 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGDMRec: Behavior Conditioned Item Graph Diffusion for Multimodal Recommendation
Dec 23, 2025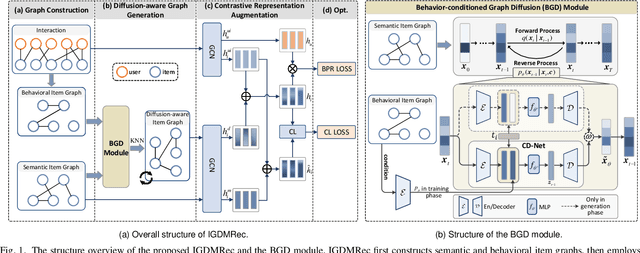
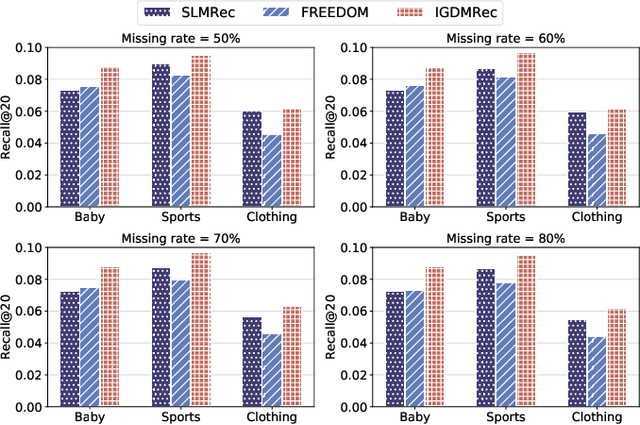
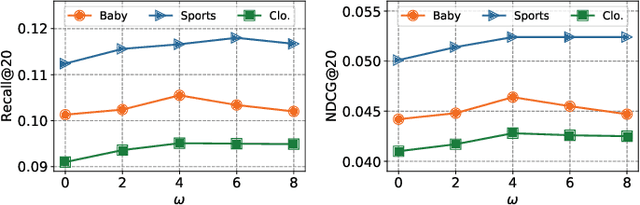
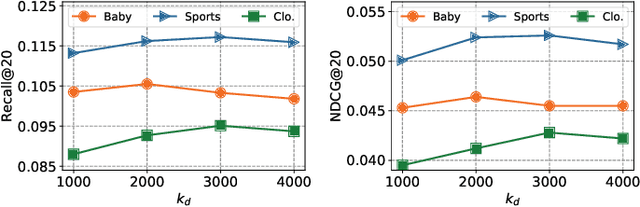
Multimodal recommender systems (MRSs) are critical for various online platforms, offering users more accurate personalized recommendations by incorporating multimodal information of items. Structure-based MRSs have achieved state-of-the-art performance by constructing semantic item graphs, which explicitly model relationships between items based on modality feature similarity. However, such semantic item graphs are often noisy due to 1) inherent noise in multimodal information and 2) misalignment between item semantics and user-item co-occurrence relationships, which introduces false links and leads to suboptimal recommendations. To address this challenge, we propose Item Graph Diffusion for Multimodal Recommendation (IGDMRec), a novel method that leverages a diffusion model with classifier-free guidance to denoise the semantic item graph by integrating user behavioral information. Specifically, IGDMRec introduces a Behavior-conditioned Graph Diffusion (BGD) module, incorporating interaction data as conditioning information to guide the denoising of the semantic item graph. Additionally, a Conditional Denoising Network (CD-Net) is designed to implement the denoising process with manageable complexity. Finally, we propose a contrastive representation augmentation scheme that leverages both the denoised item graph and the original item graph to enhance item representations. \LL{Extensive experiments on four real-world datasets demonstrate the superiority of IGDMRec over competitive baselines, with robustness analysis validating its denoising capability and ablation studies verifying the effectiveness of its key components.
VSE-MOT: Multi-Object Tracking in Low-Quality Video Scenes Guided by Visual Semantic Enhancement
Sep 17, 2025Current multi-object tracking (MOT) algorithms typically overlook issues inherent in low-quality videos, leading to significant degradation in tracking performance when confronted with real-world image deterioration. Therefore, advancing the application of MOT algorithms in real-world low-quality video scenarios represents a critical and meaningful endeavor. To address the challenges posed by low-quality scenarios, inspired by vision-language models, this paper proposes a Visual Semantic Enhancement-guided Multi-Object Tracking framework (VSE-MOT). Specifically, we first design a tri-branch architecture that leverages a vision-language model to extract global visual semantic information from images and fuse it with query vectors. Subsequently, to further enhance the utilization of visual semantic information, we introduce the Multi-Object Tracking Adapter (MOT-Adapter) and the Visual Semantic Fusion Module (VSFM). The MOT-Adapter adapts the extracted global visual semantic information to suit multi-object tracking tasks, while the VSFM improves the efficacy of feature fusion. Through extensive experiments, we validate the effectiveness and superiority of the proposed method in real-world low-quality video scenarios. Its tracking performance metrics outperform those of existing methods by approximately 8% to 20%, while maintaining robust performance in conventional scenarios.
