 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedCollab: Causal-Driven Multi-Agent Collaboration for Full-Cycle Clinical Diagnosis via IBIS-Structured Argumentation
Mar 01, 2026Large language models (LLMs) have shown promise in healthcare applications, however, their use in clinical practice is still limited by diagnostic hallucinations and insufficiently interpretable reasoning. We present MedCollab, a novel multi-agent framework that emulates the hierarchical consultation workflow of modern hospitals to autonomously navigate the full-cycle diagnostic process. The framework incorporates a dynamic specialist recruitment mechanism that adaptively assembles clinical and examination agents according to patient-specific symptoms and examination results. To ensure the rigor of clinical work, we adopt a structured Issue-Based Information System (IBIS) argumentation protocol that requires agents to provide ``Positions'' backed by traceable evidence from medical knowledge and clinical data. Furthermore, the framework constructs a Hierarchical Disease Causal Chain that transforms flattened diagnostic predictions into a structured model of pathological progression through explicit logical operators. A multi-round Consensus Mechanism iteratively filters low-quality reasoning through logic auditing and weighted voting. Evaluated on real-world clinical datasets, MedCollab significantly outperforms pure LLMs and medical multi-agent systems in Accuracy and RaTEScore, demonstrating a marked reduction in medical hallucinations. These findings indicate that MedCollab provides an extensible, transparent, and clinically compliant approach to medical decision-making.
NVComposer: Boosting Generative Novel View Synthesis with Multiple Sparse and Unposed Images
Dec 04, 2024



Recent advancements in generative models have significantly improved novel view synthesis (NVS) from multi-view data. However, existing methods depend on external multi-view alignment processes, such as explicit pose estimation or pre-reconstruction, which limits their flexibility and accessibility, especially when alignment is unstable due to insufficient overlap or occlusions between views. In this paper, we propose NVComposer, a novel approach that eliminates the need for explicit external alignment. NVComposer enables the generative model to implicitly infer spatial and geometric relationships between multiple conditional views by introducing two key components: 1) an image-pose dual-stream diffusion model that simultaneously generates target novel views and condition camera poses, and 2) a geometry-aware feature alignment module that distills geometric priors from dense stereo models during training. Extensive experiments demonstrate that NVComposer achieves state-of-the-art performance in generative multi-view NVS tasks, removing the reliance on external alignment and thus improving model accessibility. Our approach shows substantial improvements in synthesis quality as the number of unposed input views increases, highlighting its potential for more flexible and accessible generative NVS systems.
NovelGS: Consistent Novel-view Denoising via Large Gaussian Reconstruction Model
Nov 25, 2024

