 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedLoc-R1: Performance-Aware Curriculum Reward Scheduling for GRPO-Based Medical Visual Grounding
Mar 30, 2026Medical visual grounding serves as a crucial foundation for fine-grained multimodal reasoning and interpretable clinical decision support. Despite recent advances in reinforcement learning (RL) for grounding tasks, existing approaches such as Group Relative Policy Optimization~(GRPO) suffer from severe reward sparsity when directly applied to medical images, primarily due to the inherent difficulty of localizing small or ambiguous regions of interest, which is further exacerbated by the rigid and suboptimal nature of fixed IoU-based reward schemes in RL. This leads to vanishing policy gradients and stagnated optimization, particularly during early training. To address this challenge, we propose MedLoc-R1, a performance-aware reward scheduling framework that progressively tightens the reward criterion in accordance with model readiness. MedLoc-R1 introduces a sliding-window performance tracker and a multi-condition update rule that automatically adjust the reward schedule from dense, easily obtainable signals to stricter, fine-grained localization requirements, while preserving the favorable properties of GRPO without introducing auxiliary networks or additional gradient paths. Experiments on three medical visual grounding benchmarks demonstrate that MedLoc-R1 consistently improves both localization accuracy and training stability over GRPO-based baselines. Our framework offers a general, lightweight, and effective solution for RL-based grounding in high-stakes medical applications. Code \& checkpoints are available at \hyperlink{}{https://github.com/MembrAI/MedLoc-R1}.
Stabilized Fine-Tuning with LoRA in Federated Learning: Mitigating the Side Effect of Client Size and Rank via the Scaling Factor
Mar 09, 2026Large Language Models (LLMs) are pivotal in natural language processing. The impracticality of full fine-tuning has prompted Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA), optimizing low-rank matrices A and B. In distributed scenarios where privacy constraints necessitate Federated Learning (FL), however, the integration of LoRA is often unstable. Specifically, we identify that aggregating updates from multiple clients introduces statistical variance that scales with the client count, causing gradient collapse when using high-rank adapters. Existing scaling factor candidates, such as the one used by Rank-Stabilized LoRA, ignore the interaction caused by the aggregation process. To bridge this gap, this paper introduces Stabilized Federated LoRA (SFed-LoRA), a framework that theoretically characterizes the interaction between adapter rank and federated aggregation. We derive an optimal scaling factor designed to effectively mitigate the aggregation error accumulating across N clients. By correcting the scaling mismatch inherent in previous approaches, SFed-LoRA restores the efficacy of high-rank adaptation without altering the original model architecture or increasing inference latency. Extensive experiments in diverse tasks, model architectures, and heterogeneous data distributions are conducted to validate our results. We demonstrate that SFed-LoRA prevents high-rank collapse, and achieves significantly improved stability and faster convergence compared with state-of-the-art baselines for high-rank adaptation.
When Priors Backfire: On the Vulnerability of Unlearnable Examples to Pretraining
