 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Modal Fine-Grained Alignment via Granularity-Aware and Region-Uncertain Modeling
Nov 19, 2025Fine-grained image-text alignment is a pivotal challenge in multimodal learning, underpinning key applications such as visual question answering, image captioning, and vision-language navigation. Unlike global alignment, fine-grained alignment requires precise correspondence between localized visual regions and textual tokens, often hindered by noisy attention mechanisms and oversimplified modeling of cross-modal relationships. In this work, we identify two fundamental limitations of existing approaches: the lack of robust intra-modal mechanisms to assess the significance of visual and textual tokens, leading to poor generalization in complex scenes; and the absence of fine-grained uncertainty modeling, which fails to capture the one-to-many and many-to-one nature of region-word correspondences. To address these issues, we propose a unified approach that incorporates significance-aware and granularity-aware modeling and region-level uncertainty modeling. Our method leverages modality-specific biases to identify salient features without relying on brittle cross-modal attention, and represents region features as a mixture of Gaussian distributions to capture fine-grained uncertainty. Extensive experiments on Flickr30K and MS-COCO demonstrate that our approach achieves state-of-the-art performance across various backbone architectures, significantly enhancing the robustness and interpretability of fine-grained image-text alignment.
Role-RL: Online Long-Context Processing with Role Reinforcement Learning for Distinct LLMs in Their Optimal Roles
Sep 26, 2024



Large language models (LLMs) with long-context processing are still challenging because of their implementation complexity, training efficiency and data sparsity. To address this issue, a new paradigm named Online Long-context Processing (OLP) is proposed when we process a document of unlimited length, which typically occurs in the information reception and organization of diverse streaming media such as automated news reporting, live e-commerce, and viral short videos. Moreover, a dilemma was often encountered when we tried to select the most suitable LLM from a large number of LLMs amidst explosive growth aiming for outstanding performance, affordable prices, and short response delays. In view of this, we also develop Role Reinforcement Learning (Role-RL) to automatically deploy different LLMs in their respective roles within the OLP pipeline according to their actual performance. Extensive experiments are conducted on our OLP-MINI dataset and it is found that OLP with Role-RL framework achieves OLP benchmark with an average recall rate of 93.2% and the LLM cost saved by 79.4%. The code and dataset are publicly available at: https://anonymous.4open.science/r/Role-RL.
TransAttUnet: Multi-level Attention-guided U-Net with Transformer for Medical Image Segmentation
Jul 12, 2021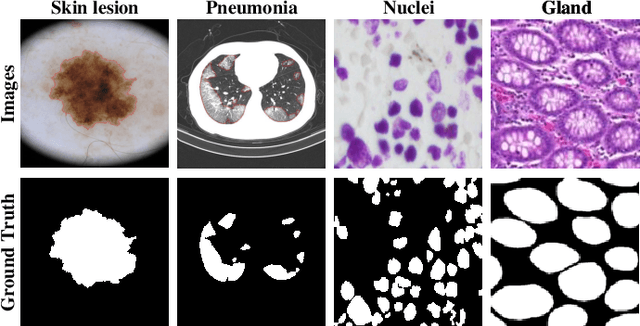
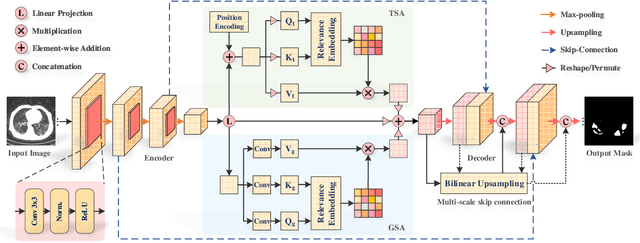
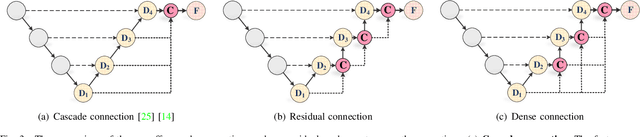
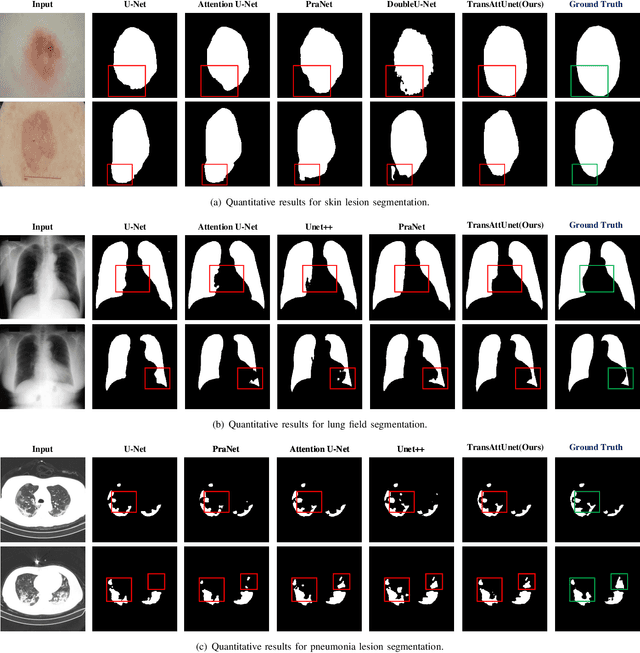
With the development of deep encoder-decoder architectures and large-scale annotated medical datasets, great progress has been achieved in the development of automatic medical image segmentation. Due to the stacking of convolution layers and the consecutive sampling operations, existing standard models inevitably encounter the information recession problem of feature representations, which fails to fully model the global contextual feature dependencies. To overcome the above challenges, this paper proposes a novel Transformer based medical image semantic segmentation framework called TransAttUnet, in which the multi-level guided attention and multi-scale skip connection are jointly designed to effectively enhance the functionality and flexibility of traditional U-shaped architecture. Inspired by Transformer, a novel self-aware attention (SAA) module with both Transformer Self Attention (TSA) and Global Spatial Attention (GSA) is incorporated into TransAttUnet to effectively learn the non-local interactions between encoder features. In particular, we also establish additional multi-scale skip connections between decoder blocks to aggregate the different semantic-scale upsampling features. In this way, the representation ability of multi-scale context information is strengthened to generate discriminative features. Benefitting from these complementary components, the proposed TransAttUnet can effectively alleviate the loss of fine details caused by the information recession problem, improving the diagnostic sensitivity and segmentation quality of medical image analysis. Extensive experiments on multiple medical image segmentation datasets of different imaging demonstrate that our method consistently outperforms the state-of-the-art baselines.
