 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Apr 13, 2026With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time longform video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder pruning, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2x14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
UniRef-Image-Edit: Towards Scalable and Consistent Multi-Reference Image Editing
Feb 15, 2026We present UniRef-Image-Edit, a high-performance multi-modal generation system that unifies single-image editing and multi-image composition within a single framework. Existing diffusion-based editing methods often struggle to maintain consistency across multiple conditions due to limited interaction between reference inputs. To address this, we introduce Sequence-Extended Latent Fusion (SELF), a unified input representation that dynamically serializes multiple reference images into a coherent latent sequence. During a dedicated training stage, all reference images are jointly constrained to fit within a fixed-length sequence under a global pixel-budget constraint. Building upon SELF, we propose a two-stage training framework comprising supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we jointly train on single-image editing and multi-image composition tasks to establish a robust generative prior. We adopt a progressive sequence length training strategy, in which all input images are initially resized to a total pixel budget of $1024^2$, and are then gradually increased to $1536^2$ and $2048^2$ to improve visual fidelity and cross-reference consistency. This gradual relaxation of compression enables the model to incrementally capture finer visual details while maintaining stable alignment across references. For the RL stage, we introduce Multi-Source GRPO (MSGRPO), to our knowledge the first reinforcement learning framework tailored for multi-reference image generation. MSGRPO optimizes the model to reconcile conflicting visual constraints, significantly enhancing compositional consistency. We will open-source the code, models, training data, and reward data for community research purposes.
Skywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
Faithful Contouring: Near-Lossless 3D Voxel Representation Free from Iso-surface
Nov 12, 2025



Accurate and efficient voxelized representations of 3D meshes are the foundation of 3D reconstruction and generation. However, existing representations based on iso-surface heavily rely on water-tightening or rendering optimization, which inevitably compromise geometric fidelity. We propose Faithful Contouring, a sparse voxelized representation that supports 2048+ resolutions for arbitrary meshes, requiring neither converting meshes to field functions nor extracting the isosurface during remeshing. It achieves near-lossless fidelity by preserving sharpness and internal structures, even for challenging cases with complex geometry and topology. The proposed method also shows flexibility for texturing, manipulation, and editing. Beyond representation, we design a dual-mode autoencoder for Faithful Contouring, enabling scalable and detail-preserving shape reconstruction. Extensive experiments show that Faithful Contouring surpasses existing methods in accuracy and efficiency for both representation and reconstruction. For direct representation, it achieves distance errors at the $10^{-5}$ level; for mesh reconstruction, it yields a 93\% reduction in Chamfer Distance and a 35\% improvement in F-score over strong baselines, confirming superior fidelity as a representation for 3D learning tasks.
