 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoronoi-grid-based Pareto Front Learning and Its Application to Collaborative Federated Learning
May 27, 2025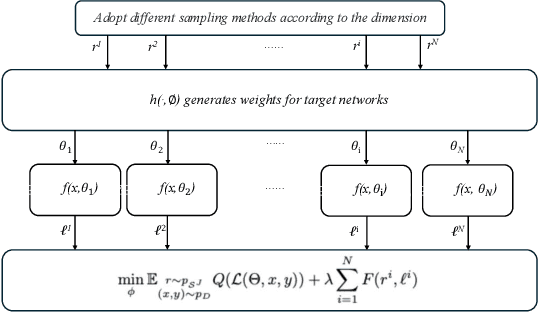
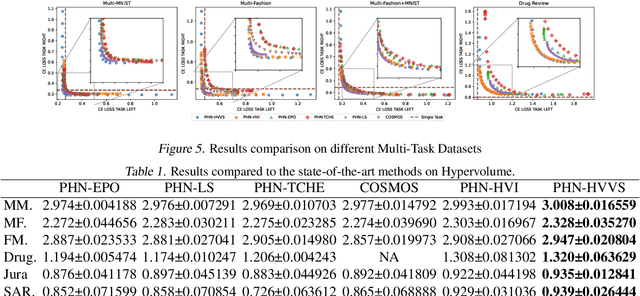
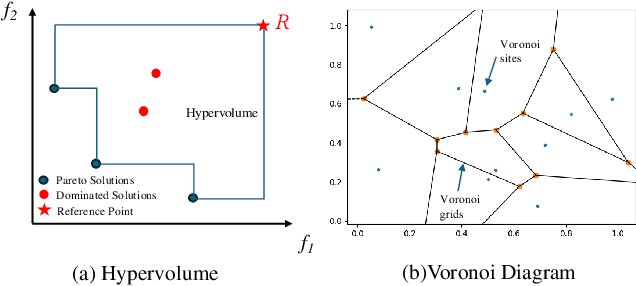
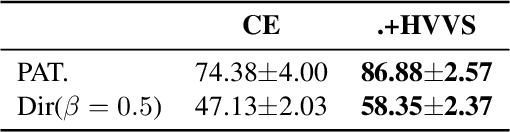
Multi-objective optimization (MOO) exists extensively in machine learning, and aims to find a set of Pareto-optimal solutions, called the Pareto front, e.g., it is fundamental for multiple avenues of research in federated learning (FL). Pareto-Front Learning (PFL) is a powerful method implemented using Hypernetworks (PHNs) to approximate the Pareto front. This method enables the acquisition of a mapping function from a given preference vector to the solutions on the Pareto front. However, most existing PFL approaches still face two challenges: (a) sampling rays in high-dimensional spaces; (b) failing to cover the entire Pareto Front which has a convex shape. Here, we introduce a novel PFL framework, called as PHN-HVVS, which decomposes the design space into Voronoi grids and deploys a genetic algorithm (GA) for Voronoi grid partitioning within high-dimensional space. We put forward a new loss function, which effectively contributes to more extensive coverage of the resultant Pareto front and maximizes the HV Indicator. Experimental results on multiple MOO machine learning tasks demonstrate that PHN-HVVS outperforms the baselines significantly in generating Pareto front. Also, we illustrate that PHN-HVVS advances the methodologies of several recent problems in the FL field. The code is available at https://github.com/buptcmm/phnhvvs}{https://github.com/buptcmm/phnhvvs.
Machine Learning-Accelerated Multi-Objective Design of Fractured Geothermal Systems
Nov 01, 2024

