 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Cloud-Edge-Terminal Collaborative Intelligence in AIoT Networks
Aug 26, 2025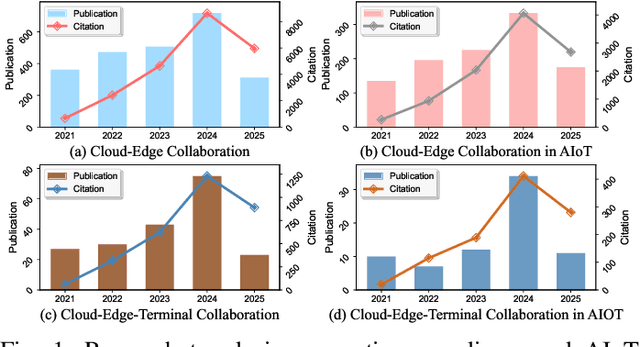
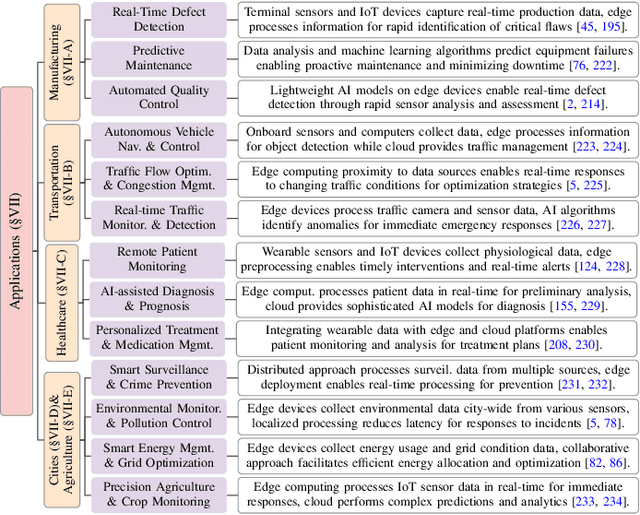
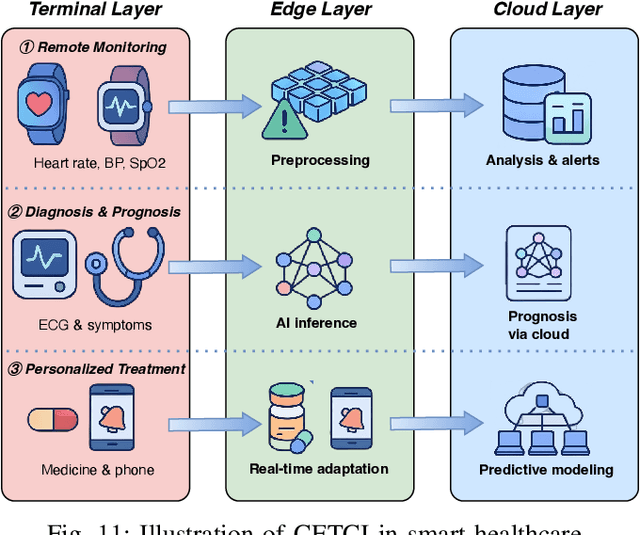
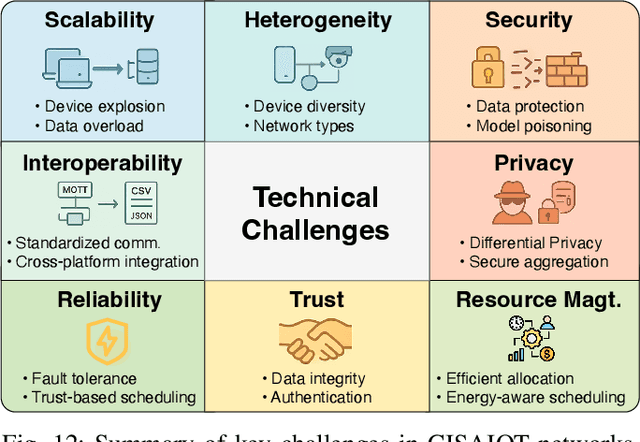
The proliferation of Internet of things (IoT) devices in smart cities, transportation, healthcare, and industrial applications, coupled with the explosive growth of AI-driven services, has increased demands for efficient distributed computing architectures and networks, driving cloud-edge-terminal collaborative intelligence (CETCI) as a fundamental paradigm within the artificial intelligence of things (AIoT) community. With advancements in deep learning, large language models (LLMs), and edge computing, CETCI has made significant progress with emerging AIoT applications, moving beyond isolated layer optimization to deployable collaborative intelligence systems for AIoT (CISAIOT), a practical research focus in AI, distributed computing, and communications. This survey describes foundational architectures, enabling technologies, and scenarios of CETCI paradigms, offering a tutorial-style review for CISAIOT beginners. We systematically analyze architectural components spanning cloud, edge, and terminal layers, examining core technologies including network virtualization, container orchestration, and software-defined networking, while presenting categorizations of collaboration paradigms that cover task offloading, resource allocation, and optimization across heterogeneous infrastructures. Furthermore, we explain intelligent collaboration learning frameworks by reviewing advances in federated learning, distributed deep learning, edge-cloud model evolution, and reinforcement learning-based methods. Finally, we discuss challenges (e.g., scalability, heterogeneity, interoperability) and future trends (e.g., 6G+, agents, quantum computing, digital twin), highlighting how integration of distributed computing and communication can address open issues and guide development of robust, efficient, and secure collaborative AIoT systems.
