 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNCSAM Noise-Compensated Sharpness-Aware Minimization for Noisy Label Learning
Jan 24, 2026Learning from Noisy Labels (LNL) presents a fundamental challenge in deep learning, as real-world datasets often contain erroneous or corrupted annotations, \textit{e.g.}, data crawled from Web. Current research focuses on sophisticated label correction mechanisms. In contrast, this paper adopts a novel perspective by establishing a theoretical analysis the relationship between flatness of the loss landscape and the presence of label noise. In this paper, we theoretically demonstrate that carefully simulated label noise synergistically enhances both the generalization performance and robustness of label noises. Consequently, we propose Noise-Compensated Sharpness-aware Minimization (NCSAM) to leverage the perturbation of Sharpness-Aware Minimization (SAM) to remedy the damage of label noises. Our analysis reveals that the testing accuracy exhibits a similar behavior that has been observed on the noise-clear dataset. Extensive experimental results on multiple benchmark datasets demonstrate the consistent superiority of the proposed method over existing state-of-the-art approaches on diverse tasks.
Less is More: Non-uniform Road Segments are Efficient for Bus Arrival Prediction
Dec 08, 2025In bus arrival time prediction, the process of organizing road infrastructure network data into homogeneous entities is known as segmentation. Segmenting a road network is widely recognized as the first and most critical step in developing an arrival time prediction system, particularly for auto-regressive-based approaches. Traditional methods typically employ a uniform segmentation strategy, which fails to account for varying physical constraints along roads, such as road conditions, intersections, and points of interest, thereby limiting prediction efficiency. In this paper, we propose a Reinforcement Learning (RL)-based approach to efficiently and adaptively learn non-uniform road segments for arrival time prediction. Our method decouples the prediction process into two stages: 1) Non-uniform road segments are extracted based on their impact scores using the proposed RL framework; and 2) A linear prediction model is applied to the selected segments to make predictions. This method ensures optimal segment selection while maintaining computational efficiency, offering a significant improvement over traditional uniform approaches. Furthermore, our experimental results suggest that the linear approach can even achieve better performance than more complex methods. Extensive experiments demonstrate the superiority of the proposed method, which not only enhances efficiency but also improves learning performance on large-scale benchmarks. The dataset and the code are publicly accessible at: https://github.com/pangjunbiao/Less-is-More.
Few Shot Semi-Supervised Learning for Abnormal Stop Detection from Sparse GPS Trajectories
Oct 14, 2025Abnormal stop detection (ASD) in intercity coach transportation is critical for ensuring passenger safety, operational reliability, and regulatory compliance. However, two key challenges hinder ASD effectiveness: sparse GPS trajectories, which obscure short or unauthorized stops, and limited labeled data, which restricts supervised learning. Existing methods often assume dense sampling or regular movement patterns, limiting their applicability. To address data sparsity, we propose a Sparsity-Aware Segmentation (SAS) method that adaptively defines segment boundaries based on local spatial-temporal density. Building upon these segments, we introduce three domain-specific indicators to capture abnormal stop behaviors. To further mitigate the impact of sparsity, we develop Locally Temporal-Indicator Guided Adjustment (LTIGA), which smooths these indicators via local similarity graphs. To overcome label scarcity, we construct a spatial-temporal graph where each segment is a node with LTIGA-refined features. We apply label propagation to expand weak supervision across the graph, followed by a GCN to learn relational patterns. A final self-training module incorporates high-confidence pseudo-labels to iteratively improve predictions. Experiments on real-world coach data show an AUC of 0.854 and AP of 0.866 using only 10 labeled instances, outperforming prior methods. The code and dataset are publicly available at \href{https://github.com/pangjunbiao/Abnormal-Stop-Detection-SSL.git}
MEC-Quant: Maximum Entropy Coding for Extremely Low Bit Quantization-Aware Training
Sep 19, 2025Quantization-Aware Training (QAT) has driven much attention to produce efficient neural networks. Current QAT still obtains inferior performances compared with the Full Precision (FP) counterpart. In this work, we argue that quantization inevitably introduce biases into the learned representation, especially under the extremely low-bit setting. To cope with this issue, we propose Maximum Entropy Coding Quantization (MEC-Quant), a more principled objective that explicitly optimizes on the structure of the representation, so that the learned representation is less biased and thus generalizes better to unseen in-distribution samples. To make the objective end-to-end trainable, we propose to leverage the minimal coding length in lossy data coding as a computationally tractable surrogate for the entropy, and further derive a scalable reformulation of the objective based on Mixture Of Experts (MOE) that not only allows fast computation but also handles the long-tailed distribution for weights or activation values. Extensive experiments on various tasks on computer vision tasks prove its superiority. With MEC-Qaunt, the limit of QAT is pushed to the x-bit activation for the first time and the accuracy of MEC-Quant is comparable to or even surpass the FP counterpart. Without bells and whistles, MEC-Qaunt establishes a new state of the art for QAT.
