 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-based Generative Diffusion Models to Synthesize Full-dose FDG Brain PET from MRI in Epilepsy Patients
Jun 12, 2025Fluorodeoxyglucose (FDG) PET to evaluate patients with epilepsy is one of the most common applications for simultaneous PET/MRI, given the need to image both brain structure and metabolism, but is suboptimal due to the radiation dose in this young population. Little work has been done synthesizing diagnostic quality PET images from MRI data or MRI data with ultralow-dose PET using advanced generative AI methods, such as diffusion models, with attention to clinical evaluations tailored for the epilepsy population. Here we compared the performance of diffusion- and non-diffusion-based deep learning models for the MRI-to-PET image translation task for epilepsy imaging using simultaneous PET/MRI in 52 subjects (40 train/2 validate/10 hold-out test). We tested three different models: 2 score-based generative diffusion models (SGM-Karras Diffusion [SGM-KD] and SGM-variance preserving [SGM-VP]) and a Transformer-Unet. We report results on standard image processing metrics as well as clinically relevant metrics, including congruency measures (Congruence Index and Congruency Mean Absolute Error) that assess hemispheric metabolic asymmetry, which is a key part of the clinical analysis of these images. The SGM-KD produced the best qualitative and quantitative results when synthesizing PET purely from T1w and T2 FLAIR images with the least mean absolute error in whole-brain specific uptake value ratio (SUVR) and highest intraclass correlation coefficient. When 1% low-dose PET images are included in the inputs, all models improve significantly and are interchangeable for quantitative performance and visual quality. In summary, SGMs hold great potential for pure MRI-to-PET translation, while all 3 model types can synthesize full-dose FDG-PET accurately using MRI and ultralow-dose PET.
SOE: SO(3)-Equivariant 3D MRI Encoding
Oct 15, 2024



Representation learning has become increasingly important, especially as powerful models have shifted towards learning latent representations before fine-tuning for downstream tasks. This approach is particularly valuable in leveraging the structural information within brain anatomy. However, a common limitation of recent models developed for MRIs is their tendency to ignore or remove geometric information, such as translation and rotation, thereby creating invariance with respect to geometric operations. We contend that incorporating knowledge about these geometric transformations into the model can significantly enhance its ability to learn more detailed anatomical information within brain structures. As a result, we propose a novel method for encoding 3D MRIs that enforces equivariance with respect to all rotations in 3D space, in other words, SO(3)-equivariance (SOE). By explicitly modeling this geometric equivariance in the representation space, we ensure that any rotational operation applied to the input image space is also reflected in the embedding representation space. This approach requires moving beyond traditional representation learning methods, as we need a representation vector space that allows for the application of the same SO(3) operation in that space. To facilitate this, we leverage the concept of vector neurons. The representation space formed by our method captures the brain's structural and anatomical information more effectively. We evaluate SOE pretrained on the structural MRIs of two public data sets with respect to the downstream task of predicting age and diagnosing Alzheimer's Disease from T1-weighted brain scans of the ADNI data set. We demonstrate that our approach not only outperforms other methods but is also robust against various degrees of rotation along different axes. The code is available at https://github.com/shizhehe/SOE-representation-learning.