DS-TransUNet:Dual Swin Transformer U-Net for Medical Image Segmentation
Jun 12, 2021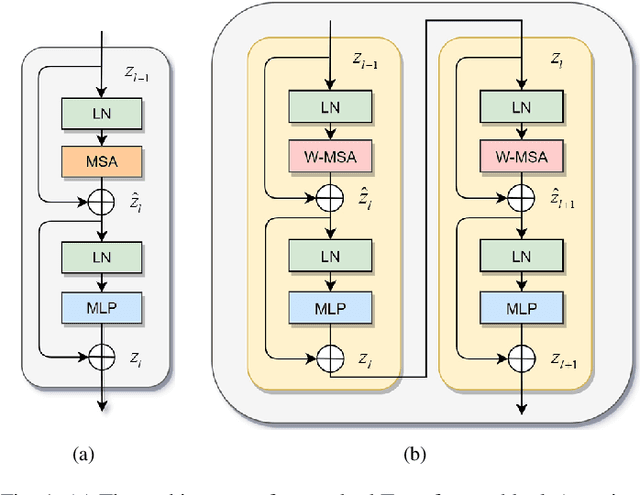
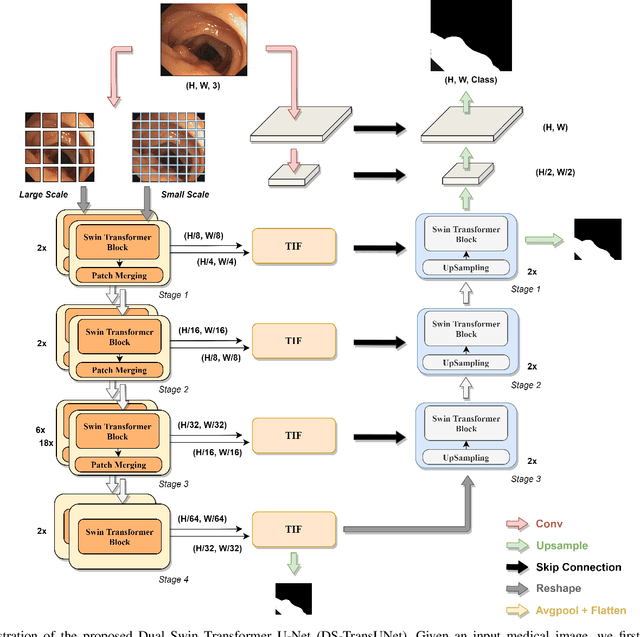
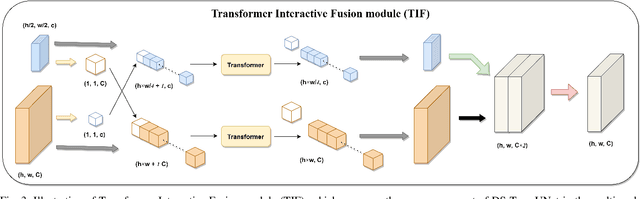

Automatic medical image segmentation has made great progress benefit from the development of deep learning. However, most existing methods are based on convolutional neural networks (CNNs), which fail to build long-range dependencies and global context connections due to the limitation of receptive field in convolution operation. Inspired by the success of Transformer in modeling the long-range contextual information, some researchers have expended considerable efforts in designing the robust variants of Transformer-based U-Net. Moreover, the patch division used in vision transformers usually ignores the pixel-level intrinsic structural features inside each patch. To alleviate these problems, we propose a novel deep medical image segmentation framework called Dual Swin Transformer U-Net (DS-TransUNet), which might be the first attempt to concurrently incorporate the advantages of hierarchical Swin Transformer into both encoder and decoder of the standard U-shaped architecture to enhance the semantic segmentation quality of varying medical images. Unlike many prior Transformer-based solutions, the proposed DS-TransUNet first adopts dual-scale encoder subnetworks based on Swin Transformer to extract the coarse and fine-grained feature representations of different semantic scales. As the core component for our DS-TransUNet, a well-designed Transformer Interactive Fusion (TIF) module is proposed to effectively establish global dependencies between features of different scales through the self-attention mechanism. Furthermore, we also introduce the Swin Transformer block into decoder to further explore the long-range contextual information during the up-sampling process. Extensive experiments across four typical tasks for medical image segmentation demonstrate the effectiveness of DS-TransUNet, and show that our approach significantly outperforms the state-of-the-art methods.