Stabilizing Quantization-Aware Training by Implicit-Regularization on Hessian Matrix
Mar 14, 2025Quantization-Aware Training (QAT) is one of the prevailing neural network compression solutions. However, its stability has been challenged for yielding deteriorating performances as the quantization error is inevitable. We find that the sharp landscape of loss, which leads to a dramatic performance drop, is an essential factor that causes instability. Theoretically, we have discovered that the perturbations in the feature would bring a flat local minima. However, simply adding perturbations into either weight or feature empirically deteriorates the performance of the Full Precision (FP) model. In this paper, we propose Feature-Perturbed Quantization (FPQ) to stochastically perturb the feature and employ the feature distillation method to the quantized model. Our method generalizes well to different network architectures and various QAT methods. Furthermore, we mathematically show that FPQ implicitly regularizes the Hessian norm, which calibrates the smoothness of a loss landscape. Extensive experiments demonstrate that our approach significantly outperforms the current State-Of-The-Art (SOTA) QAT methods and even the FP counterparts.
Uncertainty-aware Long-tailed Weights Model the Utility of Pseudo-labels for Semi-supervised Learning
Mar 13, 2025Current Semi-supervised Learning (SSL) adopts the pseudo-labeling strategy and further filters pseudo-labels based on confidence thresholds. However, this mechanism has notable drawbacks: 1) setting the reasonable threshold is an open problem which significantly influences the selection of the high-quality pseudo-labels; and 2) deep models often exhibit the over-confidence phenomenon which makes the confidence value an unreliable indicator for assessing the quality of pseudo-labels due to the scarcity of labeled data. In this paper, we propose an Uncertainty-aware Ensemble Structure (UES) to assess the utility of pseudo-labels for unlabeled samples. We further model the utility of pseudo-labels as long-tailed weights to avoid the open problem of setting the threshold. Concretely, the advantage of the long-tailed weights ensures that even unreliable pseudo-labels still contribute to enhancing the model's robustness. Besides, UES is lightweight and architecture-agnostic, easily extending to various computer vision tasks, including classification and regression. Experimental results demonstrate that combining the proposed method with DualPose leads to a 3.47% improvement in Percentage of Correct Keypoints (PCK) on the Sniffing dataset with 100 data points (30 labeled), a 7.29\% improvement in PCK on the FLIC dataset with 100 data points (50 labeled), and a 3.91% improvement in PCK on the LSP dataset with 200 data points (100 labeled). Furthermore, when combined with FixMatch, the proposed method achieves a 0.2% accuracy improvement on the CIFAR-10 dataset with 40 labeled data points and a 0.26% accuracy improvement on the CIFAR-100 dataset with 400 labeled data points.
Unsupervised Abnormal Stop Detection for Long Distance Coaches with Low-Frequency GPS
Nov 07, 2024
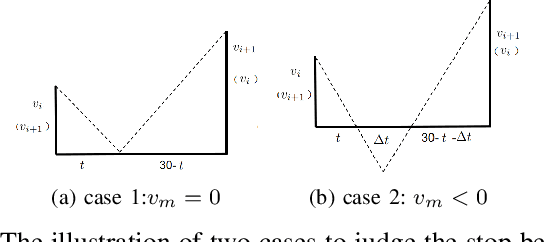
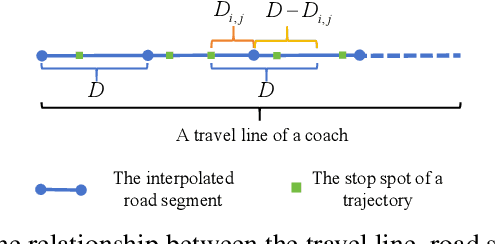
