 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo World Model: Camera-Guided Stereo Video Generation
Mar 18, 2026We present StereoWorld, a camera-conditioned stereo world model that jointly learns appearance and binocular geometry for end-to-end stereo video generation.Unlike monocular RGB or RGBD approaches, StereoWorld operates exclusively within the RGB modality, while simultaneously grounding geometry directly from disparity. To efficiently achieve consistent stereo generation, our approach introduces two key designs: (1) a unified camera-frame RoPE that augments latent tokens with camera-aware rotary positional encoding, enabling relative, view- and time-consistent conditioning while preserving pretrained video priors via a stable attention initialization; and (2) a stereo-aware attention decomposition that factors full 4D attention into 3D intra-view attention plus horizontal row attention, leveraging the epipolar prior to capture disparity-aligned correspondences with substantially lower compute. Across benchmarks, StereoWorld improves stereo consistency, disparity accuracy, and camera-motion fidelity over strong monocular-then-convert pipelines, achieving more than 3x faster generation with an additional 5% gain in viewpoint consistency. Beyond benchmarks, StereoWorld enables end-to-end binocular VR rendering without depth estimation or inpainting, enhances embodied policy learning through metric-scale depth grounding, and is compatible with long-video distillation for extended interactive stereo synthesis.
FACE: A Face-based Autoregressive Representation for High-Fidelity and Efficient Mesh Generation
Mar 03, 2026Autoregressive models for 3D mesh generation suffer from a fundamental limitation: they flatten meshes into long vertex-coordinate sequences. This results in prohibitive computational costs, hindering the efficient synthesis of high-fidelity geometry. We argue this bottleneck stems from operating at the wrong semantic level. We introduce FACE, a novel Autoregressive Autoencoder (ARAE) framework that reconceptualizes the task by generating meshes at the face level. Our one-face-one-token strategy treats each triangle face, the fundamental building block of a mesh, as a single, unified token. This simple yet powerful design reduces the sequence length by a factor of nine, leading to an unprecedented compression ratio of 0.11, halving the previous state-of-the-art. This dramatic efficiency gain does not compromise quality; by pairing our face-level decoder with a powerful VecSet encoder, FACE achieves state-of-the-art reconstruction quality on standard benchmarks. The versatility of the learned latent space is further demonstrated by training a latent diffusion model that achieves high-fidelity, single-image-to-mesh generation. FACE provides a simple, scalable, and powerful paradigm that lowers the barrier to high-quality structured 3D content creation.
Skin Tokens: A Learned Compact Representation for Unified Autoregressive Rigging
Feb 04, 2026The rapid proliferation of generative 3D models has created a critical bottleneck in animation pipelines: rigging. Existing automated methods are fundamentally limited by their approach to skinning, treating it as an ill-posed, high-dimensional regression task that is inefficient to optimize and is typically decoupled from skeleton generation. We posit this is a representation problem and introduce SkinTokens: a learned, compact, and discrete representation for skinning weights. By leveraging an FSQ-CVAE to capture the intrinsic sparsity of skinning, we reframe the task from continuous regression to a more tractable token sequence prediction problem. This representation enables TokenRig, a unified autoregressive framework that models the entire rig as a single sequence of skeletal parameters and SkinTokens, learning the complicated dependencies between skeletons and skin deformations. The unified model is then amenable to a reinforcement learning stage, where tailored geometric and semantic rewards improve generalization to complex, out-of-distribution assets. Quantitatively, the SkinTokens representation leads to a 98%-133% percents improvement in skinning accuracy over state-of-the-art methods, while the full TokenRig framework, refined with RL, enhances bone prediction by 17%-22%. Our work presents a unified, generative approach to rigging that yields higher fidelity and robustness, offering a scalable solution to a long-standing challenge in 3D content creation.
Unified Camera Positional Encoding for Controlled Video Generation
Dec 08, 2025Transformers have emerged as a universal backbone across 3D perception, video generation, and world models for autonomous driving and embodied AI, where understanding camera geometry is essential for grounding visual observations in three-dimensional space. However, existing camera encoding methods often rely on simplified pinhole assumptions, restricting generalization across the diverse intrinsics and lens distortions in real-world cameras. We introduce Relative Ray Encoding, a geometry-consistent representation that unifies complete camera information, including 6-DoF poses, intrinsics, and lens distortions. To evaluate its capability under diverse controllability demands, we adopt camera-controlled text-to-video generation as a testbed task. Within this setting, we further identify pitch and roll as two components effective for Absolute Orientation Encoding, enabling full control over the initial camera orientation. Together, these designs form UCPE (Unified Camera Positional Encoding), which integrates into a pretrained video Diffusion Transformer through a lightweight spatial attention adapter, adding less than 1% trainable parameters while achieving state-of-the-art camera controllability and visual fidelity. To facilitate systematic training and evaluation, we construct a large video dataset covering a wide range of camera motions and lens types. Extensive experiments validate the effectiveness of UCPE in camera-controllable video generation and highlight its potential as a general camera representation for Transformers across future multi-view, video, and 3D tasks. Code will be available at https://github.com/chengzhag/UCPE.