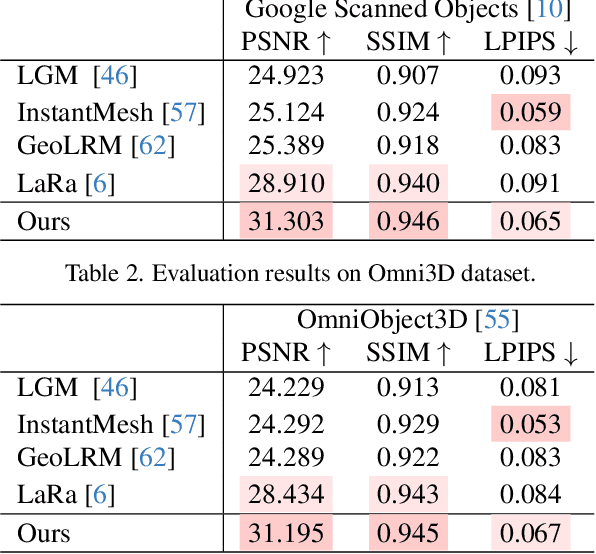

We introduce NovelGS, a diffusion model for Gaussian Splatting (GS) given sparse-view images. Recent works leverage feed-forward networks to generate pixel-aligned Gaussians, which could be fast rendered. Unfortunately, the method was unable to produce satisfactory results for areas not covered by the input images due to the formulation of these methods. In contrast, we leverage the novel view denoising through a transformer-based network to generate 3D Gaussians. Specifically, by incorporating both conditional views and noisy target views, the network predicts pixel-aligned Gaussians for each view. During training, the rendered target and some additional views of the Gaussians are supervised. During inference, the target views are iteratively rendered and denoised from pure noise. Our approach demonstrates state-of-the-art performance in addressing the multi-view image reconstruction challenge. Due to generative modeling of unseen regions, NovelGS effectively reconstructs 3D objects with consistent and sharp textures. Experimental results on publicly available datasets indicate that NovelGS substantially surpasses existing image-to-3D frameworks, both qualitatively and quantitatively. We also demonstrate the potential of NovelGS in generative tasks, such as text-to-3D and image-to-3D, by integrating it with existing multiview diffusion models. We will make the code publicly accessible.
InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models
Apr 14, 2024



