 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Forger Is the Judge: GPT-Image-2 Cannot Recognize Its Own Faked Documents
Apr 28, 2026OpenAI's GPT-Image-2 has effectively erased the visual boundary between authentic and AI-edited document images: a single number on a receipt can be replaced in under a second for a few cents. We release AIForge-Doc v2, a paired dataset of 3,066 GPT-Image-2 document forgeries with pixel-precise masks in DocTamper-compatible format, and benchmark four lines of defence: human inspectors (N=120, n=365 pair-votes via the public 2AFC site CanUSpotAI.com), TruFor (generic forensic), DocTamper (qcf-568, document-specific), and the same GPT-Image-2 model as a zero-shot self-judge -- asked, to avoid the trivial "image is mostly real" reading, whether any region was generated or edited by an AI image model. Human 2AFC accuracy is 0.501, indistinguishable from chance: even side-by-side, inspectors cannot tell GPT-Image-2 receipt forgeries from authentic counterparts. The three computational judges sit only modestly above (TruFor 0.599, DocTamper 0.585, self-judge 0.532). The self-judge fails consistently, not by chance: across five prompt strategies and four policies for handling ambiguous responses, AUC never rises above 0.59. To rule out the possibility that the two forensic detectors are broken on our source domain rather than blind to AI inpainting, we calibrate each on a same-domain traditional-tampering set built for its training distribution: TruFor reaches AUC 0.962 on cross-camera splicing of our dataset, DocTamper reaches 0.852 on cross-document OCR-token splicing with two-pass JPEG re-encoding. Both retain near-published performance on traditional tampering; switching to GPT-Image-2 inpainting drops AUC by 0.27-0.36 (0.962->0.599 TruFor; 0.852->0.585 DocTamper), isolating a detection gap specific to GPT-Image-2 inpainting. We release the dataset, pipeline, four-judge protocol, and calibration sets.
Bridging the RGB-IR Gap: Consensus and Discrepancy Modeling for Text-Guided Multispectral Detection
Apr 13, 2026Text-guided multispectral object detection uses text semantics to guide semantic-aware cross-modal interaction between RGB and IR for more robust perception. However, notable limitations remain: (1) existing methods often use text only as an auxiliary semantic enhancement signal, without exploiting its guiding role to bridge the inherent granularity asymmetry between RGB and IR; and (2) conventional data-driven attention-based fusion tends to emphasize stable consensus while overlooking potentially valuable cross-modal discrepancies. To address these issues, we propose a semantic bridge fusion framework with bi-support modeling for multispectral object detection. Specifically, text is used as a shared semantic bridge to align RGB and IR responses under a unified category condition, while the recalibrated thermal semantic prior is projected onto the RGB branch for semantic-level mapping fusion. We further formulate RGB-IR interaction evidence into the regular consensus support and the complementary discrepancy support that contains potentially discriminative cues, and introduce them into fusion via dynamic recalibration as a structured inductive bias. In addition, we design a bidirectional semantic alignment module for closed-loop vision-text guidance enhancement. Extensive experiments demonstrate the effectiveness of the proposed fusion framework and its superior detection performance on multispectral benchmarks. Code is available at https://github.com/zhenwang5372/Bridging-RGB-IR-Gap.
Hitem3D 2.0: Multi-View Guided Native 3D Texture Generation
Apr 10, 2026Although recent advances have improved the quality of 3D texture generation, existing methods still struggle with incomplete texture coverage, cross-view inconsistency, and misalignment between geometry and texture. To address these limitations, we propose Hitem3D 2.0, a multi-view guided native 3D texture generation framework that enhances texture quality through the integration of 2D multi-view generation priors and native 3D texture representations. Hitem3D 2.0 comprises two key components: a multi-view synthesis framework and a native 3D texture generation model. The multi-view generation is built upon a pre-trained image editing backbone and incorporates plug-and-play modules that explicitly promote geometric alignment, cross-view consistency, and illumination uniformity, thereby enabling the synthesis of high-fidelity multi-view images. Conditioned on the generated views and 3D geometry, the native 3D texture generation model projects multi-view textures onto 3D surfaces while plausibly completing textures in unseen regions. Through the integration of multi-view consistency constraints with native 3D texture modeling, Hitem3D 2.0 significantly improves texture completeness, cross-view coherence, and geometric alignment. Experimental results demonstrate that Hitem3D 2.0 outperforms existing methods in terms of texture detail, fidelity, consistency, coherence, and alignment.
