 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransAttUnet: Multi-level Attention-guided U-Net with Transformer for Medical Image Segmentation
Jul 12, 2021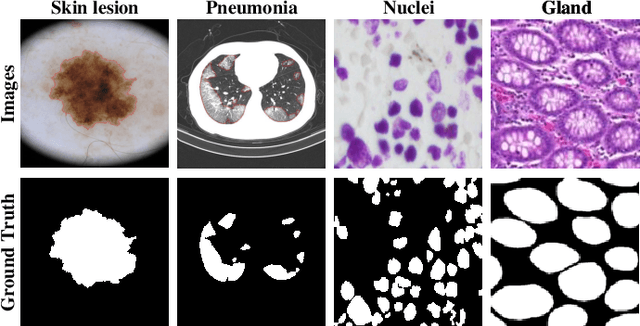
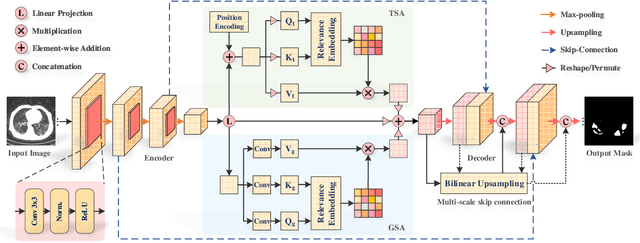
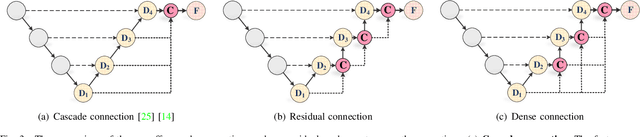
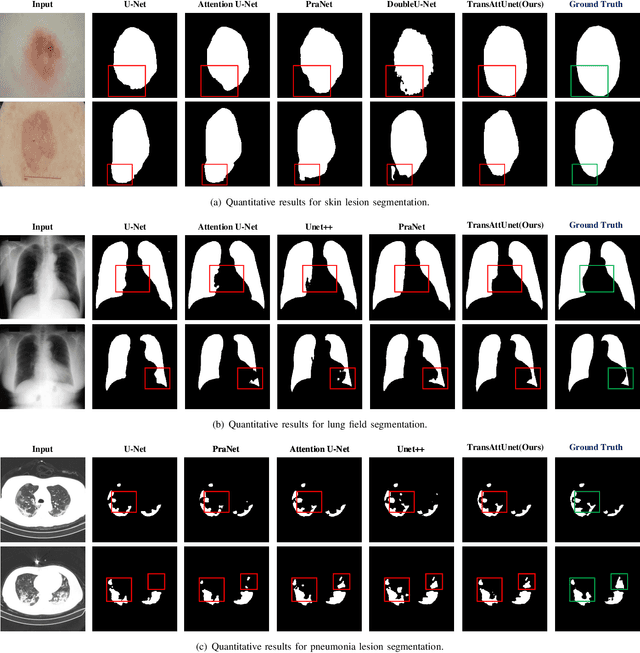
With the development of deep encoder-decoder architectures and large-scale annotated medical datasets, great progress has been achieved in the development of automatic medical image segmentation. Due to the stacking of convolution layers and the consecutive sampling operations, existing standard models inevitably encounter the information recession problem of feature representations, which fails to fully model the global contextual feature dependencies. To overcome the above challenges, this paper proposes a novel Transformer based medical image semantic segmentation framework called TransAttUnet, in which the multi-level guided attention and multi-scale skip connection are jointly designed to effectively enhance the functionality and flexibility of traditional U-shaped architecture. Inspired by Transformer, a novel self-aware attention (SAA) module with both Transformer Self Attention (TSA) and Global Spatial Attention (GSA) is incorporated into TransAttUnet to effectively learn the non-local interactions between encoder features. In particular, we also establish additional multi-scale skip connections between decoder blocks to aggregate the different semantic-scale upsampling features. In this way, the representation ability of multi-scale context information is strengthened to generate discriminative features. Benefitting from these complementary components, the proposed TransAttUnet can effectively alleviate the loss of fine details caused by the information recession problem, improving the diagnostic sensitivity and segmentation quality of medical image analysis. Extensive experiments on multiple medical image segmentation datasets of different imaging demonstrate that our method consistently outperforms the state-of-the-art baselines.