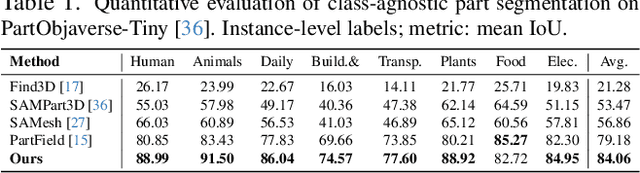
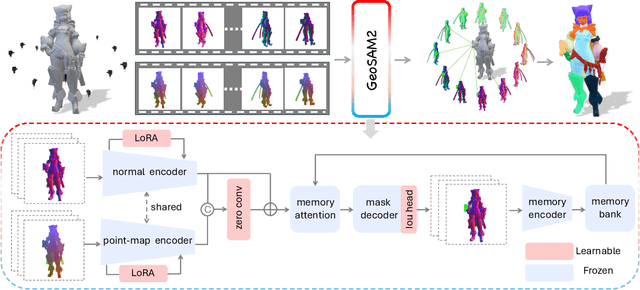
GeoSAM2: Unleashing the Power of SAM2 for 3D Part Segmentation
Aug 19, 2025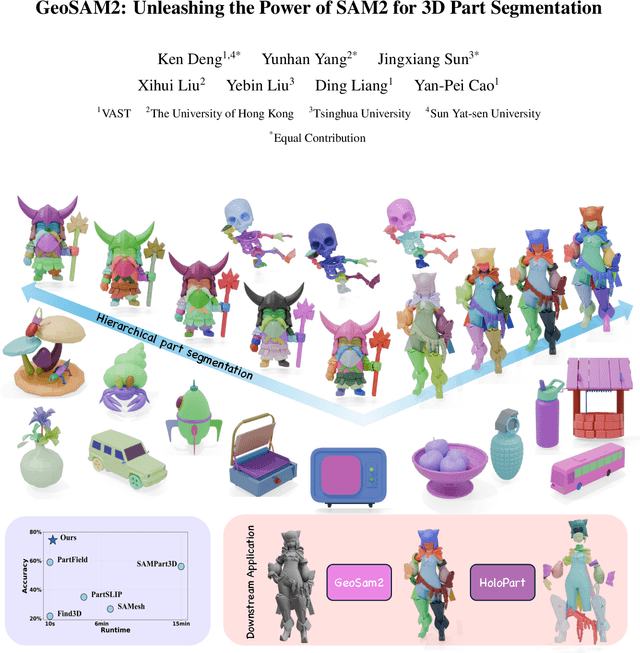

Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.
OmniPart: Part-Aware 3D Generation with Semantic Decoupling and Structural Cohesion
Jul 08, 2025The creation of 3D assets with explicit, editable part structures is crucial for advancing interactive applications, yet most generative methods produce only monolithic shapes, limiting their utility. We introduce OmniPart, a novel framework for part-aware 3D object generation designed to achieve high semantic decoupling among components while maintaining robust structural cohesion. OmniPart uniquely decouples this complex task into two synergistic stages: (1) an autoregressive structure planning module generates a controllable, variable-length sequence of 3D part bounding boxes, critically guided by flexible 2D part masks that allow for intuitive control over part decomposition without requiring direct correspondences or semantic labels; and (2) a spatially-conditioned rectified flow model, efficiently adapted from a pre-trained holistic 3D generator, synthesizes all 3D parts simultaneously and consistently within the planned layout. Our approach supports user-defined part granularity, precise localization, and enables diverse downstream applications. Extensive experiments demonstrate that OmniPart achieves state-of-the-art performance, paving the way for more interpretable, editable, and versatile 3D content.