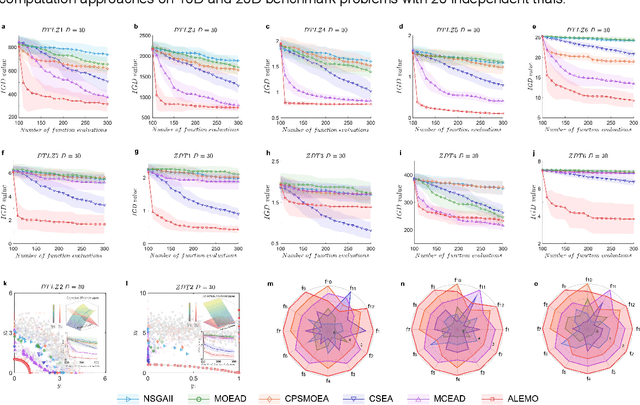

Multi-objective optimization has burgeoned as a potent methodology for informed decision-making in enhanced geothermal systems, aiming to concurrently maximize economic yield, ensure enduring geothermal energy provision, and curtail carbon emissions. However, addressing a multitude of design parameters inherent in computationally intensive physics-driven simulations constitutes a formidable impediment for geothermal design optimization, as well as across a broad range of scientific and engineering domains. Here we report an Active Learning enhanced Evolutionary Multi-objective Optimization algorithm, integrated with hydrothermal simulations in fractured media, to enable efficient optimization of fractured geothermal systems using few model evaluations. We introduce probabilistic neural network as classifier to learns to predict the Pareto dominance relationship between candidate samples and reference samples, thereby facilitating the identification of promising but uncertain offspring solutions. We then use active learning strategy to conduct hypervolume based attention subspace search with surrogate model by iteratively infilling informative samples within local promising parameter subspace. We demonstrate its effectiveness by conducting extensive experimental tests of the integrated framework, including multi-objective benchmark functions, a fractured geothermal model and a large-scale enhanced geothermal system. Results demonstrate that the ALEMO approach achieves a remarkable reduction in required simulations, with a speed-up of 1-2 orders of magnitude (10-100 times faster) than traditional evolutionary methods, thereby enabling accelerated decision-making. Our method is poised to advance the state-of-the-art of renewable geothermal energy system and enable widespread application to accelerate the discovery of optimal designs for complex systems.
Free-Rider and Conflict Aware Collaboration Formation for Cross-Silo Federated Learning
Oct 28, 2024



Federated learning (FL) is a machine learning paradigm that allows multiple FL participants (FL-PTs) to collaborate on training models without sharing private data. Due to data heterogeneity, negative transfer may occur in the FL training process. This necessitates FL-PT selection based on their data complementarity. In cross-silo FL, organizations that engage in business activities are key sources of FL-PTs. The resulting FL ecosystem has two features: (i) self-interest, and (ii) competition among FL-PTs. This requires the desirable FL-PT selection strategy to simultaneously mitigate the problems of free riders and conflicts of interest among competitors. To this end, we propose an optimal FL collaboration formation strategy -- FedEgoists -- which ensures that: (1) a FL-PT can benefit from FL if and only if it benefits the FL ecosystem, and (2) a FL-PT will not contribute to its competitors or their supporters. It provides an efficient clustering solution to group FL-PTs into coalitions, ensuring that within each coalition, FL-PTs share the same interest. We theoretically prove that the FL-PT coalitions formed are optimal since no coalitions can collaborate together to improve the utility of any of their members. Extensive experiments on widely adopted benchmark datasets demonstrate the effectiveness of FedEgoists compared to nine state-of-the-art baseline methods, and its ability to establish efficient collaborative networks in cross-silos FL with FL-PTs that engage in business activities.
Benchmarking Data Heterogeneity Evaluation Approaches for Personalized Federated Learning
Oct 09, 2024



There is growing research interest in measuring the statistical heterogeneity of clients' local datasets. Such measurements are used to estimate the suitability for collaborative training of personalized federated learning (PFL) models. Currently, these research endeavors are taking place in silos and there is a lack of a unified benchmark to provide a fair and convenient comparison among various approaches in common settings. We aim to bridge this important gap in this paper. The proposed benchmarking framework currently includes six representative approaches. Extensive experiments have been conducted to compare these approaches under five standard non-IID FL settings, providing much needed insights into which approaches are advantageous under which settings. The proposed framework offers useful guidance on the suitability of various data divergence measures in FL systems. It is beneficial for keeping related research activities on the right track in terms of: (1) designing PFL schemes, (2) selecting appropriate data heterogeneity evaluation approaches for specific FL application scenarios, and (3) addressing fairness issues in collaborative model training. The code is available at https://github.com/Xiaoni-61/DH-Benchmark.
Identification of Energy Management Configuration Concepts from a Set of Pareto-optimal Solutions
Jun 14, 2023