NOVA3D: Normal Aligned Video Diffusion Model for Single Image to 3D Generation
Jun 09, 2025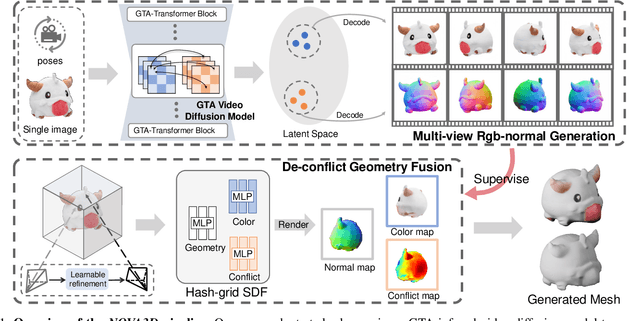
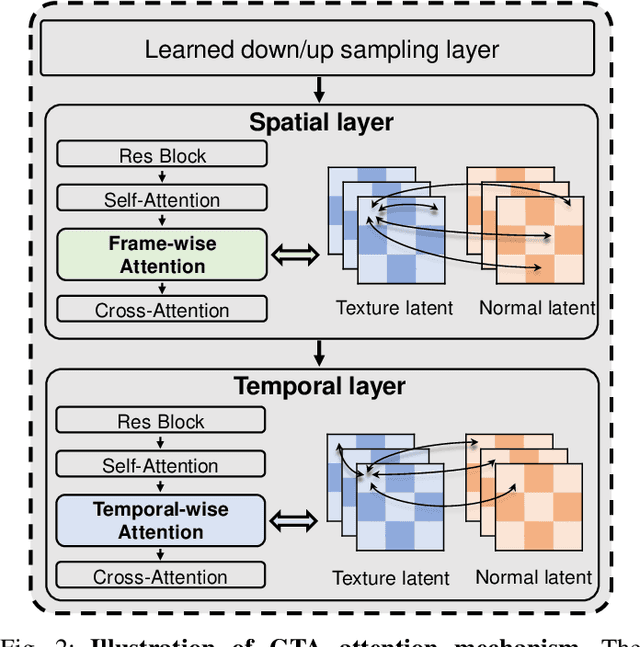


3D AI-generated content (AIGC) has made it increasingly accessible for anyone to become a 3D content creator. While recent methods leverage Score Distillation Sampling to distill 3D objects from pretrained image diffusion models, they often suffer from inadequate 3D priors, leading to insufficient multi-view consistency. In this work, we introduce NOVA3D, an innovative single-image-to-3D generation framework. Our key insight lies in leveraging strong 3D priors from a pretrained video diffusion model and integrating geometric information during multi-view video fine-tuning. To facilitate information exchange between color and geometric domains, we propose the Geometry-Temporal Alignment (GTA) attention mechanism, thereby improving generalization and multi-view consistency. Moreover, we introduce the de-conflict geometry fusion algorithm, which improves texture fidelity by addressing multi-view inaccuracies and resolving discrepancies in pose alignment. Extensive experiments validate the superiority of NOVA3D over existing baselines.
MeshCraft: Exploring Efficient and Controllable Mesh Generation with Flow-based DiTs
Mar 29, 2025In the domain of 3D content creation, achieving optimal mesh topology through AI models has long been a pursuit for 3D artists. Previous methods, such as MeshGPT, have explored the generation of ready-to-use 3D objects via mesh auto-regressive techniques. While these methods produce visually impressive results, their reliance on token-by-token predictions in the auto-regressive process leads to several significant limitations. These include extremely slow generation speeds and an uncontrollable number of mesh faces. In this paper, we introduce MeshCraft, a novel framework for efficient and controllable mesh generation, which leverages continuous spatial diffusion to generate discrete triangle faces. Specifically, MeshCraft consists of two core components: 1) a transformer-based VAE that encodes raw meshes into continuous face-level tokens and decodes them back to the original meshes, and 2) a flow-based diffusion transformer conditioned on the number of faces, enabling the generation of high-quality 3D meshes with a predefined number of faces. By utilizing the diffusion model for the simultaneous generation of the entire mesh topology, MeshCraft achieves high-fidelity mesh generation at significantly faster speeds compared to auto-regressive methods. Specifically, MeshCraft can generate an 800-face mesh in just 3.2 seconds (35$\times$ faster than existing baselines). Extensive experiments demonstrate that MeshCraft outperforms state-of-the-art techniques in both qualitative and quantitative evaluations on ShapeNet dataset and demonstrates superior performance on Objaverse dataset. Moreover, it integrates seamlessly with existing conditional guidance strategies, showcasing its potential to relieve artists from the time-consuming manual work involved in mesh creation.