Human Motion Video Generation: A Survey
Sep 04, 2025Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.
* Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
SceneRAG: Scene-level Retrieval-Augmented Generation for Video Understanding
Jun 09, 2025



Despite recent advances in retrieval-augmented generation (RAG) for video understanding, effectively understanding long-form video content remains underexplored due to the vast scale and high complexity of video data. Current RAG approaches typically segment videos into fixed-length chunks, which often disrupts the continuity of contextual information and fails to capture authentic scene boundaries. Inspired by the human ability to naturally organize continuous experiences into coherent scenes, we present SceneRAG, a unified framework that leverages large language models to segment videos into narrative-consistent scenes by processing ASR transcripts alongside temporal metadata. SceneRAG further sharpens these initial boundaries through lightweight heuristics and iterative correction. For each scene, the framework fuses information from both visual and textual modalities to extract entity relations and dynamically builds a knowledge graph, enabling robust multi-hop retrieval and generation that account for long-range dependencies. Experiments on the LongerVideos benchmark, featuring over 134 hours of diverse content, confirm that SceneRAG substantially outperforms prior baselines, achieving a win rate of up to 72.5 percent on generation tasks.
Universal Visuo-Tactile Video Understanding for Embodied Interaction
May 28, 2025



Tactile perception is essential for embodied agents to understand physical attributes of objects that cannot be determined through visual inspection alone. While existing approaches have made progress in visual and language modalities for physical understanding, they fail to effectively incorporate tactile information that provides crucial haptic feedback for real-world interaction. In this paper, we present VTV-LLM, the first multi-modal large language model for universal Visuo-Tactile Video (VTV) understanding that bridges the gap between tactile perception and natural language. To address the challenges of cross-sensor and cross-modal integration, we contribute VTV150K, a comprehensive dataset comprising 150,000 video frames from 100 diverse objects captured across three different tactile sensors (GelSight Mini, DIGIT, and Tac3D), annotated with four fundamental tactile attributes (hardness, protrusion, elasticity, and friction). We develop a novel three-stage training paradigm that includes VTV enhancement for robust visuo-tactile representation, VTV-text alignment for cross-modal correspondence, and text prompt finetuning for natural language generation. Our framework enables sophisticated tactile reasoning capabilities including feature assessment, comparative analysis, scenario-based decision making and so on. Experimental evaluations demonstrate that VTV-LLM achieves superior performance in tactile video understanding tasks, establishing a foundation for more intuitive human-machine interaction in tactile domains.
Safe-Sora: Safe Text-to-Video Generation via Graphical Watermarking
