 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-stage soft computing framework for complex disease modelling and decision support: A liver cirrhosis case study
Apr 26, 2026Liver cirrhosis is a major global health problem causing millions of deaths annually, and timely detection with aggressive treatment can significantly improve patients' quality of life. Modelling complex diseases from biomedical data is computationally challenging due to high dimensionality, strong feature correlations, noise, and limited labelled samples. Conventional Machine Learning (ML) pipelines often struggle with robustness, interpretability, and generalisation under such conditions. In this study, we propose an ML-driven multi-stage decision framework for complex disease modelling and therapeutic exploration. The framework integrates single-cell transcriptomic profiling, high-dimensional network-based feature stabilisation, multi-model learning, deep representation construction, and post-hoc decision support. Specifically, single-cell sequencing data were analysed to identify key cellular subpopulations, followed by high-dimensional weighted gene co-expression network analysis (hdWGCNA) to stabilise gene modules under sparsity and noise. To enhance non-linear feature interaction modelling, tabular molecular features were restructured into two-dimensional disease maps and analysed using a CNN. Finally, molecular docking was incorporated as a decision-support module to evaluate candidate therapeutic compounds. Using liver cirrhosis as a representative case, the framework identified a disease-associated endothelial subpopulation and extracted seven robust signature genes (HSPB1, GADD45A, CLDN5, ATP1B3, C1QBP, ENPP2, and PARL). The CNN-based representation learning module outperformed conventional pipelines in classification. The framework is disease-agnostic and readily extends to other omics-driven biomedical applications involving uncertainty, heterogeneity, and limited samples.
NCSAM Noise-Compensated Sharpness-Aware Minimization for Noisy Label Learning
Jan 24, 2026Learning from Noisy Labels (LNL) presents a fundamental challenge in deep learning, as real-world datasets often contain erroneous or corrupted annotations, \textit{e.g.}, data crawled from Web. Current research focuses on sophisticated label correction mechanisms. In contrast, this paper adopts a novel perspective by establishing a theoretical analysis the relationship between flatness of the loss landscape and the presence of label noise. In this paper, we theoretically demonstrate that carefully simulated label noise synergistically enhances both the generalization performance and robustness of label noises. Consequently, we propose Noise-Compensated Sharpness-aware Minimization (NCSAM) to leverage the perturbation of Sharpness-Aware Minimization (SAM) to remedy the damage of label noises. Our analysis reveals that the testing accuracy exhibits a similar behavior that has been observed on the noise-clear dataset. Extensive experimental results on multiple benchmark datasets demonstrate the consistent superiority of the proposed method over existing state-of-the-art approaches on diverse tasks.
Less is More: Non-uniform Road Segments are Efficient for Bus Arrival Prediction
Dec 08, 2025In bus arrival time prediction, the process of organizing road infrastructure network data into homogeneous entities is known as segmentation. Segmenting a road network is widely recognized as the first and most critical step in developing an arrival time prediction system, particularly for auto-regressive-based approaches. Traditional methods typically employ a uniform segmentation strategy, which fails to account for varying physical constraints along roads, such as road conditions, intersections, and points of interest, thereby limiting prediction efficiency. In this paper, we propose a Reinforcement Learning (RL)-based approach to efficiently and adaptively learn non-uniform road segments for arrival time prediction. Our method decouples the prediction process into two stages: 1) Non-uniform road segments are extracted based on their impact scores using the proposed RL framework; and 2) A linear prediction model is applied to the selected segments to make predictions. This method ensures optimal segment selection while maintaining computational efficiency, offering a significant improvement over traditional uniform approaches. Furthermore, our experimental results suggest that the linear approach can even achieve better performance than more complex methods. Extensive experiments demonstrate the superiority of the proposed method, which not only enhances efficiency but also improves learning performance on large-scale benchmarks. The dataset and the code are publicly accessible at: https://github.com/pangjunbiao/Less-is-More.
MoTE: Mixture of Ternary Experts for Memory-efficient Large Multimodal Models
Jun 17, 2025Large multimodal Mixture-of-Experts (MoEs) effectively scale the model size to boost performance while maintaining fixed active parameters. However, previous works primarily utilized full-precision experts during sparse up-cycling. Despite they show superior performance on end tasks, the large amount of experts introduces higher memory footprint, which poses significant challenges for the deployment on edge devices. In this work, we propose MoTE, a scalable and memory-efficient approach to train Mixture-of-Ternary-Experts models from dense checkpoint. Instead of training fewer high-precision experts, we propose to train more low-precision experts during up-cycling. Specifically, we use the pre-trained FFN as a shared expert and train ternary routed experts with parameters in {-1, 0, 1}. Extensive experiments show that our approach has promising scaling trend along model size. MoTE achieves comparable performance to full-precision baseline MoE-LLaVA while offering lower memory footprint. Furthermore, our approach is compatible with post-training quantization methods and the advantage further amplifies when memory-constraint goes lower. Given the same amount of expert memory footprint of 3.4GB and combined with post-training quantization, MoTE outperforms MoE-LLaVA by a gain of 4.3% average accuracy on end tasks, demonstrating its effectiveness and potential for memory-constrained devices.