Mar 05, 2026Unlearnable Examples (UEs) serve as a data protection strategy that generates imperceptible perturbations to mislead models into learning spurious correlations instead of underlying semantics. In this paper, we uncover a fundamental vulnerability of UEs that emerges when learning starts from a pretrained model. Crucially, our empirical analysis shows that even when data are protected by carefully crafted perturbations, pretraining priors still furnish rich semantic representations that allow the model to circumvent the shortcuts introduced by UEs and capture genuine features, thereby nullifying unlearnability. To address this, we propose BAIT (Binding Artificial perturbations to Incorrect Targets), a novel bi-level optimization formulation. Specifically, the inner level aims at associating the perturbed samples with real labels to simulate standard data-label alignment, while the outer level actively disrupts this alignment by enforcing a mislabel-perturbation binding that maps samples to designated incorrect targets. This mechanism effectively overrides the semantic guidance of priors, forcing the model to rely on the injected perturbations and consequently preventing the acquisition of true semantics. Extensive experiments on standard benchmarks and multiple pretrained backbones demonstrate that BAIT effectively mitigates the influence of pretraining priors and maintains data unlearnability.
Improving Medical Visual Reinforcement Fine-Tuning via Perception and Reasoning Augmentation
Feb 11, 2026While recent advances in Reinforcement Fine-Tuning (RFT) have shown that rule-based reward schemes can enable effective post-training for large language models, their extension to cross-modal, vision-centric domains remains largely underexplored. This limitation is especially pronounced in the medical imaging domain, where effective performance requires both robust visual perception and structured reasoning. In this work, we address this gap by proposing VRFT-Aug, a visual reinforcement fine-tuning framework tailored for the medical domain. VRFT-Aug introduces a series of training strategies designed to augment both perception and reasoning, including prior knowledge injection, perception-driven policy refinement, medically informed reward shaping, and behavioral imitation. Together, these methods aim to stabilize and improve the RFT process. Through extensive experiments across multiple medical datasets, we show that our approaches consistently outperform both standard supervised fine-tuning and RFT baselines. Moreover, we provide empirically grounded insights and practical training heuristics that can be generalized to other medical image tasks. We hope this work contributes actionable guidance and fresh inspiration for the ongoing effort to develop reliable, reasoning-capable models for high-stakes medical applications.
Voronoi-grid-based Pareto Front Learning and Its Application to Collaborative Federated Learning
May 27, 2025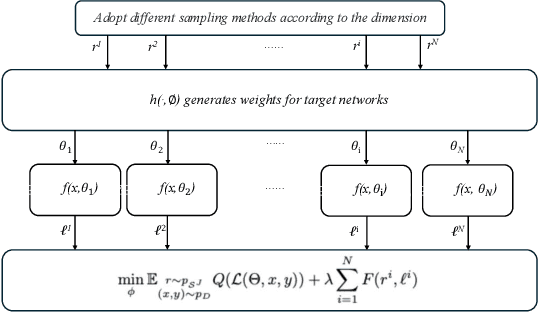
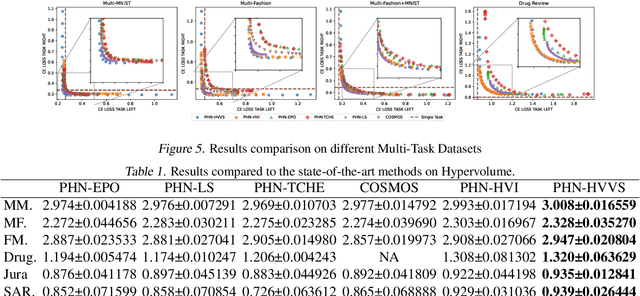
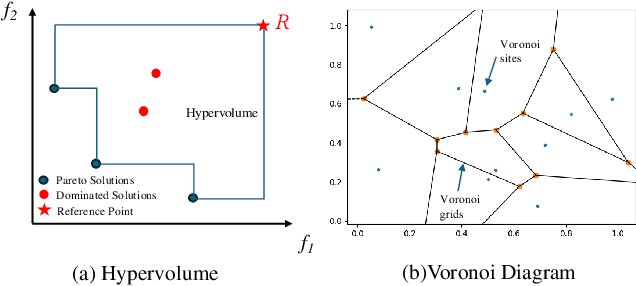
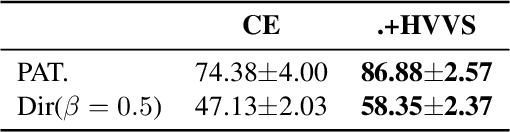
Multi-objective optimization (MOO) exists extensively in machine learning, and aims to find a set of Pareto-optimal solutions, called the Pareto front, e.g., it is fundamental for multiple avenues of research in federated learning (FL). Pareto-Front Learning (PFL) is a powerful method implemented using Hypernetworks (PHNs) to approximate the Pareto front. This method enables the acquisition of a mapping function from a given preference vector to the solutions on the Pareto front. However, most existing PFL approaches still face two challenges: (a) sampling rays in high-dimensional spaces; (b) failing to cover the entire Pareto Front which has a convex shape. Here, we introduce a novel PFL framework, called as PHN-HVVS, which decomposes the design space into Voronoi grids and deploys a genetic algorithm (GA) for Voronoi grid partitioning within high-dimensional space. We put forward a new loss function, which effectively contributes to more extensive coverage of the resultant Pareto front and maximizes the HV Indicator. Experimental results on multiple MOO machine learning tasks demonstrate that PHN-HVVS outperforms the baselines significantly in generating Pareto front. Also, we illustrate that PHN-HVVS advances the methodologies of several recent problems in the FL field. The code is available at https://github.com/buptcmm/phnhvvs}{https://github.com/buptcmm/phnhvvs.
One-to-Normal: Anomaly Personalization for Few-shot Anomaly Detection
Feb 03, 2025