May 19, 2025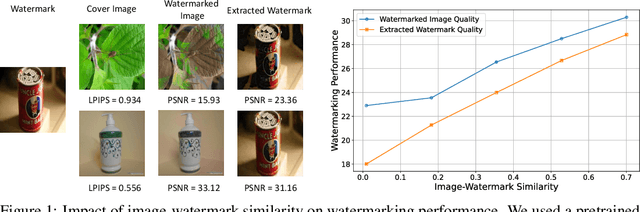
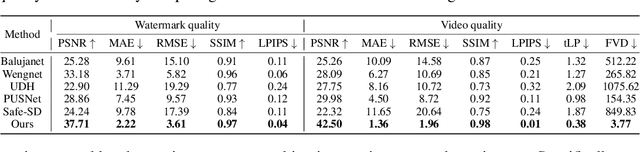
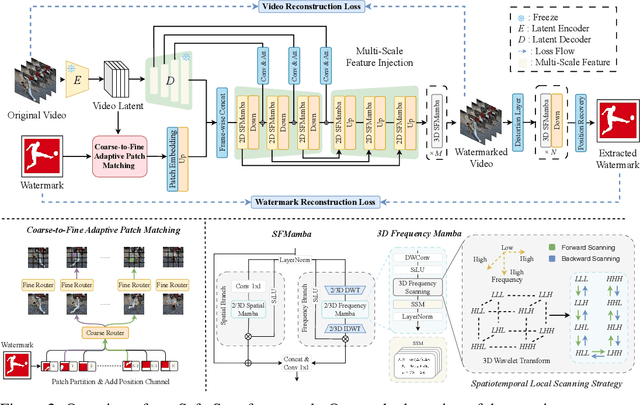

The explosive growth of generative video models has amplified the demand for reliable copyright preservation of AI-generated content. Despite its popularity in image synthesis, invisible generative watermarking remains largely underexplored in video generation. To address this gap, we propose Safe-Sora, the first framework to embed graphical watermarks directly into the video generation process. Motivated by the observation that watermarking performance is closely tied to the visual similarity between the watermark and cover content, we introduce a hierarchical coarse-to-fine adaptive matching mechanism. Specifically, the watermark image is divided into patches, each assigned to the most visually similar video frame, and further localized to the optimal spatial region for seamless embedding. To enable spatiotemporal fusion of watermark patches across video frames, we develop a 3D wavelet transform-enhanced Mamba architecture with a novel spatiotemporal local scanning strategy, effectively modeling long-range dependencies during watermark embedding and retrieval. To the best of our knowledge, this is the first attempt to apply state space models to watermarking, opening new avenues for efficient and robust watermark protection. Extensive experiments demonstrate that Safe-Sora achieves state-of-the-art performance in terms of video quality, watermark fidelity, and robustness, which is largely attributed to our proposals. We will release our code upon publication.
RWKV-X: A Linear Complexity Hybrid Language Model
Apr 30, 2025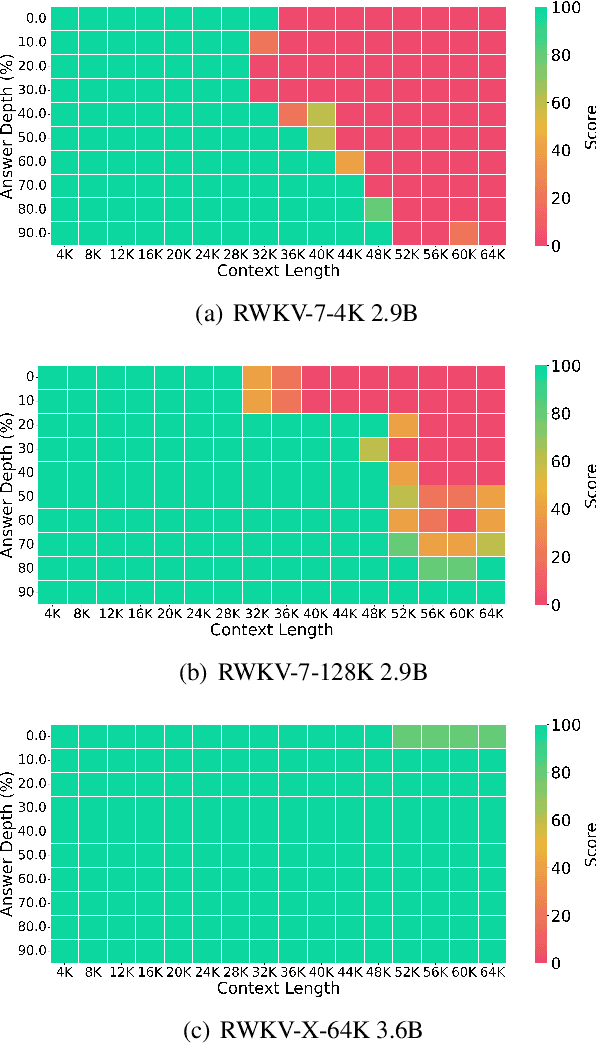
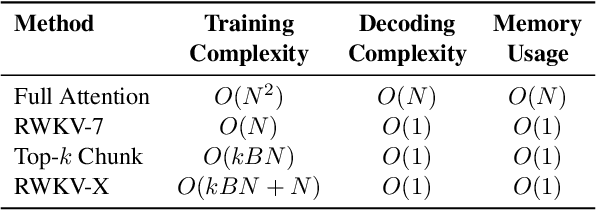
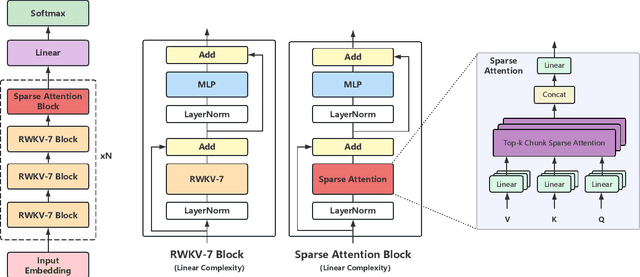
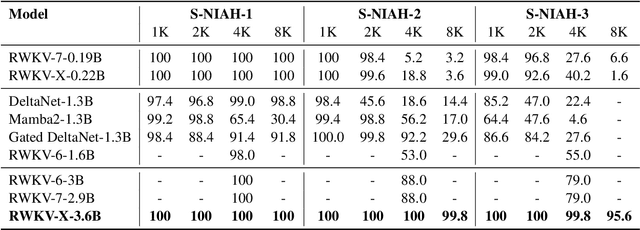
In this paper, we introduce \textbf{RWKV-X}, a novel hybrid architecture that combines the efficiency of RWKV for short-range modeling with a sparse attention mechanism designed to capture long-range context. Unlike previous hybrid approaches that rely on full attention layers and retain quadratic complexity, RWKV-X achieves linear-time complexity in training and constant-time complexity in inference decoding. We demonstrate that RWKV-X, when continually pretrained on 64K-token sequences, achieves near-perfect accuracy on the 64K passkey retrieval benchmark. It consistently outperforms prior RWKV-7 models on long-context benchmarks, while maintaining strong performance on short-context tasks. These results highlight RWKV-X as a scalable and efficient backbone for general-purpose language modeling, capable of decoding sequences up to 1 million tokens with stable speed and memory usage. To facilitate further research and analysis, we have made the checkpoints and the associated code publicly accessible at: https://github.com/howard-hou/RWKV-X.
Safe-VAR: Safe Visual Autoregressive Model for Text-to-Image Generative Watermarking
