 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoronoi-grid-based Pareto Front Learning and Its Application to Collaborative Federated Learning
May 27, 2025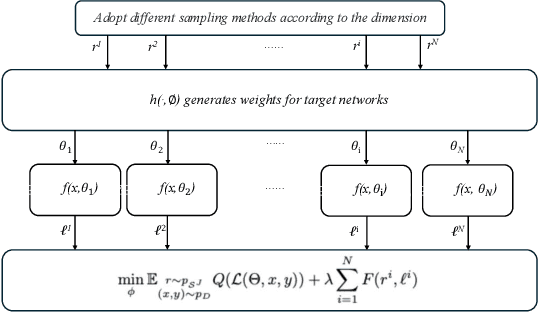
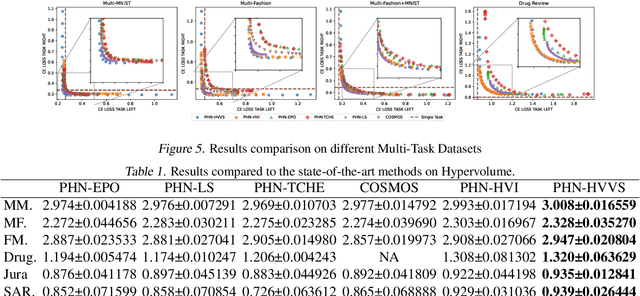
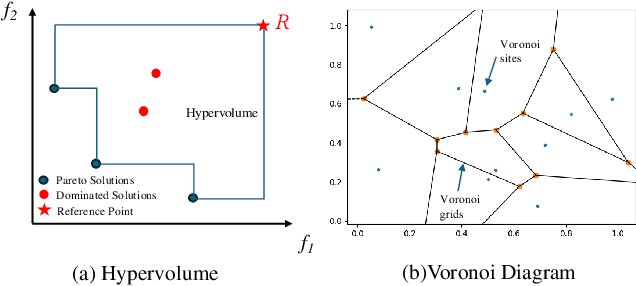
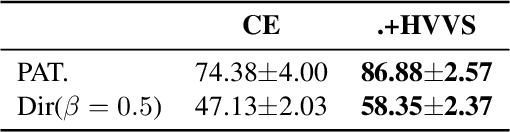
Multi-objective optimization (MOO) exists extensively in machine learning, and aims to find a set of Pareto-optimal solutions, called the Pareto front, e.g., it is fundamental for multiple avenues of research in federated learning (FL). Pareto-Front Learning (PFL) is a powerful method implemented using Hypernetworks (PHNs) to approximate the Pareto front. This method enables the acquisition of a mapping function from a given preference vector to the solutions on the Pareto front. However, most existing PFL approaches still face two challenges: (a) sampling rays in high-dimensional spaces; (b) failing to cover the entire Pareto Front which has a convex shape. Here, we introduce a novel PFL framework, called as PHN-HVVS, which decomposes the design space into Voronoi grids and deploys a genetic algorithm (GA) for Voronoi grid partitioning within high-dimensional space. We put forward a new loss function, which effectively contributes to more extensive coverage of the resultant Pareto front and maximizes the HV Indicator. Experimental results on multiple MOO machine learning tasks demonstrate that PHN-HVVS outperforms the baselines significantly in generating Pareto front. Also, we illustrate that PHN-HVVS advances the methodologies of several recent problems in the FL field. The code is available at https://github.com/buptcmm/phnhvvs}{https://github.com/buptcmm/phnhvvs.
Dynamic User Interface Generation for Enhanced Human-Computer Interaction Using Variational Autoencoders
Dec 19, 2024