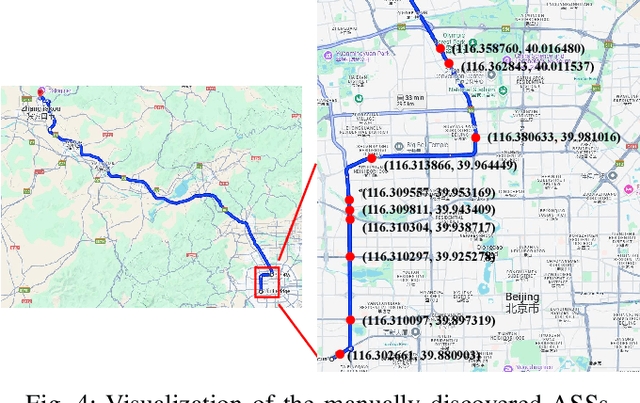
In our urban life, long distance coaches supply a convenient yet economic approach to the transportation of the public. One notable problem is to discover the abnormal stop of the coaches due to the important reason, i.e., illegal pick up on the way which possibly endangers the safety of passengers. It has become a pressing issue to detect the coach abnormal stop with low-quality GPS. In this paper, we propose an unsupervised method that helps transportation managers to efficiently discover the Abnormal Stop Detection (ASD) for long distance coaches. Concretely, our method converts the ASD problem into an unsupervised clustering framework in which both the normal stop and the abnormal one are decomposed. Firstly, we propose a stop duration model for the low frequency GPS based on the assumption that a coach changes speed approximately in a linear approach. Secondly, we strip the abnormal stops from the normal stop points by the low rank assumption. The proposed method is conceptually simple yet efficient, by leveraging low rank assumption to handle normal stop points, our approach enables domain experts to discover the ASD for coaches, from a case study motivated by traffic managers. Datset and code are publicly available at: https://github.com/pangjunbiao/IPPs.
Decorrelating Structure via Adapters Makes Ensemble Learning Practical for Semi-supervised Learning
Aug 08, 2024



In computer vision, traditional ensemble learning methods exhibit either a low training efficiency or the limited performance to enhance the reliability of deep neural networks. In this paper, we propose a lightweight, loss-function-free, and architecture-agnostic ensemble learning by the Decorrelating Structure via Adapters (DSA) for various visual tasks. Concretely, the proposed DSA leverages the structure-diverse adapters to decorrelate multiple prediction heads without any tailed regularization or loss. This allows DSA to be easily extensible to architecture-agnostic networks for a range of computer vision tasks. Importantly, the theoretically analysis shows that the proposed DSA has a lower bias and variance than that of the single head based method (which is adopted by most of the state of art approaches). Consequently, the DSA makes deep networks reliable and robust for the various real-world challenges, \textit{e.g.}, data corruption, and label noises. Extensive experiments combining the proposed method with FreeMatch achieved the accuracy improvements of 5.35% on CIFAR-10 dataset with 40 labeled data and 0.71% on CIFAR-100 dataset with 400 labeled data. Besides, combining the proposed method with DualPose achieved the improvements in the Percentage of Correct Keypoints (PCK) by 2.08% on the Sniffing dataset with 100 data (30 labeled data), 5.2% on the FLIC dataset with 100 data (including 50 labeled data), and 2.35% on the LSP dataset with 200 data (100 labeled data).
Asymptotic Unbiased Sample Sampling to Speed Up Sharpness-Aware Minimization
Jun 12, 2024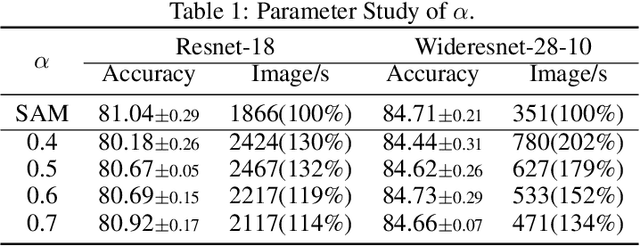
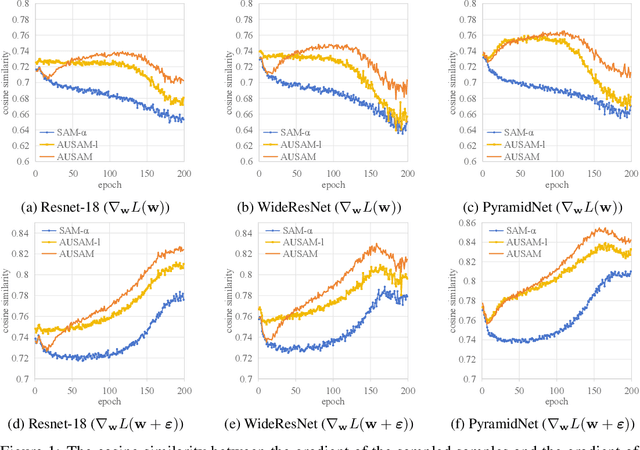
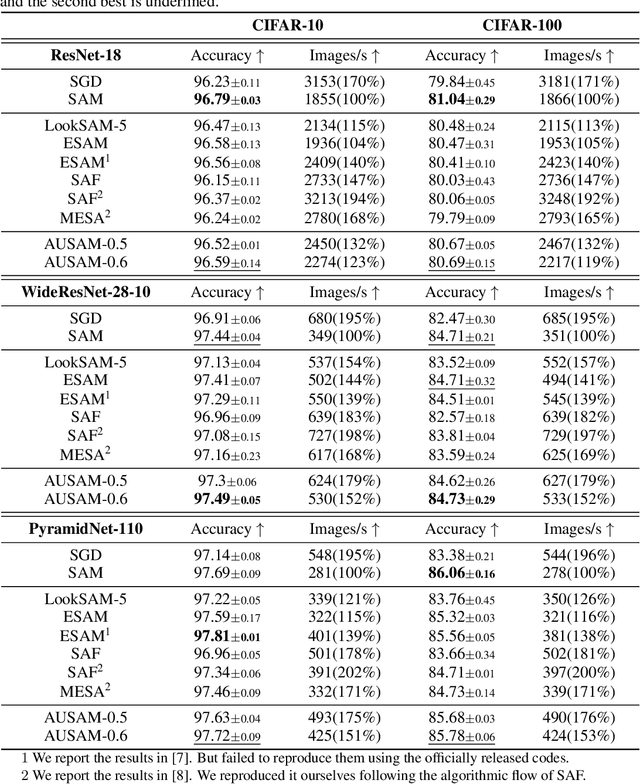
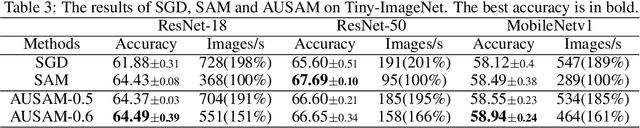
