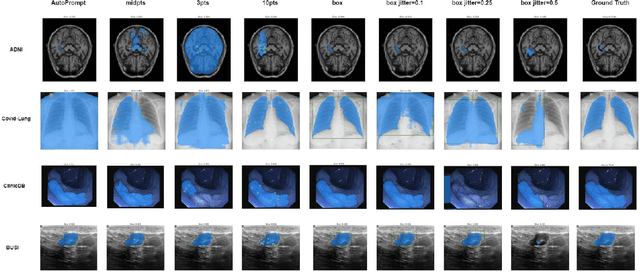

The Segment Anything Model (SAM) made an eye-catching debut recently and inspired many researchers to explore its potential and limitation in terms of zero-shot generalization capability. As the first promptable foundation model for segmentation tasks, it was trained on a large dataset with an unprecedented number of images and annotations. This large-scale dataset and its promptable nature endow the model with strong zero-shot generalization. Although the SAM has shown competitive performance on several datasets, we still want to investigate its zero-shot generalization on medical images. As we know, the acquisition of medical image annotation usually requires a lot of effort from professional practitioners. Therefore, if there exists a foundation model that can give high-quality mask prediction simply based on a few point prompts, this model will undoubtedly become the game changer for medical image analysis. To evaluate whether SAM has the potential to become the foundation model for medical image segmentation tasks, we collected more than 12 public medical image datasets that cover various organs and modalities. We also explore what kind of prompt can lead to the best zero-shot performance with different modalities. Furthermore, we find that a pattern shows that the perturbation of the box size will significantly change the prediction accuracy. Finally, Extensive experiments show that the predicted mask quality varied a lot among different datasets. And providing proper prompts, such as bounding boxes, to the SAM will significantly increase its performance.