UniGeo: Taming Video Diffusion for Unified Consistent Geometry Estimation
May 30, 2025Recently, methods leveraging diffusion model priors to assist monocular geometric estimation (e.g., depth and normal) have gained significant attention due to their strong generalization ability. However, most existing works focus on estimating geometric properties within the camera coordinate system of individual video frames, neglecting the inherent ability of diffusion models to determine inter-frame correspondence. In this work, we demonstrate that, through appropriate design and fine-tuning, the intrinsic consistency of video generation models can be effectively harnessed for consistent geometric estimation. Specifically, we 1) select geometric attributes in the global coordinate system that share the same correspondence with video frames as the prediction targets, 2) introduce a novel and efficient conditioning method by reusing positional encodings, and 3) enhance performance through joint training on multiple geometric attributes that share the same correspondence. Our results achieve superior performance in predicting global geometric attributes in videos and can be directly applied to reconstruction tasks. Even when trained solely on static video data, our approach exhibits the potential to generalize to dynamic video scenes.
HoloPart: Generative 3D Part Amodal Segmentation
Apr 10, 20253D part amodal segmentation--decomposing a 3D shape into complete, semantically meaningful parts, even when occluded--is a challenging but crucial task for 3D content creation and understanding. Existing 3D part segmentation methods only identify visible surface patches, limiting their utility. Inspired by 2D amodal segmentation, we introduce this novel task to the 3D domain and propose a practical, two-stage approach, addressing the key challenges of inferring occluded 3D geometry, maintaining global shape consistency, and handling diverse shapes with limited training data. First, we leverage existing 3D part segmentation to obtain initial, incomplete part segments. Second, we introduce HoloPart, a novel diffusion-based model, to complete these segments into full 3D parts. HoloPart utilizes a specialized architecture with local attention to capture fine-grained part geometry and global shape context attention to ensure overall shape consistency. We introduce new benchmarks based on the ABO and PartObjaverse-Tiny datasets and demonstrate that HoloPart significantly outperforms state-of-the-art shape completion methods. By incorporating HoloPart with existing segmentation techniques, we achieve promising results on 3D part amodal segmentation, opening new avenues for applications in geometry editing, animation, and material assignment.
GCRayDiffusion: Pose-Free Surface Reconstruction via Geometric Consistent Ray Diffusion
Mar 28, 2025Accurate surface reconstruction from unposed images is crucial for efficient 3D object or scene creation. However, it remains challenging, particularly for the joint camera pose estimation. Previous approaches have achieved impressive pose-free surface reconstruction results in dense-view settings, but could easily fail for sparse-view scenarios without sufficient visual overlap. In this paper, we propose a new technique for pose-free surface reconstruction, which follows triplane-based signed distance field (SDF) learning but regularizes the learning by explicit points sampled from ray-based diffusion of camera pose estimation. Our key contribution is a novel Geometric Consistent Ray Diffusion model (GCRayDiffusion), where we represent camera poses as neural bundle rays and regress the distribution of noisy rays via a diffusion model. More importantly, we further condition the denoising process of RGRayDiffusion using the triplane-based SDF of the entire scene, which provides effective 3D consistent regularization to achieve multi-view consistent camera pose estimation. Finally, we incorporate RGRayDiffusion into the triplane-based SDF learning by introducing on-surface geometric regularization from the sampling points of the neural bundle rays, which leads to highly accurate pose-free surface reconstruction results even for sparse-view inputs. Extensive evaluations on public datasets show that our GCRayDiffusion achieves more accurate camera pose estimation than previous approaches, with geometrically more consistent surface reconstruction results, especially given sparse-view inputs.
SparseFlex: High-Resolution and Arbitrary-Topology 3D Shape Modeling
Mar 27, 2025Creating high-fidelity 3D meshes with arbitrary topology, including open surfaces and complex interiors, remains a significant challenge. Existing implicit field methods often require costly and detail-degrading watertight conversion, while other approaches struggle with high resolutions. This paper introduces SparseFlex, a novel sparse-structured isosurface representation that enables differentiable mesh reconstruction at resolutions up to $1024^3$ directly from rendering losses. SparseFlex combines the accuracy of Flexicubes with a sparse voxel structure, focusing computation on surface-adjacent regions and efficiently handling open surfaces. Crucially, we introduce a frustum-aware sectional voxel training strategy that activates only relevant voxels during rendering, dramatically reducing memory consumption and enabling high-resolution training. This also allows, for the first time, the reconstruction of mesh interiors using only rendering supervision. Building upon this, we demonstrate a complete shape modeling pipeline by training a variational autoencoder (VAE) and a rectified flow transformer for high-quality 3D shape generation. Our experiments show state-of-the-art reconstruction accuracy, with a ~82% reduction in Chamfer Distance and a ~88% increase in F-score compared to previous methods, and demonstrate the generation of high-resolution, detailed 3D shapes with arbitrary topology. By enabling high-resolution, differentiable mesh reconstruction and generation with rendering losses, SparseFlex significantly advances the state-of-the-art in 3D shape representation and modeling.