Sharpness-Aware Minimization (SAM) has emerged as a promising approach for effectively reducing the generalization error. However, SAM incurs twice the computational cost compared to base optimizer (e.g., SGD). We propose Asymptotic Unbiased Sampling with respect to iterations to accelerate SAM (AUSAM), which maintains the model's generalization capacity while significantly enhancing computational efficiency. Concretely, we probabilistically sample a subset of data points beneficial for SAM optimization based on a theoretically guaranteed criterion, i.e., the Gradient Norm of each Sample (GNS). We further approximate the GNS by the difference in loss values before and after perturbation in SAM. As a plug-and-play, architecture-agnostic method, our approach consistently accelerates SAM across a range of tasks and networks, i.e., classification, human pose estimation and network quantization. On CIFAR10/100 and Tiny-ImageNet, AUSAM achieves results comparable to SAM while providing a speedup of over 70%. Compared to recent dynamic data pruning methods, AUSAM is better suited for SAM and excels in maintaining performance. Additionally, AUSAM accelerates optimization in human pose estimation and model quantization without sacrificing performance, demonstrating its broad practicality.
Modeling Multi-Granularity Context Information Flow for Pavement Crack Detection
Apr 19, 2024



Crack detection has become an indispensable, interesting yet challenging task in the computer vision community. Specially, pavement cracks have a highly complex spatial structure, a low contrasting background and a weak spatial continuity, posing a significant challenge to an effective crack detection method. In this paper, we address these problems from a view that utilizes contexts of the cracks and propose an end-to-end deep learning method to model the context information flow. To precisely localize crack from an image, it is critical to effectively extract and aggregate multi-granularity context, including the fine-grained local context around the cracks (in spatial-level) and the coarse-grained semantics (in segment-level). Concretely, in Convolutional Neural Network (CNN), low-level features extracted by the shallow layers represent the local information, while the deep layers extract the semantic features. Additionally, a second main insight in this work is that the semantic context should be an guidance to local context feature. By the above insights, the proposed method we first apply the dilated convolution as the backbone feature extractor to model local context, then we build a context guidance module to leverage semantic context to guide local feature extraction at multiple stages. To handle label alignment between stages, we apply the Multiple Instance Learning (MIL) strategy to align the high-level feature to the low-level ones in the stage-wise context flow. In addition, compared with these public crack datasets, to our best knowledge, we release the largest, most complex and most challenging Bitumen Pavement Crack (BPC) dataset. The experimental results on the three crack datasets demonstrate that the proposed method performs well and outperforms the current state-of-the-art methods.