 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCubeComposer: Spatio-Temporal Autoregressive 4K 360° Video Generation from Perspective Video
Mar 04, 2026Generating high-quality 360° panoramic videos from perspective input is one of the crucial applications for virtual reality (VR), whereby high-resolution videos are especially important for immersive experience. Existing methods are constrained by computational limitations of vanilla diffusion models, only supporting $\leq$ 1K resolution native generation and relying on suboptimal post super-resolution to increase resolution. We introduce CubeComposer, a novel spatio-temporal autoregressive diffusion model that natively generates 4K-resolution 360° videos. By decomposing videos into cubemap representations with six faces, CubeComposer autoregressively synthesizes content in a well-planned spatio-temporal order, reducing memory demands while enabling high-resolution output. Specifically, to address challenges in multi-dimensional autoregression, we propose: (1) a spatio-temporal autoregressive strategy that orchestrates 360° video generation across cube faces and time windows for coherent synthesis; (2) a cube face context management mechanism, equipped with a sparse context attention design to improve efficiency; and (3) continuity-aware techniques, including cube-aware positional encoding, padding, and blending to eliminate boundary seams. Extensive experiments on benchmark datasets demonstrate that CubeComposer outperforms state-of-the-art methods in native resolution and visual quality, supporting practical VR application scenarios. Project page: https://lg-li.github.io/project/cubecomposer
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Feb 06, 2026Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Jan 22, 2026Recent video generation models demonstrate remarkable ability to capture complex physical interactions and scene evolution over time. To leverage their spatiotemporal priors, robotics works have adapted video models for policy learning but introduce complexity by requiring multiple stages of post-training and new architectural components for action generation. In this work, we introduce Cosmos Policy, a simple approach for adapting a large pretrained video model (Cosmos-Predict2) into an effective robot policy through a single stage of post-training on the robot demonstration data collected on the target platform, with no architectural modifications. Cosmos Policy learns to directly generate robot actions encoded as latent frames within the video model's latent diffusion process, harnessing the model's pretrained priors and core learning algorithm to capture complex action distributions. Additionally, Cosmos Policy generates future state images and values (expected cumulative rewards), which are similarly encoded as latent frames, enabling test-time planning of action trajectories with higher likelihood of success. In our evaluations, Cosmos Policy achieves state-of-the-art performance on the LIBERO and RoboCasa simulation benchmarks (98.5% and 67.1% average success rates, respectively) and the highest average score in challenging real-world bimanual manipulation tasks, outperforming strong diffusion policies trained from scratch, video model-based policies, and state-of-the-art vision-language-action models fine-tuned on the same robot demonstrations. Furthermore, given policy rollout data, Cosmos Policy can learn from experience to refine its world model and value function and leverage model-based planning to achieve even higher success rates in challenging tasks. We release code, models, and training data at https://research.nvidia.com/labs/dir/cosmos-policy/
Openpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
Scalable Policy Evaluation with Video World Models
Nov 17, 2025Training generalist policies for robotic manipulation has shown great promise, as they enable language-conditioned, multi-task behaviors across diverse scenarios. However, evaluating these policies remains difficult because real-world testing is expensive, time-consuming, and labor-intensive. It also requires frequent environment resets and carries safety risks when deploying unproven policies on physical robots. Manually creating and populating simulation environments with assets for robotic manipulation has not addressed these issues, primarily due to the significant engineering effort required and the often substantial sim-to-real gap, both in terms of physics and rendering. In this paper, we explore the use of action-conditional video generation models as a scalable way to learn world models for policy evaluation. We demonstrate how to incorporate action conditioning into existing pre-trained video generation models. This allows leveraging internet-scale in-the-wild online videos during the pre-training stage, and alleviates the need for a large dataset of paired video-action data, which is expensive to collect for robotic manipulation. Our paper examines the effect of dataset diversity, pre-trained weight and common failure cases for the proposed evaluation pipeline. Our experiments demonstrate that, across various metrics, including policy ranking and the correlation between actual policy values and predicted policy values, these models offer a promising approach for evaluating policies without requiring real-world interactions.