SparseFlex: High-Resolution and Arbitrary-Topology 3D Shape Modeling
Mar 27, 2025Creating high-fidelity 3D meshes with arbitrary topology, including open surfaces and complex interiors, remains a significant challenge. Existing implicit field methods often require costly and detail-degrading watertight conversion, while other approaches struggle with high resolutions. This paper introduces SparseFlex, a novel sparse-structured isosurface representation that enables differentiable mesh reconstruction at resolutions up to $1024^3$ directly from rendering losses. SparseFlex combines the accuracy of Flexicubes with a sparse voxel structure, focusing computation on surface-adjacent regions and efficiently handling open surfaces. Crucially, we introduce a frustum-aware sectional voxel training strategy that activates only relevant voxels during rendering, dramatically reducing memory consumption and enabling high-resolution training. This also allows, for the first time, the reconstruction of mesh interiors using only rendering supervision. Building upon this, we demonstrate a complete shape modeling pipeline by training a variational autoencoder (VAE) and a rectified flow transformer for high-quality 3D shape generation. Our experiments show state-of-the-art reconstruction accuracy, with a ~82% reduction in Chamfer Distance and a ~88% increase in F-score compared to previous methods, and demonstrate the generation of high-resolution, detailed 3D shapes with arbitrary topology. By enabling high-resolution, differentiable mesh reconstruction and generation with rendering losses, SparseFlex significantly advances the state-of-the-art in 3D shape representation and modeling.
Learn To Learn More Precisely
Aug 08, 2024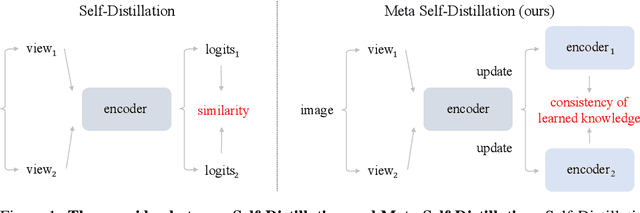
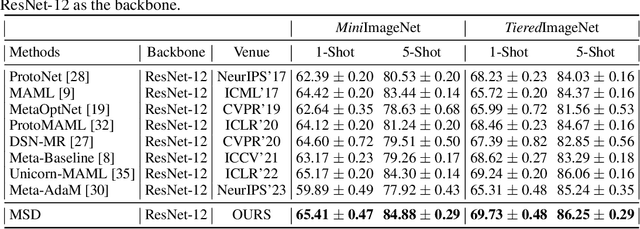
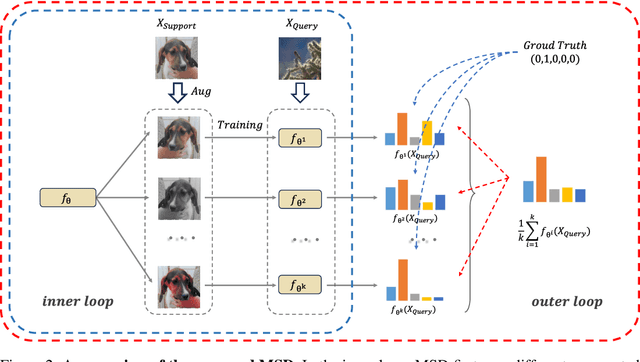
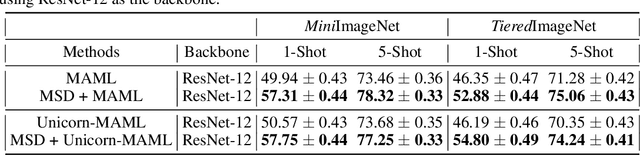
Meta-learning has been extensively applied in the domains of few-shot learning and fast adaptation, achieving remarkable performance. While Meta-learning methods like Model-Agnostic Meta-Learning (MAML) and its variants provide a good set of initial parameters for the model, the model still tends to learn shortcut features, which leads to poor generalization. In this paper, we propose the formal conception of "learn to learn more precisely", which aims to make the model learn precise target knowledge from data and reduce the effect of noisy knowledge, such as background and noise. To achieve this target, we proposed a simple and effective meta-learning framework named Meta Self-Distillation(MSD) to maximize the consistency of learned knowledge, enhancing the models' ability to learn precise target knowledge. In the inner loop, MSD uses different augmented views of the same support data to update the model respectively. Then in the outer loop, MSD utilizes the same query data to optimize the consistency of learned knowledge, enhancing the model's ability to learn more precisely. Our experiment demonstrates that MSD exhibits remarkable performance in few-shot classification tasks in both standard and augmented scenarios, effectively boosting the accuracy and consistency of knowledge learned by the model.
