 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic User Interface Generation for Enhanced Human-Computer Interaction Using Variational Autoencoders
Dec 19, 2024



This study presents a novel approach for intelligent user interaction interface generation and optimization, grounded in the variational autoencoder (VAE) model. With the rapid advancement of intelligent technologies, traditional interface design methods struggle to meet the evolving demands for diversity and personalization, often lacking flexibility in real-time adjustments to enhance the user experience. Human-Computer Interaction (HCI) plays a critical role in addressing these challenges by focusing on creating interfaces that are functional, intuitive, and responsive to user needs. This research leverages the RICO dataset to train the VAE model, enabling the simulation and creation of user interfaces that align with user aesthetics and interaction habits. By integrating real-time user behavior data, the system dynamically refines and optimizes the interface, improving usability and underscoring the importance of HCI in achieving a seamless user experience. Experimental findings indicate that the VAE-based approach significantly enhances the quality and precision of interface generation compared to other methods, including autoencoders (AE), generative adversarial networks (GAN), conditional GANs (cGAN), deep belief networks (DBN), and VAE-GAN. This work contributes valuable insights into HCI, providing robust technical solutions for automated interface generation and enhanced user experience optimization.
Emotion-Aware Interaction Design in Intelligent User Interface Using Multi-Modal Deep Learning
Nov 10, 2024In an era where user interaction with technology is ubiquitous, the importance of user interface (UI) design cannot be overstated. A well-designed UI not only enhances usability but also fosters more natural, intuitive, and emotionally engaging experiences, making technology more accessible and impactful in everyday life. This research addresses this growing need by introducing an advanced emotion recognition system to significantly improve the emotional responsiveness of UI. By integrating facial expressions, speech, and textual data through a multi-branch Transformer model, the system interprets complex emotional cues in real-time, enabling UIs to interact more empathetically and effectively with users. Using the public MELD dataset for validation, our model demonstrates substantial improvements in emotion recognition accuracy and F1 scores, outperforming traditional methods. These findings underscore the critical role that sophisticated emotion recognition plays in the evolution of UIs, making technology more attuned to user needs and emotions. This study highlights how enhanced emotional intelligence in UIs is not only about technical innovation but also about fostering deeper, more meaningful connections between users and the digital world, ultimately shaping how people interact with technology in their daily lives.
Labels, Information, and Computation: Efficient, Privacy-Preserving Learning Using Sufficient Labels
Apr 19, 2021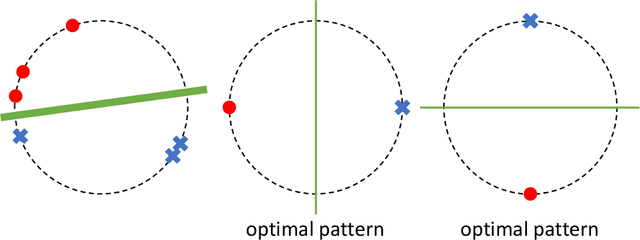
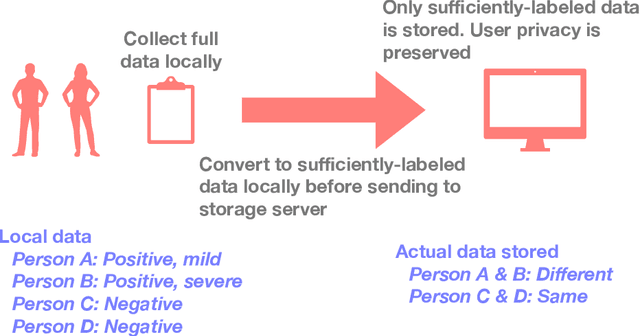
In supervised learning, obtaining a large set of fully-labeled training data is expensive. We show that we do not always need full label information on every single training example to train a competent classifier. Specifically, inspired by the principle of sufficiency in statistics, we present a statistic (a summary) of the fully-labeled training set that captures almost all the relevant information for classification but at the same time is easier to obtain directly. We call this statistic "sufficiently-labeled data" and prove its sufficiency and efficiency for finding the optimal hidden representations, on which competent classifier heads can be trained using as few as a single randomly-chosen fully-labeled example per class. Sufficiently-labeled data can be obtained from annotators directly without collecting the fully-labeled data first. And we prove that it is easier to directly obtain sufficiently-labeled data than obtaining fully-labeled data. Furthermore, sufficiently-labeled data naturally preserves user privacy by storing relative, instead of absolute, information. Extensive experimental results are provided to support our theory.