Unsupervised Abnormal Stop Detection for Long Distance Coaches with Low-Frequency GPS
Nov 07, 2024
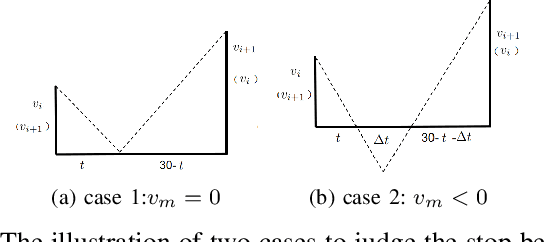
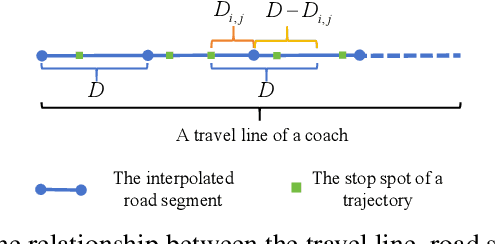
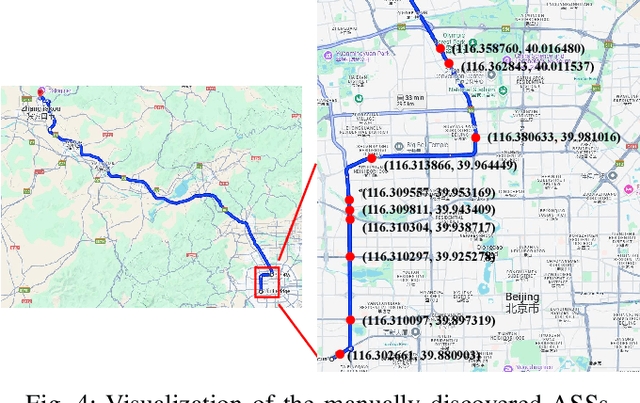
In our urban life, long distance coaches supply a convenient yet economic approach to the transportation of the public. One notable problem is to discover the abnormal stop of the coaches due to the important reason, i.e., illegal pick up on the way which possibly endangers the safety of passengers. It has become a pressing issue to detect the coach abnormal stop with low-quality GPS. In this paper, we propose an unsupervised method that helps transportation managers to efficiently discover the Abnormal Stop Detection (ASD) for long distance coaches. Concretely, our method converts the ASD problem into an unsupervised clustering framework in which both the normal stop and the abnormal one are decomposed. Firstly, we propose a stop duration model for the low frequency GPS based on the assumption that a coach changes speed approximately in a linear approach. Secondly, we strip the abnormal stops from the normal stop points by the low rank assumption. The proposed method is conceptually simple yet efficient, by leveraging low rank assumption to handle normal stop points, our approach enables domain experts to discover the ASD for coaches, from a case study motivated by traffic managers. Datset and code are publicly available at: https://github.com/pangjunbiao/IPPs.
M4U: Evaluating Multilingual Understanding and Reasoning for Large Multimodal Models
May 24, 2024Multilingual multimodal reasoning is a core component in achieving human-level intelligence. However, most existing benchmarks for multilingual multimodal reasoning struggle to differentiate between models of varying performance; even language models without visual capabilities can easily achieve high scores. This leaves a comprehensive evaluation of leading multilingual multimodal models largely unexplored. In this work, we introduce M4U, a novel and challenging benchmark for assessing the capability of multi-discipline multilingual multimodal understanding and reasoning. M4U contains 8,931 samples covering 64 disciplines across 16 subfields in Science, Engineering, and Healthcare in Chinese, English, and German. Using M4U, we conduct extensive evaluations of 21 leading Large Multimodal Models (LMMs) and Large Language Models (LLMs) with external tools. The evaluation results show that the state-of-the-art model, GPT-4o, achieves only 47.6% average accuracy on M4U. Additionally, we observe that the leading LMMs exhibit significant language preferences. Our in-depth analysis indicates that leading LMMs, including GPT-4o, suffer performance degradation when prompted with cross-lingual multimodal questions, such as images with key textual information in Chinese while the question is in German. We believe that M4U can serve as a crucial tool for systematically evaluating LMMs based on their multilingual multimodal reasoning capabilities and monitoring their development. The homepage, codes and data are public available.