Towards General Purpose Vision Foundation Models for Medical Image Analysis: An Experimental Study of DINOv2 on Radiology Benchmarks
Dec 07, 2023



The integration of deep learning systems into the medical domain has been hindered by the resource-intensive process of data annotation and the inability of these systems to generalize to different data distributions. Foundation models, which are models pre-trained on large datasets, have emerged as a solution to reduce reliance on annotated data and enhance model generalizability and robustness. DINOv2, an open-source foundation model pre-trained with self-supervised learning on 142 million curated natural images, excels in extracting general-purpose visual representations, exhibiting promising capabilities across various vision tasks. Nevertheless, a critical question remains unanswered regarding DINOv2's adaptability to radiological imaging, and the clarity on whether its features are sufficiently general to benefit radiology image analysis is yet to be established. Therefore, this study comprehensively evaluates DINOv2 for radiology, conducting over 100 experiments across diverse modalities (X-ray, CT, and MRI). Tasks include disease classification and organ segmentation on both 2D and 3D images, evaluated under different settings like kNN, few-shot learning, linear-probing, end-to-end fine-tuning, and parameter-efficient fine-tuning, to measure the effectiveness and generalizability of the DINOv2 feature embeddings. Comparative analyses with established medical image analysis models, U-Net and TransUnet for segmentation, and CNN and ViT models pre-trained via supervised, weakly supervised, and self-supervised learning for classification, reveal DINOv2's superior performance in segmentation tasks and competitive results in disease classification. The findings contribute insights to potential avenues for optimizing pre-training strategies for medical imaging and enhancing the broader understanding of DINOv2's role in bridging the gap between natural and radiological image analysis.
Contrastive Self-Supervised Learning for Spatio-Temporal Analysis of Lung Ultrasound Videos
Oct 14, 2023Self-supervised learning (SSL) methods have shown promise for medical imaging applications by learning meaningful visual representations, even when the amount of labeled data is limited. Here, we extend state-of-the-art contrastive learning SSL methods to 2D+time medical ultrasound video data by introducing a modified encoder and augmentation method capable of learning meaningful spatio-temporal representations, without requiring constraints on the input data. We evaluate our method on the challenging clinical task of identifying lung consolidations (an important pathological feature) in ultrasound videos. Using a multi-center dataset of over 27k lung ultrasound videos acquired from over 500 patients, we show that our method can significantly improve performance on downstream localization and classification of lung consolidation. Comparisons against baseline models trained without SSL show that the proposed methods are particularly advantageous when the size of labeled training data is limited (e.g., as little as 5% of the training set).
Metadata-Conditioned Generative Models to Synthesize Anatomically-Plausible 3D Brain MRIs
Oct 07, 2023



Generative AI models hold great potential in creating synthetic brain MRIs that advance neuroimaging studies by, for example, enriching data diversity. However, the mainstay of AI research only focuses on optimizing the visual quality (such as signal-to-noise ratio) of the synthetic MRIs while lacking insights into their relevance to neuroscience. To gain these insights with respect to T1-weighted MRIs, we first propose a new generative model, BrainSynth, to synthesize metadata-conditioned (e.g., age- and sex-specific) MRIs that achieve state-of-the-art visual quality. We then extend our evaluation with a novel procedure to quantify anatomical plausibility, i.e., how well the synthetic MRIs capture macrostructural properties of brain regions, and how accurately they encode the effects of age and sex. Results indicate that more than half of the brain regions in our synthetic MRIs are anatomically accurate, i.e., with a small effect size between real and synthetic MRIs. Moreover, the anatomical plausibility varies across cortical regions according to their geometric complexity. As is, our synthetic MRIs can significantly improve the training of a Convolutional Neural Network to identify accelerated aging effects in an independent study. These results highlight the opportunities of using generative AI to aid neuroimaging research and point to areas for further improvement.
LSOR: Longitudinally-Consistent Self-Organized Representation Learning
Sep 30, 2023Interpretability is a key issue when applying deep learning models to longitudinal brain MRIs. One way to address this issue is by visualizing the high-dimensional latent spaces generated by deep learning via self-organizing maps (SOM). SOM separates the latent space into clusters and then maps the cluster centers to a discrete (typically 2D) grid preserving the high-dimensional relationship between clusters. However, learning SOM in a high-dimensional latent space tends to be unstable, especially in a self-supervision setting. Furthermore, the learned SOM grid does not necessarily capture clinically interesting information, such as brain age. To resolve these issues, we propose the first self-supervised SOM approach that derives a high-dimensional, interpretable representation stratified by brain age solely based on longitudinal brain MRIs (i.e., without demographic or cognitive information). Called Longitudinally-consistent Self-Organized Representation learning (LSOR), the method is stable during training as it relies on soft clustering (vs. the hard cluster assignments used by existing SOM). Furthermore, our approach generates a latent space stratified according to brain age by aligning trajectories inferred from longitudinal MRIs to the reference vector associated with the corresponding SOM cluster. When applied to longitudinal MRIs of the Alzheimer's Disease Neuroimaging Initiative (ADNI, N=632), LSOR generates an interpretable latent space and achieves comparable or higher accuracy than the state-of-the-art representations with respect to the downstream tasks of classification (static vs. progressive mild cognitive impairment) and regression (determining ADAS-Cog score of all subjects). The code is available at https://github.com/ouyangjiahong/longitudinal-som-single-modality.