Training Deep Architectures Without End-to-End Backpropagation: A Brief Survey
Jan 09, 2021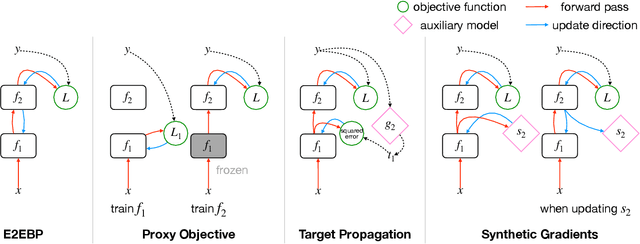

This tutorial paper surveys training alternatives to end-to-end backpropagation (E2EBP) -- the de facto standard for training deep architectures. Modular training refers to strictly local training without both the forward and the backward pass, i.e., dividing a deep architecture into several nonoverlapping modules and training them separately without any end-to-end operation. Between the fully global E2EBP and the strictly local modular training, there are "weakly modular" hybrids performing training without the backward pass only. These alternatives can match or surpass the performance of E2EBP on challenging datasets such as ImageNet, and are gaining increased attention primarily because they offer practical advantages over E2EBP, which will be enumerated herein. In particular, they allow for greater modularity and transparency in deep learning workflows, aligning deep learning with the mainstream computer science engineering that heavily exploits modularization for scalability. Modular training has also revealed novel insights about learning and may have further implications on other important research domains. Specifically, it induces natural and effective solutions to some important practical problems such as data efficiency and transferability estimation.
JPAD-SE: High-Level Semantics for Joint Perception-Accuracy-Distortion Enhancement in Image Compression
May 29, 2020
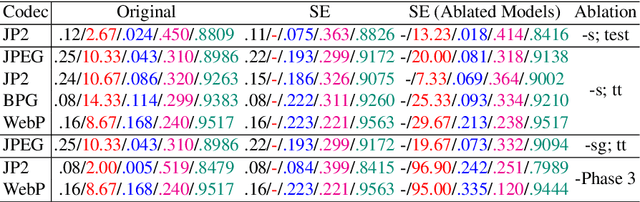

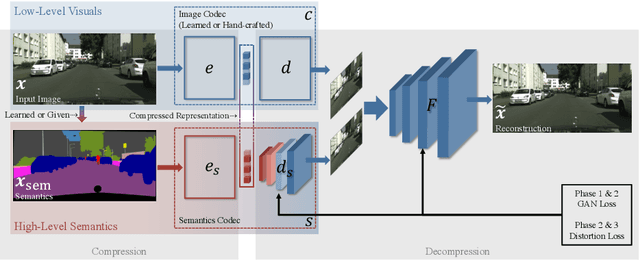
While humans can effortlessly transform complex visual scenes into simple words and the other way around by leveraging their high-level understanding of the content, conventional or the more recent learned image compression codecs do not seem to utilize the semantic meanings of visual content to its full potential. Moreover, they focus mostly on rate-distortion and tend to underperform in perception quality especially in low bitrate regime, and often disregard the performance of downstream computer vision algorithms, which is a fast-growing consumer group of compressed images in addition to human viewers. In this paper, we (1) present a generic framework that can enable any image codec to leverage high-level semantics, and (2) study the joint optimization of perception quality, accuracy of downstream computer vision task, and distortion. Our idea is that given any codec, we utilize high-level semantics to augment the low-level visual features extracted by it and produce essentially a new, semantic-aware codec. And we argue that semantic enhancement implicitly optimizes rate-perception-accuracy-distortion (R-PAD) performance. To validate our claim, we perform extensive empirical evaluations and provide both quantitative and qualitative results.