CLIP-Optimized Multimodal Image Enhancement via ISP-CNN Fusion for Coal Mine IoVT under Uneven Illumination
Feb 26, 2025Clear monitoring images are crucial for the safe operation of coal mine Internet of Video Things (IoVT) systems. However, low illumination and uneven brightness in underground environments significantly degrade image quality, posing challenges for enhancement methods that often rely on difficult-to-obtain paired reference images. Additionally, there is a trade-off between enhancement performance and computational efficiency on edge devices within IoVT systems.To address these issues, we propose a multimodal image enhancement method tailored for coal mine IoVT, utilizing an ISP-CNN fusion architecture optimized for uneven illumination. This two-stage strategy combines global enhancement with detail optimization, effectively improving image quality, especially in poorly lit areas. A CLIP-based multimodal iterative optimization allows for unsupervised training of the enhancement algorithm. By integrating traditional image signal processing (ISP) with convolutional neural networks (CNN), our approach reduces computational complexity while maintaining high performance, making it suitable for real-time deployment on edge devices.Experimental results demonstrate that our method effectively mitigates uneven brightness and enhances key image quality metrics, with PSNR improvements of 2.9%-4.9%, SSIM by 4.3%-11.4%, and VIF by 4.9%-17.8% compared to seven state-of-the-art algorithms. Simulated coal mine monitoring scenarios validate our method's ability to balance performance and computational demands, facilitating real-time enhancement and supporting safer mining operations.
Efficient Detection Framework Adaptation for Edge Computing: A Plug-and-play Neural Network Toolbox Enabling Edge Deployment
Dec 24, 2024Edge computing has emerged as a key paradigm for deploying deep learning-based object detection in time-sensitive scenarios. However, existing edge detection methods face challenges: 1) difficulty balancing detection precision with lightweight models, 2) limited adaptability of generalized deployment designs, and 3) insufficient real-world validation. To address these issues, we propose the Edge Detection Toolbox (ED-TOOLBOX), which utilizes generalizable plug-and-play components to adapt object detection models for edge environments. Specifically, we introduce a lightweight Reparameterized Dynamic Convolutional Network (Rep-DConvNet) featuring weighted multi-shape convolutional branches to enhance detection performance. Additionally, we design a Sparse Cross-Attention (SC-A) network with a localized-mapping-assisted self-attention mechanism, enabling a well-crafted joint module for adaptive feature transfer. For real-world applications, we incorporate an Efficient Head into the YOLO framework to accelerate edge model optimization. To demonstrate practical impact, we identify a gap in helmet detection -- overlooking band fastening, a critical safety factor -- and create the Helmet Band Detection Dataset (HBDD). Using ED-TOOLBOX-optimized models, we address this real-world task. Extensive experiments validate the effectiveness of ED-TOOLBOX, with edge detection models outperforming six state-of-the-art methods in visual surveillance simulations, achieving real-time and accurate performance. These results highlight ED-TOOLBOX as a superior solution for edge object detection.
FedDTPT: Federated Discrete and Transferable Prompt Tuning for Black-Box Large Language Models
Nov 01, 2024In recent years, large language models (LLMs) have significantly advanced the field of natural language processing (NLP). By fine-tuning LLMs with data from specific scenarios, these foundation models can better adapt to various downstream tasks. However, the fine-tuning process poses privacy leakage risks, particularly in centralized data processing scenarios. To address user privacy concerns, federated learning (FL) has been introduced to mitigate the risks associated with centralized data collection from multiple sources. Nevertheless, the privacy of LLMs themselves is equally critical, as potential malicious attacks challenge their security, an issue that has received limited attention in current research. Consequently, establishing a trusted multi-party model fine-tuning environment is essential. Additionally, the local deployment of large LLMs incurs significant storage costs and high computational demands. To address these challenges, we propose for the first time a federated discrete and transferable prompt tuning, namely FedDTPT, for black-box large language models. In the client optimization phase, we adopt a token-level discrete prompt optimization method that leverages a feedback loop based on prediction accuracy to drive gradient-free prompt optimization through the MLM API. For server optimization, we employ an attention mechanism based on semantic similarity to filter all local prompt tokens, along with an embedding distance elbow detection and DBSCAN clustering strategy to enhance the filtering process. Experimental results demonstrate that, compared to state-of-the-art methods, our approach achieves higher accuracy, reduced communication overhead, and robustness to non-iid data in a black-box setting. Moreover, the optimized prompts are transferable.
Task-Oriented Real-time Visual Inference for IoVT Systems: A Co-design Framework of Neural Networks and Edge Deployment
Oct 29, 2024As the volume of image data grows, data-oriented cloud computing in Internet of Video Things (IoVT) systems encounters latency issues. Task-oriented edge computing addresses this by shifting data analysis to the edge. However, limited computational power of edge devices poses challenges for executing visual tasks. Existing methods struggle to balance high model performance with low resource consumption; lightweight neural networks often underperform, while device-specific models designed by Neural Architecture Search (NAS) fail to adapt to heterogeneous devices. For these issues, we propose a novel co-design framework to optimize neural network architecture and deployment strategies during inference for high-throughput. Specifically, it implements a dynamic model structure based on re-parameterization, coupled with a Roofline-based model partitioning strategy to enhance the computational performance of edge devices. We also employ a multi-objective co-optimization approach to balance throughput and accuracy. Additionally, we derive mathematical consistency and convergence of partitioned models. Experimental results demonstrate significant improvements in throughput (12.05\% on MNIST, 18.83\% on ImageNet) and superior classification accuracy compared to baseline algorithms. Our method consistently achieves stable performance across different devices, underscoring its adaptability. Simulated experiments further confirm its efficacy in high-accuracy, real-time detection for small objects in IoVT systems.