This study presents a novel approach for intelligent user interaction interface generation and optimization, grounded in the variational autoencoder (VAE) model. With the rapid advancement of intelligent technologies, traditional interface design methods struggle to meet the evolving demands for diversity and personalization, often lacking flexibility in real-time adjustments to enhance the user experience. Human-Computer Interaction (HCI) plays a critical role in addressing these challenges by focusing on creating interfaces that are functional, intuitive, and responsive to user needs. This research leverages the RICO dataset to train the VAE model, enabling the simulation and creation of user interfaces that align with user aesthetics and interaction habits. By integrating real-time user behavior data, the system dynamically refines and optimizes the interface, improving usability and underscoring the importance of HCI in achieving a seamless user experience. Experimental findings indicate that the VAE-based approach significantly enhances the quality and precision of interface generation compared to other methods, including autoencoders (AE), generative adversarial networks (GAN), conditional GANs (cGAN), deep belief networks (DBN), and VAE-GAN. This work contributes valuable insights into HCI, providing robust technical solutions for automated interface generation and enhanced user experience optimization.
Emotion-Aware Interaction Design in Intelligent User Interface Using Multi-Modal Deep Learning
Nov 10, 2024In an era where user interaction with technology is ubiquitous, the importance of user interface (UI) design cannot be overstated. A well-designed UI not only enhances usability but also fosters more natural, intuitive, and emotionally engaging experiences, making technology more accessible and impactful in everyday life. This research addresses this growing need by introducing an advanced emotion recognition system to significantly improve the emotional responsiveness of UI. By integrating facial expressions, speech, and textual data through a multi-branch Transformer model, the system interprets complex emotional cues in real-time, enabling UIs to interact more empathetically and effectively with users. Using the public MELD dataset for validation, our model demonstrates substantial improvements in emotion recognition accuracy and F1 scores, outperforming traditional methods. These findings underscore the critical role that sophisticated emotion recognition plays in the evolution of UIs, making technology more attuned to user needs and emotions. This study highlights how enhanced emotional intelligence in UIs is not only about technical innovation but also about fostering deeper, more meaningful connections between users and the digital world, ultimately shaping how people interact with technology in their daily lives.
Free-Rider and Conflict Aware Collaboration Formation for Cross-Silo Federated Learning
Oct 28, 2024



Federated learning (FL) is a machine learning paradigm that allows multiple FL participants (FL-PTs) to collaborate on training models without sharing private data. Due to data heterogeneity, negative transfer may occur in the FL training process. This necessitates FL-PT selection based on their data complementarity. In cross-silo FL, organizations that engage in business activities are key sources of FL-PTs. The resulting FL ecosystem has two features: (i) self-interest, and (ii) competition among FL-PTs. This requires the desirable FL-PT selection strategy to simultaneously mitigate the problems of free riders and conflicts of interest among competitors. To this end, we propose an optimal FL collaboration formation strategy -- FedEgoists -- which ensures that: (1) a FL-PT can benefit from FL if and only if it benefits the FL ecosystem, and (2) a FL-PT will not contribute to its competitors or their supporters. It provides an efficient clustering solution to group FL-PTs into coalitions, ensuring that within each coalition, FL-PTs share the same interest. We theoretically prove that the FL-PT coalitions formed are optimal since no coalitions can collaborate together to improve the utility of any of their members. Extensive experiments on widely adopted benchmark datasets demonstrate the effectiveness of FedEgoists compared to nine state-of-the-art baseline methods, and its ability to establish efficient collaborative networks in cross-silos FL with FL-PTs that engage in business activities.
Benchmarking Data Heterogeneity Evaluation Approaches for Personalized Federated Learning
Oct 09, 2024



There is growing research interest in measuring the statistical heterogeneity of clients' local datasets. Such measurements are used to estimate the suitability for collaborative training of personalized federated learning (PFL) models. Currently, these research endeavors are taking place in silos and there is a lack of a unified benchmark to provide a fair and convenient comparison among various approaches in common settings. We aim to bridge this important gap in this paper. The proposed benchmarking framework currently includes six representative approaches. Extensive experiments have been conducted to compare these approaches under five standard non-IID FL settings, providing much needed insights into which approaches are advantageous under which settings. The proposed framework offers useful guidance on the suitability of various data divergence measures in FL systems. It is beneficial for keeping related research activities on the right track in terms of: (1) designing PFL schemes, (2) selecting appropriate data heterogeneity evaluation approaches for specific FL application scenarios, and (3) addressing fairness issues in collaborative model training. The code is available at https://github.com/Xiaoni-61/DH-Benchmark.