Modularizing Deep Learning via Pairwise Learning With Kernels
May 12, 2020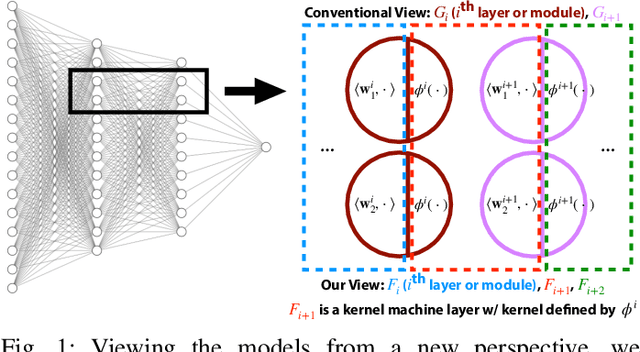
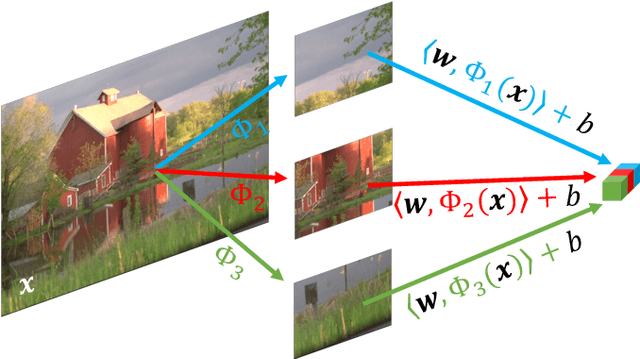
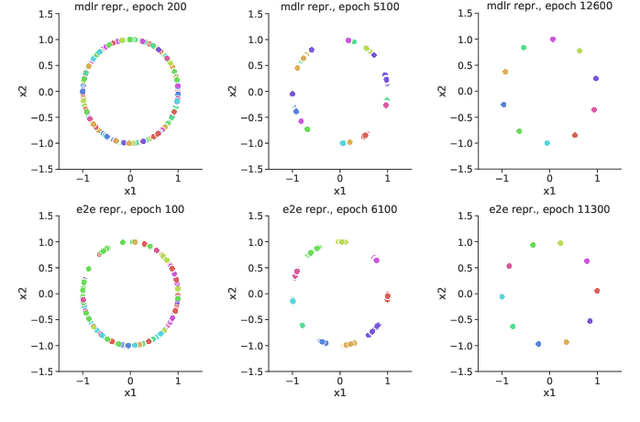
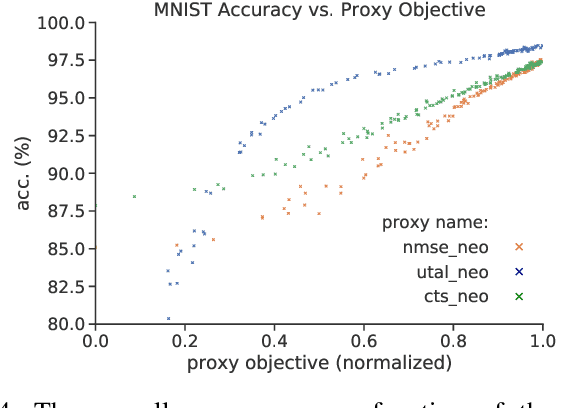
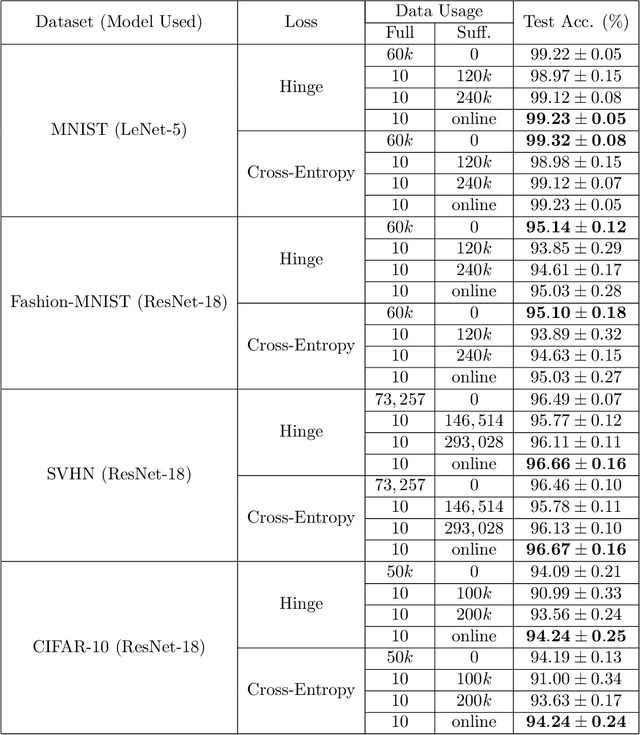
By redefining the conventional notions of layers, we present an alternative view on finitely wide, fully trainable deep neural networks as stacked linear models in feature spaces, leading to a kernel machine interpretation. Based on this construction, we then propose a provably optimal modular learning framework for classification, avoiding between-module backpropagation. This modular training approach brings new insights into the label requirement of deep learning: It leverages weak pairwise labels when learning the hidden modules. When training the output module, on the other hand, it requires full supervision but achieves high label efficiency, needing as few as 10 randomly selected labeled examples (one from each class) to achieve 94.88\% accuracy on CIFAR-10 using a ResNet-18 backbone. Moreover, modular training enables fully modularized deep learning workflows, which then simplify the design and implementation of pipelines and improve the maintainability and reusability of models. To showcase the advantages of such a modularized workflow, we describe a simple