Mar 14, 2025With the success of autoregressive learning in large language models, it has become a dominant approach for text-to-image generation, offering high efficiency and visual quality. However, invisible watermarking for visual autoregressive (VAR) models remains underexplored, despite its importance in misuse prevention. Existing watermarking methods, designed for diffusion models, often struggle to adapt to the sequential nature of VAR models. To bridge this gap, we propose Safe-VAR, the first watermarking framework specifically designed for autoregressive text-to-image generation. Our study reveals that the timing of watermark injection significantly impacts generation quality, and watermarks of different complexities exhibit varying optimal injection times. Motivated by this observation, we propose an Adaptive Scale Interaction Module, which dynamically determines the optimal watermark embedding strategy based on the watermark information and the visual characteristics of the generated image. This ensures watermark robustness while minimizing its impact on image quality. Furthermore, we introduce a Cross-Scale Fusion mechanism, which integrates mixture of both heads and experts to effectively fuse multi-resolution features and handle complex interactions between image content and watermark patterns. Experimental results demonstrate that Safe-VAR achieves state-of-the-art performance, significantly surpassing existing counterparts regarding image quality, watermarking fidelity, and robustness against perturbations. Moreover, our method exhibits strong generalization to an out-of-domain watermark dataset QR Codes.
CLIP-Optimized Multimodal Image Enhancement via ISP-CNN Fusion for Coal Mine IoVT under Uneven Illumination
Feb 26, 2025Clear monitoring images are crucial for the safe operation of coal mine Internet of Video Things (IoVT) systems. However, low illumination and uneven brightness in underground environments significantly degrade image quality, posing challenges for enhancement methods that often rely on difficult-to-obtain paired reference images. Additionally, there is a trade-off between enhancement performance and computational efficiency on edge devices within IoVT systems.To address these issues, we propose a multimodal image enhancement method tailored for coal mine IoVT, utilizing an ISP-CNN fusion architecture optimized for uneven illumination. This two-stage strategy combines global enhancement with detail optimization, effectively improving image quality, especially in poorly lit areas. A CLIP-based multimodal iterative optimization allows for unsupervised training of the enhancement algorithm. By integrating traditional image signal processing (ISP) with convolutional neural networks (CNN), our approach reduces computational complexity while maintaining high performance, making it suitable for real-time deployment on edge devices.Experimental results demonstrate that our method effectively mitigates uneven brightness and enhances key image quality metrics, with PSNR improvements of 2.9%-4.9%, SSIM by 4.3%-11.4%, and VIF by 4.9%-17.8% compared to seven state-of-the-art algorithms. Simulated coal mine monitoring scenarios validate our method's ability to balance performance and computational demands, facilitating real-time enhancement and supporting safer mining operations.
