 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhoever Started the Interference Should End It: Guiding Data-Free Model Merging via Task Vectors
Mar 11, 2025



Model merging seeks to integrate task-specific expert models into a unified architecture while preserving multi-task generalization capabilities, yet parameter interference between constituent models frequently induces performance degradation. Although prior work has explored many merging strategies, resolving interference without additional data for retraining or test-time computation remains challenging. In this paper, we theoretically demonstrate that the task vectors of the linear layer constitute an approximate linear subspace for its corresponding input. Therefore, we can minimize interference under the guidance of task vectors. Based on this insight, we propose \textbf{WUDI-Merging} (\textbf{W}hoever started the interference sho\textbf{U}ld en\textbf{D} \textbf{I}t), a simple yet effective model merging method that eliminates interference without any additional data or rescaling coefficients. Comprehensive empirical evaluations across vision and language benchmarks demonstrate our method's superiority, achieving state-of-the-art performance in data-free model merging scenarios (average 10.9\% improvement versus baseline methods) while even outperforming mainstream test-time adaptation approaches by 3.3\%, and only very few computing resources are required. The code will be publicly available soon.
Learn To Learn More Precisely
Aug 08, 2024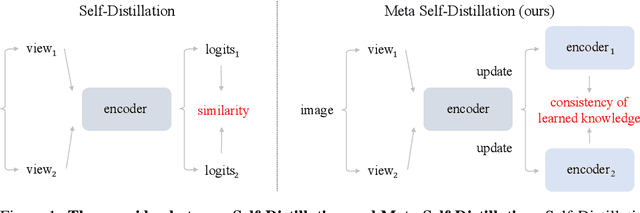
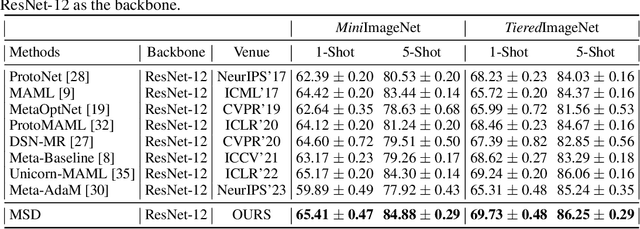
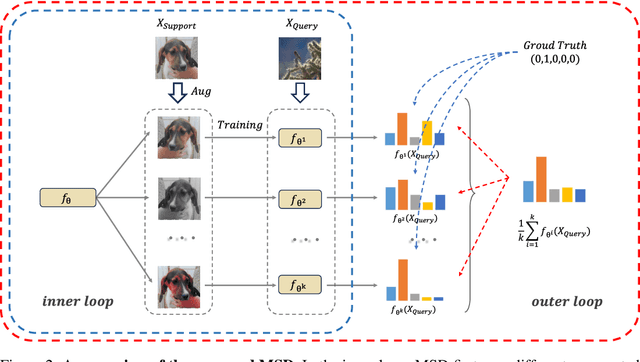
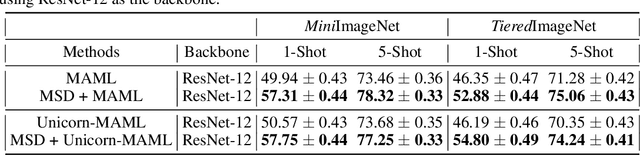
Meta-learning has been extensively applied in the domains of few-shot learning and fast adaptation, achieving remarkable performance. While Meta-learning methods like Model-Agnostic Meta-Learning (MAML) and its variants provide a good set of initial parameters for the model, the model still tends to learn shortcut features, which leads to poor generalization. In this paper, we propose the formal conception of "learn to learn more precisely", which aims to make the model learn precise target knowledge from data and reduce the effect of noisy knowledge, such as background and noise. To achieve this target, we proposed a simple and effective meta-learning framework named Meta Self-Distillation(MSD) to maximize the consistency of learned knowledge, enhancing the models' ability to learn precise target knowledge. In the inner loop, MSD uses different augmented views of the same support data to update the model respectively. Then in the outer loop, MSD utilizes the same query data to optimize the consistency of learned knowledge, enhancing the model's ability to learn more precisely. Our experiment demonstrates that MSD exhibits remarkable performance in few-shot classification tasks in both standard and augmented scenarios, effectively boosting the accuracy and consistency of knowledge learned by the model.