ToonComposer: Streamlining Cartoon Production with Generative Post-Keyframing
Aug 14, 2025
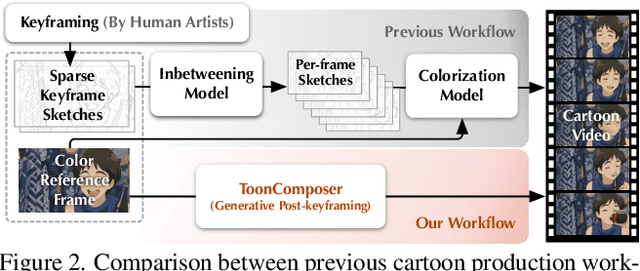
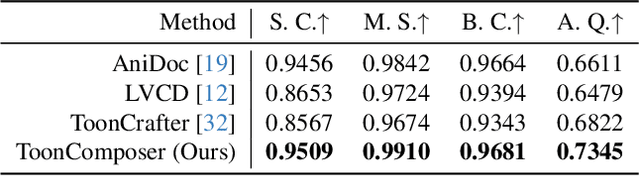
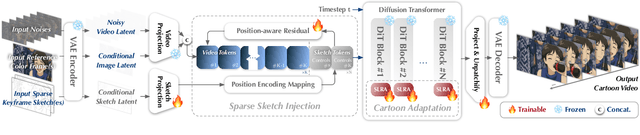
Traditional cartoon and anime production involves keyframing, inbetweening, and colorization stages, which require intensive manual effort. Despite recent advances in AI, existing methods often handle these stages separately, leading to error accumulation and artifacts. For instance, inbetweening approaches struggle with large motions, while colorization methods require dense per-frame sketches. To address this, we introduce ToonComposer, a generative model that unifies inbetweening and colorization into a single post-keyframing stage. ToonComposer employs a sparse sketch injection mechanism to provide precise control using keyframe sketches. Additionally, it uses a cartoon adaptation method with the spatial low-rank adapter to tailor a modern video foundation model to the cartoon domain while keeping its temporal prior intact. Requiring as few as a single sketch and a colored reference frame, ToonComposer excels with sparse inputs, while also supporting multiple sketches at any temporal location for more precise motion control. This dual capability reduces manual workload and improves flexibility, empowering artists in real-world scenarios. To evaluate our model, we further created PKBench, a benchmark featuring human-drawn sketches that simulate real-world use cases. Our evaluation demonstrates that ToonComposer outperforms existing methods in visual quality, motion consistency, and production efficiency, offering a superior and more flexible solution for AI-assisted cartoon production.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.
A Physics-Informed Blur Learning Framework for Imaging Systems
Feb 17, 2025Accurate blur estimation is essential for high-performance imaging across various applications. Blur is typically represented by the point spread function (PSF). In this paper, we propose a physics-informed PSF learning framework for imaging systems, consisting of a simple calibration followed by a learning process. Our framework could achieve both high accuracy and universal applicability. Inspired by the Seidel PSF model for representing spatially varying PSF, we identify its limitations in optimization and introduce a novel wavefront-based PSF model accompanied by an optimization strategy, both reducing optimization complexity and improving estimation accuracy. Moreover, our wavefront-based PSF model is independent of lens parameters, eliminate the need for prior knowledge of the lens. To validate our approach, we compare it with recent PSF estimation methods (Degradation Transfer and Fast Two-step) through a deblurring task, where all the estimated PSFs are used to train state-of-the-art deblurring algorithms. Our approach demonstrates improvements in image quality in simulation and also showcases noticeable visual quality improvements on real captured images.
Tolerance-Aware Deep Optics
Feb 07, 2025



Deep optics has emerged as a promising approach by co-designing optical elements with deep learning algorithms. However, current research typically overlooks the analysis and optimization of manufacturing and assembly tolerances. This oversight creates a significant performance gap between designed and fabricated optical systems. To address this challenge, we present the first end-to-end tolerance-aware optimization framework that incorporates multiple tolerance types into the deep optics design pipeline. Our method combines physics-informed modelling with data-driven training to enhance optical design by accounting for and compensating for structural deviations in manufacturing and assembly. We validate our approach through computational imaging applications, demonstrating results in both simulations and real-world experiments. We further examine how our proposed solution improves the robustness of optical systems and vision algorithms against tolerances through qualitative and quantitative analyses. Code and additional visual results are available at openimaginglab.github.io/LensTolerance.