Exploring Embodied Multimodal Large Models: Development, Datasets, and Future Directions
Feb 21, 2025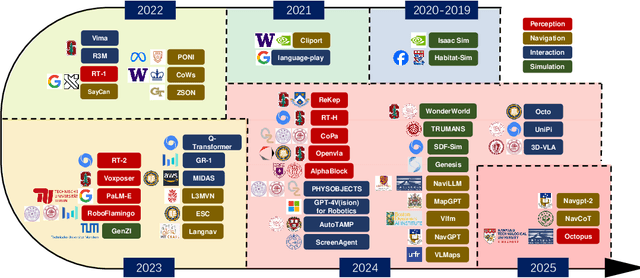
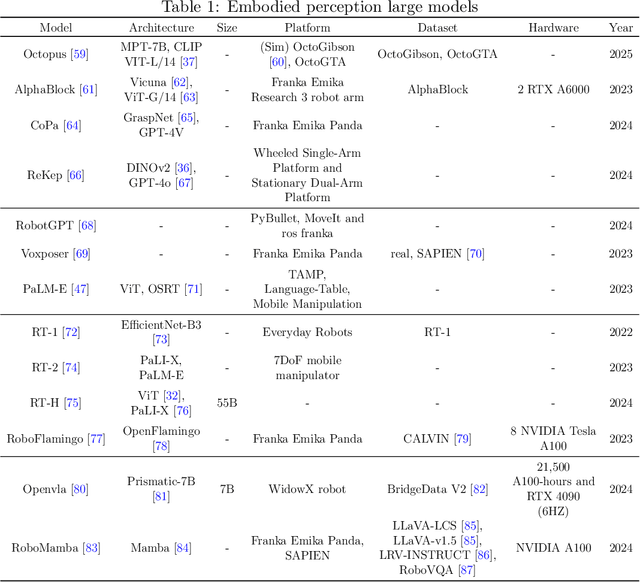

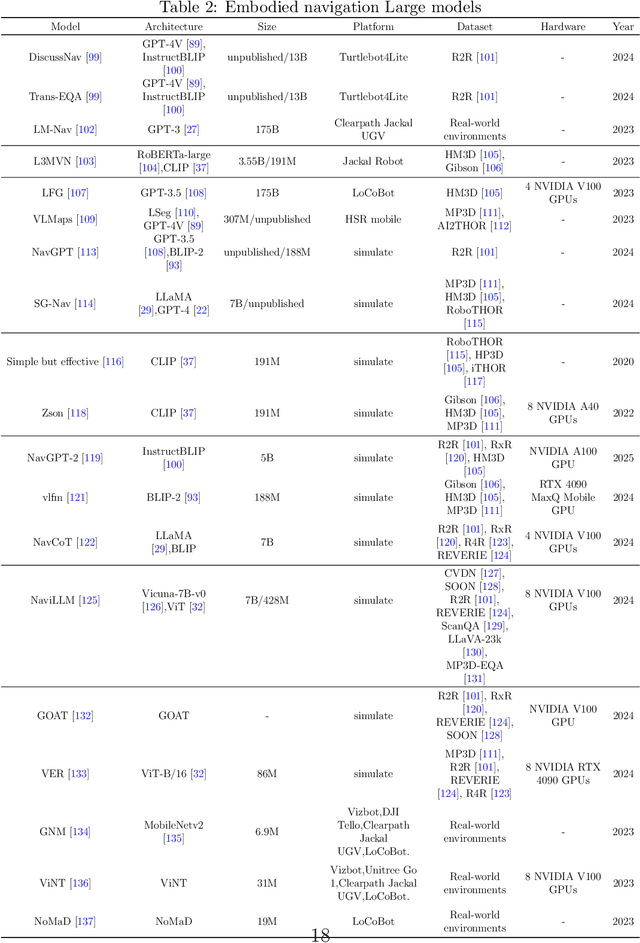
Embodied multimodal large models (EMLMs) have gained significant attention in recent years due to their potential to bridge the gap between perception, cognition, and action in complex, real-world environments. This comprehensive review explores the development of such models, including Large Language Models (LLMs), Large Vision Models (LVMs), and other models, while also examining other emerging architectures. We discuss the evolution of EMLMs, with a focus on embodied perception, navigation, interaction, and simulation. Furthermore, the review provides a detailed analysis of the datasets used for training and evaluating these models, highlighting the importance of diverse, high-quality data for effective learning. The paper also identifies key challenges faced by EMLMs, including issues of scalability, generalization, and real-time decision-making. Finally, we outline future directions, emphasizing the integration of multimodal sensing, reasoning, and action to advance the development of increasingly autonomous systems. By providing an in-depth analysis of state-of-the-art methods and identifying critical gaps, this paper aims to inspire future advancements in EMLMs and their applications across diverse domains.