DS-TransUNet:Dual Swin Transformer U-Net for Medical Image Segmentation
Jun 12, 2021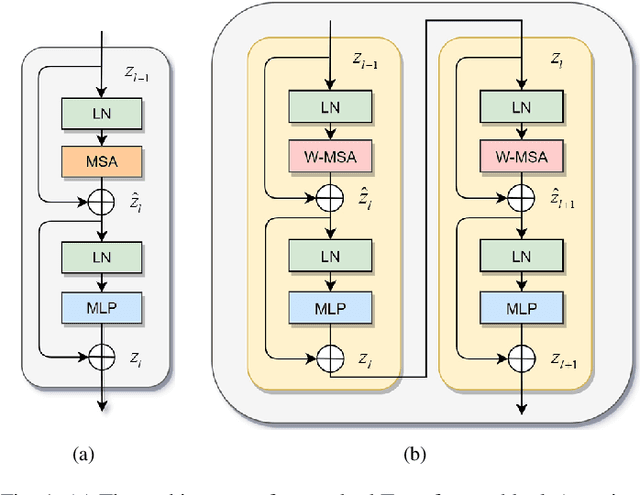
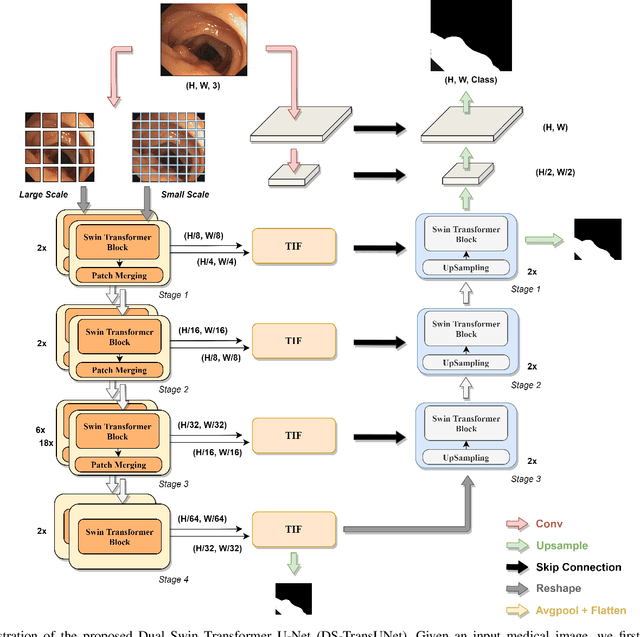
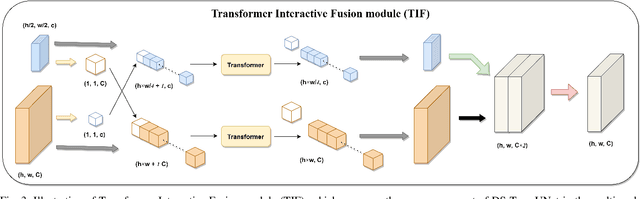

Automatic medical image segmentation has made great progress benefit from the development of deep learning. However, most existing methods are based on convolutional neural networks (CNNs), which fail to build long-range dependencies and global context connections due to the limitation of receptive field in convolution operation. Inspired by the success of Transformer in modeling the long-range contextual information, some researchers have expended considerable efforts in designing the robust variants of Transformer-based U-Net. Moreover, the patch division used in vision transformers usually ignores the pixel-level intrinsic structural features inside each patch. To alleviate these problems, we propose a novel deep medical image segmentation framework called Dual Swin Transformer U-Net (DS-TransUNet), which might be the first attempt to concurrently incorporate the advantages of hierarchical Swin Transformer into both encoder and decoder of the standard U-shaped architecture to enhance the semantic segmentation quality of varying medical images. Unlike many prior Transformer-based solutions, the proposed DS-TransUNet first adopts dual-scale encoder subnetworks based on Swin Transformer to extract the coarse and fine-grained feature representations of different semantic scales. As the core component for our DS-TransUNet, a well-designed Transformer Interactive Fusion (TIF) module is proposed to effectively establish global dependencies between features of different scales through the self-attention mechanism. Furthermore, we also introduce the Swin Transformer block into decoder to further explore the long-range contextual information during the up-sampling process. Extensive experiments across four typical tasks for medical image segmentation demonstrate the effectiveness of DS-TransUNet, and show that our approach significantly outperforms the state-of-the-art methods.