Structure-Aware Commitment Reduction for Network-Constrained Unit Commitment with Solver-Preserving Guarantees
Apr 03, 2026The growing number of individual generating units, hybrid resources, and security constraints has significantly increased the computational burden of network-constrained unit commitment (UC), where most solution time is spent exploring branch-and-bound trees over unit-hour binary variables. To reduce this combinatorial burden, recent approaches have explored learning-based guidance to assist commitment decisions. However, directly using tools such as large language models (LLMs) to predict full commitment schedules is unreliable, as infeasible or inconsistent binary decisions can violate inter-temporal constraints and degrade economic optimality. This paper proposes a solver-compatible dimensionality reduction framework for UC that exploits structural regularities in commitment decisions. Instead of generating complete schedules, the framework identifies a sparse subset of structurally stable commitment binaries to fix prior to optimization. One implementation uses an LLM to select these variables. The LLM does not replace the optimization process but provides partial variable restriction, while all constraints and remaining decisions are handled by the original MILP solver, which continues to enforce network, ramping, reserve, and security constraints. We formally show that the masked problem defines a reduced feasible region of the original UC model, thereby preserving feasibility and enabling solver-certified optimality within the restricted space. Experiments on IEEE 57-bus, RTS 73-bus, IEEE 118-bus, and augmented large-scale cases, including security-constrained variants, demonstrate consistent reductions in branch-and-bound nodes and solution time, achieving order-of-magnitude speedups on high-complexity instances while maintaining near-optimal objective values.
Differentially Private Manifold Denoising
Apr 01, 2026We introduce a differentially private manifold denoising framework that allows users to exploit sensitive reference datasets to correct noisy, non-private query points without compromising privacy. The method follows an iterative procedure that (i) privately estimates local means and tangent geometry using the reference data under calibrated sensitivity, (ii) projects query points along the privately estimated subspace toward the local mean via corrective steps at each iteration, and (iii) performs rigorous privacy accounting across iterations and queries using $(\varepsilon,δ)$-differential privacy (DP). Conceptually, this framework brings differential privacy to manifold methods, retaining sufficient geometric signal for downstream tasks such as embedding, clustering, and visualization, while providing formal DP guarantees for the reference data. Practically, the procedure is modular and scalable, separating DP-protected local geometry (means and tangents) from budgeted query-point updates, with a simple scheduler allocating privacy budget across iterations and queries. Under standard assumptions on manifold regularity, sampling density, and measurement noise, we establish high-probability utility guarantees showing that corrected queries converge toward the manifold at a non-asymptotic rate governed by sample size, noise level, bandwidth, and the privacy budget. Simulations and case studies demonstrate accurate signal recovery under moderate privacy budgets, illustrating clear utility-privacy trade-offs and providing a deployable DP component for manifold-based workflows in regulated environments without reengineering privacy systems.
Search More, Think Less: Rethinking Long-Horizon Agentic Search for Efficiency and Generalization
Feb 26, 2026Recent deep research agents primarily improve performance by scaling reasoning depth, but this leads to high inference cost and latency in search-intensive scenarios. Moreover, generalization across heterogeneous research settings remains challenging. In this work, we propose \emph{Search More, Think Less} (SMTL), a framework for long-horizon agentic search that targets both efficiency and generalization. SMTL replaces sequential reasoning with parallel evidence acquisition, enabling efficient context management under constrained context budgets. To support generalization across task types, we further introduce a unified data synthesis pipeline that constructs search tasks spanning both deterministic question answering and open-ended research scenarios with task appropriate evaluation metrics. We train an end-to-end agent using supervised fine-tuning and reinforcement learning, achieving strong and often state of the art performance across benchmarks including BrowseComp (48.6\%), GAIA (75.7\%), Xbench (82.0\%), and DeepResearch Bench (45.9\%). Compared to Mirothinker-v1.0, SMTL with maximum 100 interaction steps reduces the average number of reasoning steps on BrowseComp by 70.7\%, while improving accuracy.
AIForge-Doc: A Benchmark for Detecting AI-Forged Tampering in Financial and Form Documents
Feb 24, 2026We present AIForge-Doc, the first dedicated benchmark targeting exclusively diffusion-model-based inpainting in financial and form documents with pixel-level annotation. Existing document forgery datasets rely on traditional digital editing tools (e.g., Adobe Photoshop, GIMP), creating a critical gap: state-of-the-art detectors are blind to the rapidly growing threat of AI-forged document fraud. AIForge-Doc addresses this gap by systematically forging numeric fields in real-world receipt and form images using two AI inpainting APIs -- Gemini 2.5 Flash Image and Ideogram v2 Edit -- yielding 4,061 forged images from four public document datasets (CORD, WildReceipt, SROIE, XFUND) across nine languages, annotated with pixel-precise tampered-region masks in DocTamper-compatible format. We benchmark three representative detectors -- TruFor, DocTamper, and a zero-shot GPT-4o judge -- and find that all existing methods degrade substantially: TruFor achieves AUC=0.751 (zero-shot, out-of-distribution) vs. AUC=0.96 on NIST16; DocTamper achieves AUC=0.563 vs. AUC=0.98 in-distribution, with pixel-level IoU=0.020; GPT-4o achieves only 0.509 -- essentially at chance -- confirming that AI-forged values are indistinguishable to automated detectors and VLMs. These results demonstrate that AIForge-Doc represents a qualitatively new and unsolved challenge for document forensics.