We present InstantMesh, a feed-forward framework for instant 3D mesh generation from a single image, featuring state-of-the-art generation quality and significant training scalability. By synergizing the strengths of an off-the-shelf multiview diffusion model and a sparse-view reconstruction model based on the LRM architecture, InstantMesh is able to create diverse 3D assets within 10 seconds. To enhance the training efficiency and exploit more geometric supervisions, e.g, depths and normals, we integrate a differentiable iso-surface extraction module into our framework and directly optimize on the mesh representation. Experimental results on public datasets demonstrate that InstantMesh significantly outperforms other latest image-to-3D baselines, both qualitatively and quantitatively. We release all the code, weights, and demo of InstantMesh, with the intention that it can make substantial contributions to the community of 3D generative AI and empower both researchers and content creators.
Advances in 3D Generation: A Survey
Jan 31, 2024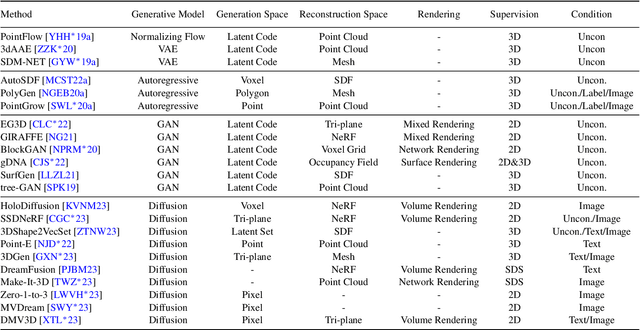
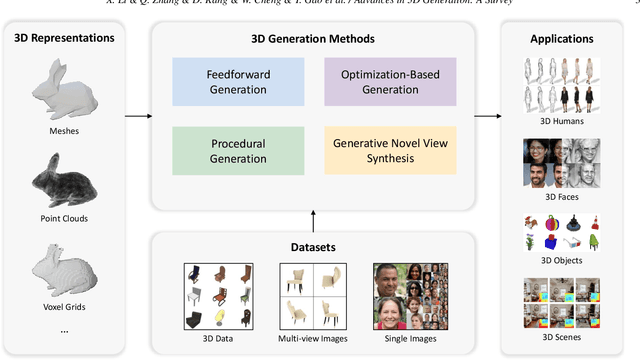
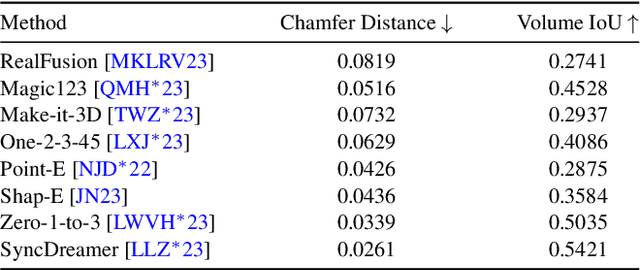
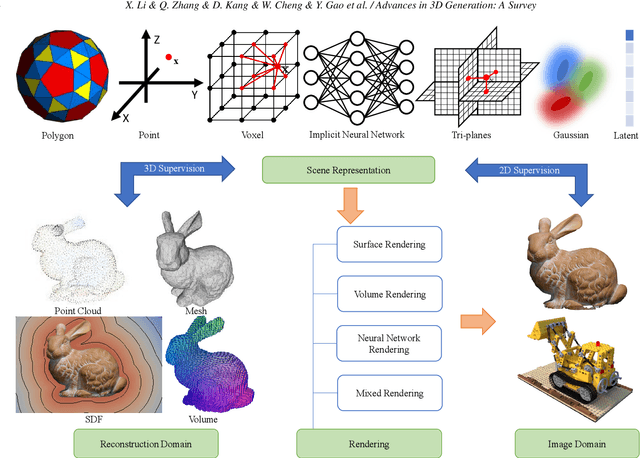
Generating 3D models lies at the core of computer graphics and has been the focus of decades of research. With the emergence of advanced neural representations and generative models, the field of 3D content generation is developing rapidly, enabling the creation of increasingly high-quality and diverse 3D models. The rapid growth of this field makes it difficult to stay abreast of all recent developments. In this survey, we aim to introduce the fundamental methodologies of 3D generation methods and establish a structured roadmap, encompassing 3D representation, generation methods, datasets, and corresponding applications. Specifically, we introduce the 3D representations that serve as the backbone for 3D generation. Furthermore, we provide a comprehensive overview of the rapidly growing literature on generation methods, categorized by the type of algorithmic paradigms, including feedforward generation, optimization-based generation, procedural generation, and generative novel view synthesis. Lastly, we discuss available datasets, applications, and open challenges. We hope this survey will help readers explore this exciting topic and foster further advancements in the field of 3D content generation.
Sparse3D: Distilling Multiview-Consistent Diffusion for Object Reconstruction from Sparse Views
Aug 27, 2023Reconstructing 3D objects from extremely sparse views is a long-standing and challenging problem. While recent techniques employ image diffusion models for generating plausible images at novel viewpoints or for distilling pre-trained diffusion priors into 3D representations using score distillation sampling (SDS), these methods often struggle to simultaneously achieve high-quality, consistent, and detailed results for both novel-view synthesis (NVS) and geometry. In this work, we present Sparse3D, a novel 3D reconstruction method tailored for sparse view inputs. Our approach distills robust priors from a multiview-consistent diffusion model to refine a neural radiance field. Specifically, we employ a controller that harnesses epipolar features from input views, guiding a pre-trained diffusion model, such as Stable Diffusion, to produce novel-view images that maintain 3D consistency with the input. By tapping into 2D priors from powerful image diffusion models, our integrated model consistently delivers high-quality results, even when faced with open-world objects. To address the blurriness introduced by conventional SDS, we introduce the category-score distillation sampling (C-SDS) to enhance detail. We conduct experiments on CO3DV2 which is a multi-view dataset of real-world objects. Both quantitative and qualitative evaluations demonstrate that our approach outperforms previous state-of-the-art works on the metrics regarding NVS and geometry reconstruction.
ID-Pose: Sparse-view Camera Pose Estimation by Inverting Diffusion Models
Jun 29, 2023Given sparse views of an object, estimating their camera poses is a long-standing and intractable problem. We harness the pre-trained diffusion model of novel views conditioned on viewpoints (Zero-1-to-3). We present ID-Pose which inverses the denoising diffusion process to estimate the relative pose given two input images. ID-Pose adds a noise on one image, and predicts the noise conditioned on the other image and a decision variable for the pose. The prediction error is used as the objective to find the optimal pose with the gradient descent method. ID-Pose can handle more than two images and estimate each of the poses with multiple image pairs from triangular relationships. ID-Pose requires no training and generalizes to real-world images. We conduct experiments using high-quality real-scanned 3D objects, where ID-Pose significantly outperforms state-of-the-art methods.
InstructP2P: Learning to Edit 3D Point Clouds with Text Instructions
Jun 12, 2023