GVGEN: Text-to-3D Generation with Volumetric Representation
Mar 19, 2024



In recent years, 3D Gaussian splatting has emerged as a powerful technique for 3D reconstruction and generation, known for its fast and high-quality rendering capabilities. To address these shortcomings, this paper introduces a novel diffusion-based framework, GVGEN, designed to efficiently generate 3D Gaussian representations from text input. We propose two innovative techniques:(1) Structured Volumetric Representation. We first arrange disorganized 3D Gaussian points as a structured form GaussianVolume. This transformation allows the capture of intricate texture details within a volume composed of a fixed number of Gaussians. To better optimize the representation of these details, we propose a unique pruning and densifying method named the Candidate Pool Strategy, enhancing detail fidelity through selective optimization. (2) Coarse-to-fine Generation Pipeline. To simplify the generation of GaussianVolume and empower the model to generate instances with detailed 3D geometry, we propose a coarse-to-fine pipeline. It initially constructs a basic geometric structure, followed by the prediction of complete Gaussian attributes. Our framework, GVGEN, demonstrates superior performance in qualitative and quantitative assessments compared to existing 3D generation methods. Simultaneously, it maintains a fast generation speed ($\sim$7 seconds), effectively striking a balance between quality and efficiency.
PonderV2: Pave the Way for 3D Foundation Model with A Universal Pre-training Paradigm
Oct 13, 2023
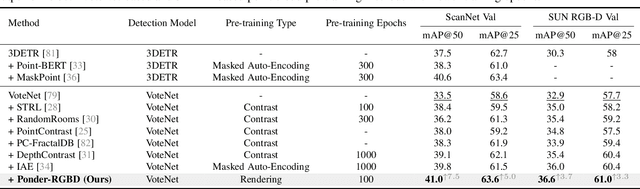
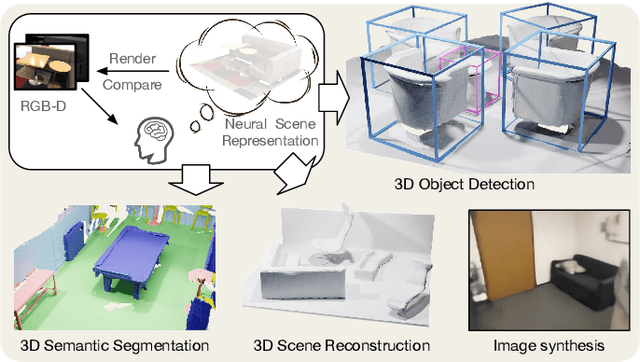

In contrast to numerous NLP and 2D computer vision foundational models, the learning of a robust and highly generalized 3D foundational model poses considerably greater challenges. This is primarily due to the inherent data variability and the diversity of downstream tasks. In this paper, we introduce a comprehensive 3D pre-training framework designed to facilitate the acquisition of efficient 3D representations, thereby establishing a pathway to 3D foundational models. Motivated by the fact that informative 3D features should be able to encode rich geometry and appearance cues that can be utilized to render realistic images, we propose a novel universal paradigm to learn point cloud representations by differentiable neural rendering, serving as a bridge between 3D and 2D worlds. We train a point cloud encoder within a devised volumetric neural renderer by comparing the rendered images with the real images. Notably, our approach demonstrates the seamless integration of the learned 3D encoder into diverse downstream tasks. These tasks encompass not only high-level challenges such as 3D detection and segmentation but also low-level objectives like 3D reconstruction and image synthesis, spanning both indoor and outdoor scenarios. Besides, we also illustrate the capability of pre-training a 2D backbone using the proposed universal methodology, surpassing conventional pre-training methods by a large margin. For the first time, PonderV2 achieves state-of-the-art performance on 11 indoor and outdoor benchmarks. The consistent improvements in various settings imply the effectiveness of the proposed method. Code and models will be made available at https://github.com/OpenGVLab/PonderV2.