How Implicit Bias Accumulates and Propagates in LLM Long-term Memory
Feb 02, 2026Long-term memory mechanisms enable Large Language Models (LLMs) to maintain continuity and personalization across extended interaction lifecycles, but they also introduce new and underexplored risks related to fairness. In this work, we study how implicit bias, defined as subtle statistical prejudice, accumulates and propagates within LLMs equipped with long-term memory. To support systematic analysis, we introduce the Decision-based Implicit Bias (DIB) Benchmark, a large-scale dataset comprising 3,776 decision-making scenarios across nine social domains, designed to quantify implicit bias in long-term decision processes. Using a realistic long-horizon simulation framework, we evaluate six state-of-the-art LLMs integrated with three representative memory architectures on DIB and demonstrate that LLMs' implicit bias does not remain static but intensifies over time and propagates across unrelated domains. We further analyze mitigation strategies and show that a static system-level prompting baseline provides limited and short-lived debiasing effects. To address this limitation, we propose Dynamic Memory Tagging (DMT), an agentic intervention that enforces fairness constraints at memory write time. Extensive experimental results show that DMT substantially reduces bias accumulation and effectively curtails cross-domain bias propagation.
O-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
GeoMVD: Geometry-Enhanced Multi-View Generation Model Based on Geometric Information Extraction
Nov 19, 2025
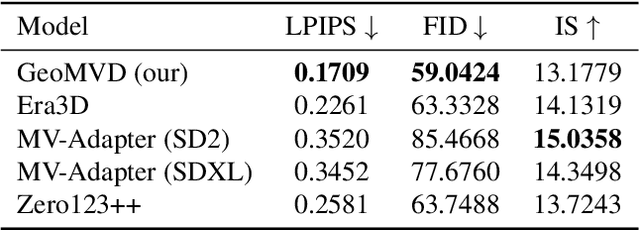
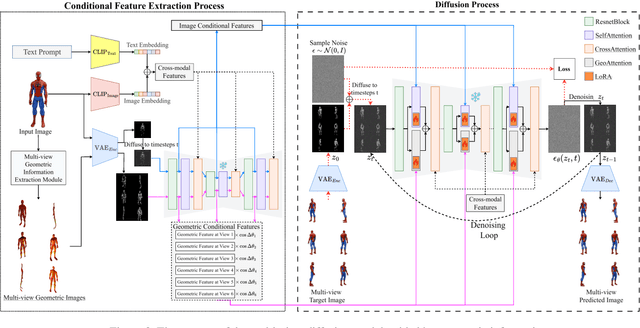
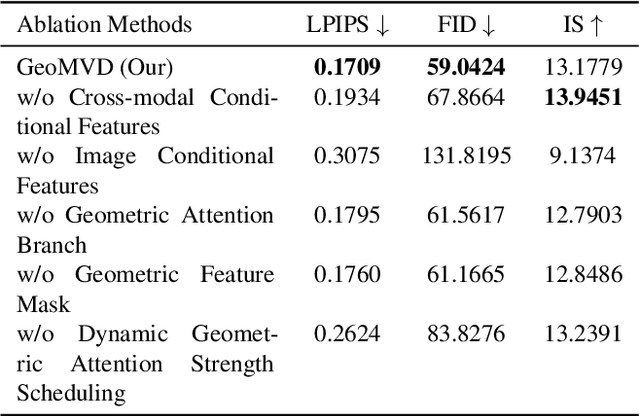
Multi-view image generation holds significant application value in computer vision, particularly in domains like 3D reconstruction, virtual reality, and augmented reality. Most existing methods, which rely on extending single images, face notable computational challenges in maintaining cross-view consistency and generating high-resolution outputs. To address these issues, we propose the Geometry-guided Multi-View Diffusion Model, which incorporates mechanisms for extracting multi-view geometric information and adjusting the intensity of geometric features to generate images that are both consistent across views and rich in detail. Specifically, we design a multi-view geometry information extraction module that leverages depth maps, normal maps, and foreground segmentation masks to construct a shared geometric structure, ensuring shape and structural consistency across different views. To enhance consistency and detail restoration during generation, we develop a decoupled geometry-enhanced attention mechanism that strengthens feature focus on key geometric details, thereby improving overall image quality and detail preservation. Furthermore, we apply an adaptive learning strategy that fine-tunes the model to better capture spatial relationships and visual coherence between the generated views, ensuring realistic results. Our model also incorporates an iterative refinement process that progressively improves the output quality through multiple stages of image generation. Finally, a dynamic geometry information intensity adjustment mechanism is proposed to adaptively regulate the influence of geometric data, optimizing overall quality while ensuring the naturalness of generated images. More details can be found on the project page: https://sobeymil.github.io/GeoMVD.com.