Enhancing AI systems to perform tasks following human instructions can significantly boost productivity. In this paper, we present InstructP2P, an end-to-end framework for 3D shape editing on point clouds, guided by high-level textual instructions. InstructP2P extends the capabilities of existing methods by synergizing the strengths of a text-conditioned point cloud diffusion model, Point-E, and powerful language models, enabling color and geometry editing using language instructions. To train InstructP2P, we introduce a new shape editing dataset, constructed by integrating a shape segmentation dataset, off-the-shelf shape programs, and diverse edit instructions generated by a large language model, ChatGPT. Our proposed method allows for editing both color and geometry of specific regions in a single forward pass, while leaving other regions unaffected. In our experiments, InstructP2P shows generalization capabilities, adapting to novel shape categories and instructions, despite being trained on a limited amount of data.
SparseGNV: Generating Novel Views of Indoor Scenes with Sparse Input Views
May 11, 2023
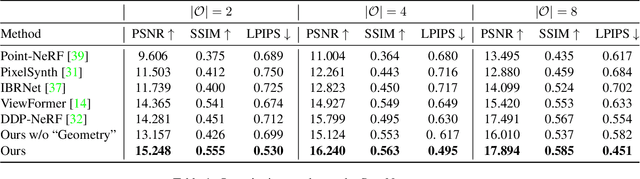
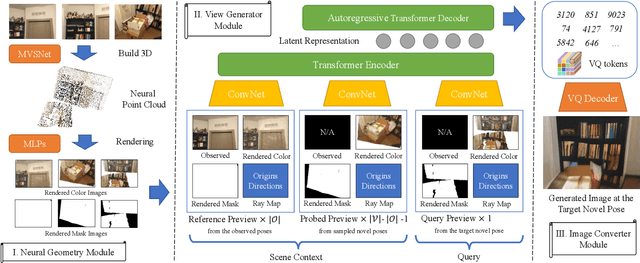

We study to generate novel views of indoor scenes given sparse input views. The challenge is to achieve both photorealism and view consistency. We present SparseGNV: a learning framework that incorporates 3D structures and image generative models to generate novel views with three modules. The first module builds a neural point cloud as underlying geometry, providing contextual information and guidance for the target novel view. The second module utilizes a transformer-based network to map the scene context and the guidance into a shared latent space and autoregressively decodes the target view in the form of discrete image tokens. The third module reconstructs the tokens into the image of the target view. SparseGNV is trained across a large indoor scene dataset to learn generalizable priors. Once trained, it can efficiently generate novel views of an unseen indoor scene in a feed-forward manner. We evaluate SparseGNV on both real-world and synthetic indoor scenes and demonstrate that it outperforms state-of-the-art methods based on either neural radiance fields or conditional image generation.
Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models
Dec 28, 2022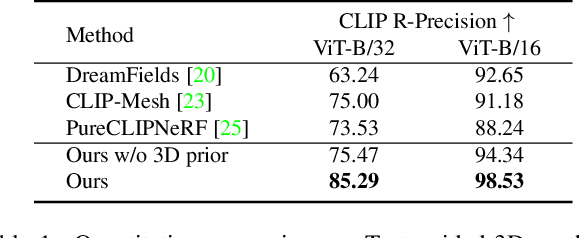



Recent CLIP-guided 3D optimization methods, e.g., DreamFields and PureCLIPNeRF achieve great success in zero-shot text-guided 3D synthesis. However, due to the scratch training and random initialization without any prior knowledge, these methods usually fail to generate accurate and faithful 3D structures that conform to the corresponding text. In this paper, we make the first attempt to introduce the explicit 3D shape prior to CLIP-guided 3D optimization methods. Specifically, we first generate a high-quality 3D shape from input texts in the text-to-shape stage as the 3D shape prior. We then utilize it as the initialization of a neural radiance field and then optimize it with the full prompt. For the text-to-shape generation, we present a simple yet effective approach that directly bridges the text and image modalities with a powerful text-to-image diffusion model. To narrow the style domain gap between images synthesized by the text-to-image model and shape renderings used to train the image-to-shape generator, we further propose to jointly optimize a learnable text prompt and fine-tune the text-to-image diffusion model for rendering-style image generation. Our method, namely, Dream3D, is capable of generating imaginative 3D content with better visual quality and shape accuracy than state-of-the-art methods.