Optimizing building configurations for an efficient use of energy is increasingly receiving attention by current research and several methods have been developed to address this task. Selecting a suitable configuration based on multiple conflicting objectives, such as initial investment cost, recurring cost, robustness with respect to uncertainty of grid operation is, however, a difficult multi-criteria decision making problem. Concept identification can facilitate a decision maker by sorting configuration options into semantically meaningful groups (concepts), further introducing constraints to meet trade-off expectations for a selection of objectives. In this study, for a set of 20000 Pareto-optimal building energy management configurations, resulting from a many-objective evolutionary optimization, multiple concept identification iterations are conducted to provide a basis for making an informed investment decision. In a series of subsequent analysis steps, it is shown how the choice of description spaces, i.e., the partitioning of the features into sets for which consistent and non-overlapping concepts are required, impacts the type of information that can be extracted and that different setups of description spaces illuminate several different aspects of the configuration data - an important aspect that has not been addressed in previous work.
A Secure Federated Data-Driven Evolutionary Multi-objective Optimization Algorithm
Oct 15, 2022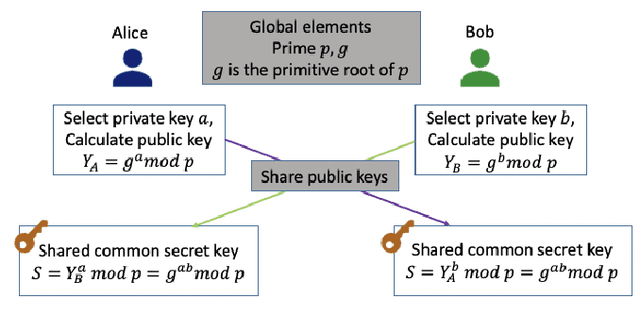
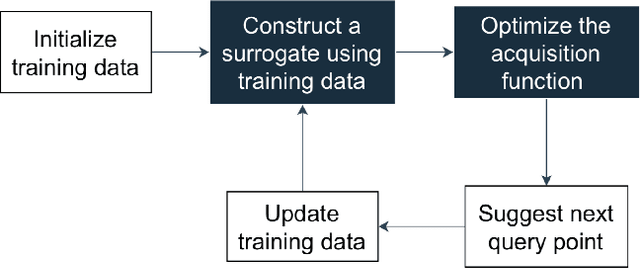
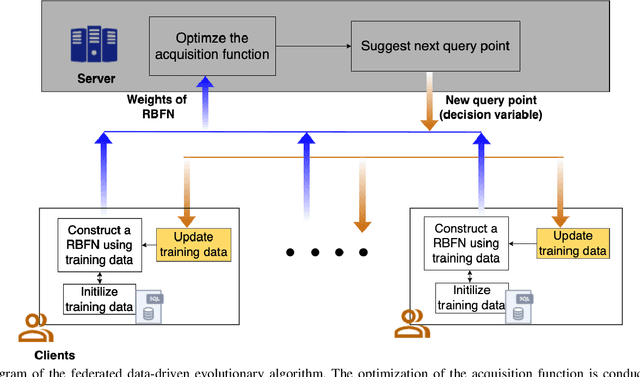
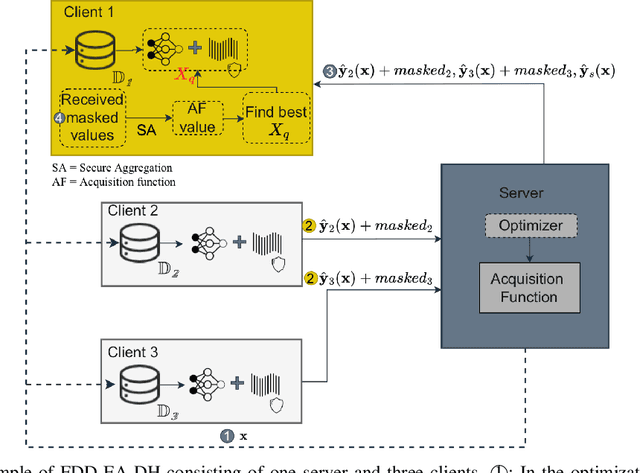
Data-driven evolutionary algorithms usually aim to exploit the information behind a limited amount of data to perform optimization, which have proved to be successful in solving many complex real-world optimization problems. However, most data-driven evolutionary algorithms are centralized, causing privacy and security concerns. Existing federated Bayesian algorithms and data-driven evolutionary algorithms mainly protect the raw data on each client. To address this issue, this paper proposes a secure federated data-driven evolutionary multi-objective optimization algorithm to protect both the raw data and the newly infilled solutions obtained by optimizing the acquisition function conducted on the server. We select the query points on a randomly selected client at each round of surrogate update by calculating the acquisition function values of the unobserved points on this client, thereby reducing the risk of leaking the information about the solution to be sampled. In addition, since the predicted objective values of each client may contain sensitive information, we mask the objective values with Diffie-Hellmann-based noise, and then send only the masked objective values of other clients to the selected client via the server. Since the calculation of the acquisition function also requires both the predicted objective value and the uncertainty of the prediction, the predicted mean objective and uncertainty are normalized to reduce the influence of noise. Experimental results on a set of widely used multi-objective optimization benchmarks show that the proposed algorithm can protect privacy and enhance security with only negligible sacrifice in the performance of federated data-driven evolutionary optimization.