Traditional Anomaly Detection (AD) methods have predominantly relied on unsupervised learning from extensive normal data. Recent AD methods have evolved with the advent of large pre-trained vision-language models, enhancing few-shot anomaly detection capabilities. However, these latest AD methods still exhibit limitations in accuracy improvement. One contributing factor is their direct comparison of a query image's features with those of few-shot normal images. This direct comparison often leads to a loss of precision and complicates the extension of these techniques to more complex domains--an area that remains underexplored in a more refined and comprehensive manner. To address these limitations, we introduce the anomaly personalization method, which performs a personalized one-to-normal transformation of query images using an anomaly-free customized generation model, ensuring close alignment with the normal manifold. Moreover, to further enhance the stability and robustness of prediction results, we propose a triplet contrastive anomaly inference strategy, which incorporates a comprehensive comparison between the query and generated anomaly-free data pool and prompt information. Extensive evaluations across eleven datasets in three domains demonstrate our model's effectiveness compared to the latest AD methods. Additionally, our method has been proven to transfer flexibly to other AD methods, with the generated image data effectively improving the performance of other AD methods.
Guiding Medical Vision-Language Models with Explicit Visual Prompts: Framework Design and Comprehensive Exploration of Prompt Variations
Jan 04, 2025



With the recent advancements in vision-language models (VLMs) driven by large language models (LLMs), many researchers have focused on models that comprised of an image encoder, an image-to-language projection layer, and a text decoder architectures, leading to the emergence of works like LLava-Med. However, these works primarily operate at the whole-image level, aligning general information from 2D medical images without attending to finer details. As a result, these models often provide irrelevant or non-clinically valuable information while missing critical details. Medical vision-language tasks differ significantly from general images, particularly in their focus on fine-grained details, while excluding irrelevant content. General domain VLMs tend to prioritize global information due to their design, which compresses the entire image into a multi-token representation that is passed into the LLM decoder. Therefore, current VLMs all lack the capability to restrict their attention to particular areas. To address this critical issue in the medical domain, we introduce MedVP, an visual prompt generation and fine-tuning framework, which involves extract medical entities, generate visual prompts, and adapt datasets for visual prompt guided fine-tuning. To the best of our knowledge, this is the first work to explicitly introduce visual prompt into medical VLMs, and we successfully outperform recent state-of-the-art large models across multiple medical VQA datasets. Extensive experiments are conducted to analyze the impact of different visual prompt forms and how they contribute to performance improvement. The results demonstrate both the effectiveness and clinical significance of our approach
Evaluating Hallucination in Text-to-Image Diffusion Models with Scene-Graph based Question-Answering Agent
Dec 07, 2024



Contemporary Text-to-Image (T2I) models frequently depend on qualitative human evaluations to assess the consistency between synthesized images and the text prompts. There is a demand for quantitative and automatic evaluation tools, given that human evaluation lacks reproducibility. We believe that an effective T2I evaluation metric should accomplish the following: detect instances where the generated images do not align with the textual prompts, a discrepancy we define as the `hallucination problem' in T2I tasks; record the types and frequency of hallucination issues, aiding users in understanding the causes of errors; and provide a comprehensive and intuitive scoring that close to human standard. To achieve these objectives, we propose a method based on large language models (LLMs) for conducting question-answering with an extracted scene-graph and created a dataset with human-rated scores for generated images. From the methodology perspective, we combine knowledge-enhanced question-answering tasks with image evaluation tasks, making the evaluation metrics more controllable and easier to interpret. For the contribution on the dataset side, we generated 12,000 synthesized images based on 1,000 composited prompts using three advanced T2I models. Subsequently, we conduct human scoring on all synthesized images and prompt pairs to validate the accuracy and effectiveness of our method as an evaluation metric. All generated images and the human-labeled scores will be made publicly available in the future to facilitate ongoing research on this crucial issue. Extensive experiments show that our method aligns more closely with human scoring patterns than other evaluation metrics.
Free-Rider and Conflict Aware Collaboration Formation for Cross-Silo Federated Learning
Oct 28, 2024



Federated learning (FL) is a machine learning paradigm that allows multiple FL participants (FL-PTs) to collaborate on training models without sharing private data. Due to data heterogeneity, negative transfer may occur in the FL training process. This necessitates FL-PT selection based on their data complementarity. In cross-silo FL, organizations that engage in business activities are key sources of FL-PTs. The resulting FL ecosystem has two features: (i) self-interest, and (ii) competition among FL-PTs. This requires the desirable FL-PT selection strategy to simultaneously mitigate the problems of free riders and conflicts of interest among competitors. To this end, we propose an optimal FL collaboration formation strategy -- FedEgoists -- which ensures that: (1) a FL-PT can benefit from FL if and only if it benefits the FL ecosystem, and (2) a FL-PT will not contribute to its competitors or their supporters. It provides an efficient clustering solution to group FL-PTs into coalitions, ensuring that within each coalition, FL-PTs share the same interest. We theoretically prove that the FL-PT coalitions formed are optimal since no coalitions can collaborate together to improve the utility of any of their members. Extensive experiments on widely adopted benchmark datasets demonstrate the effectiveness of FedEgoists compared to nine state-of-the-art baseline methods, and its ability to establish efficient collaborative networks in cross-silos FL with FL-PTs that engage in business activities.
Benchmarking Data Heterogeneity Evaluation Approaches for Personalized Federated Learning
Oct 09, 2024



There is growing research interest in measuring the statistical heterogeneity of clients' local datasets. Such measurements are used to estimate the suitability for collaborative training of personalized federated learning (PFL) models. Currently, these research endeavors are taking place in silos and there is a lack of a unified benchmark to provide a fair and convenient comparison among various approaches in common settings. We aim to bridge this important gap in this paper. The proposed benchmarking framework currently includes six representative approaches. Extensive experiments have been conducted to compare these approaches under five standard non-IID FL settings, providing much needed insights into which approaches are advantageous under which settings. The proposed framework offers useful guidance on the suitability of various data divergence measures in FL systems. It is beneficial for keeping related research activities on the right track in terms of: (1) designing PFL schemes, (2) selecting appropriate data heterogeneity evaluation approaches for specific FL application scenarios, and (3) addressing fairness issues in collaborative model training. The code is available at https://github.com/Xiaoni-61/DH-Benchmark.