yet reliable method for estimating reusability of pre-trained modules as well as task transferability in a transfer learning setting. At practically no computation overhead, it precisely described the task space structure of 15 binary classification tasks from CIFAR-10.
Learning Multiple Levels of Representations with Kernel Machines
Apr 02, 2018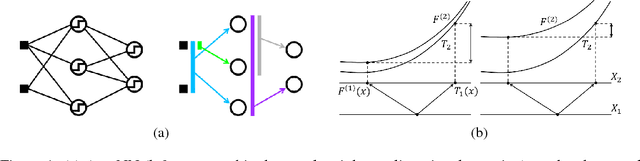
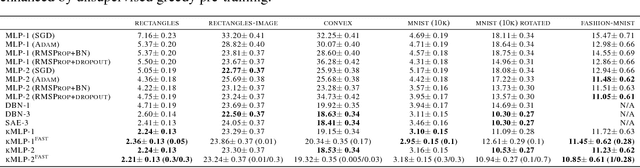
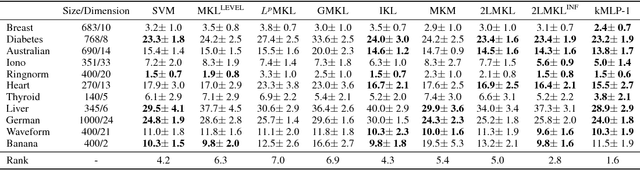
We propose a connectionist-inspired kernel machine model with three key advantages over traditional kernel machines. First, it is capable of learning distributed and hierarchical representations. Second, its performance is highly robust to the choice of kernel function. Third, the solution space is not limited to the span of images of training data in reproducing kernel Hilbert space (RKHS). Together with the architecture, we propose a greedy learning algorithm that allows the proposed multilayer network to be trained layer-wise without backpropagation by optimizing the geometric properties of images in RKHS. With a single fixed generic kernel for each layer and two layers in total, our model compares favorably with state-of-the-art multiple kernel learning algorithms using significantly more kernels and popular deep architectures on widely used classification benchmarks.