Weakly Semi-Supervised Detection in Lung Ultrasound Videos
Aug 08, 2023Frame-by-frame annotation of bounding boxes by clinical experts is often required to train fully supervised object detection models on medical video data. We propose a method for improving object detection in medical videos through weak supervision from video-level labels. More concretely, we aggregate individual detection predictions into video-level predictions and extend a teacher-student training strategy to provide additional supervision via a video-level loss. We also introduce improvements to the underlying teacher-student framework, including methods to improve the quality of pseudo-labels based on weak supervision and adaptive schemes to optimize knowledge transfer between the student and teacher networks. We apply this approach to the clinically important task of detecting lung consolidations (seen in respiratory infections such as COVID-19 pneumonia) in medical ultrasound videos. Experiments reveal that our framework improves detection accuracy and robustness compared to baseline semi-supervised models, and improves efficiency in data and annotation usage.
Self-Supervised Longitudinal Neighbourhood Embedding
Mar 09, 2021



Longitudinal MRIs are often used to capture the gradual deterioration of brain structure and function caused by aging or neurological diseases. Analyzing this data via machine learning generally requires a large number of ground-truth labels, which are often missing or expensive to obtain. Reducing the need for labels, we propose a self-supervised strategy for representation learning named Longitudinal Neighborhood Embedding (LNE). Motivated by concepts in contrastive learning, LNE explicitly models the similarity between trajectory vectors across different subjects. We do so by building a graph in each training iteration defining neighborhoods in the latent space so that the progression direction of a subject follows the direction of its neighbors. This results in a smooth trajectory field that captures the global morphological change of the brain while maintaining the local continuity. We apply LNE to longitudinal T1w MRIs of two neuroimaging studies: a dataset composed of 274 healthy subjects, and Alzheimer's Disease Neuroimaging Initiative (ADNI, N=632). The visualization of the smooth trajectory vector field and superior performance on downstream tasks demonstrate the strength of the proposed method over existing self-supervised methods in extracting information associated with normal aging and in revealing the impact of neurodegenerative disorders. The code is available at \url{https://github.com/ouyangjiahong/longitudinal-neighbourhood-embedding.git}.
Representation Disentanglement for Multi-modal MR Analysis
Feb 23, 2021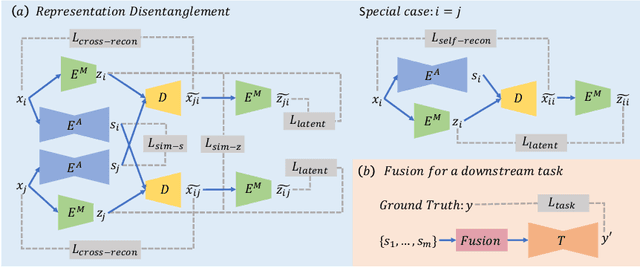
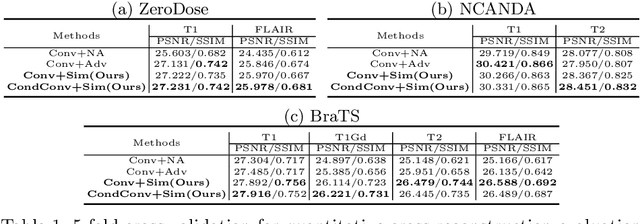
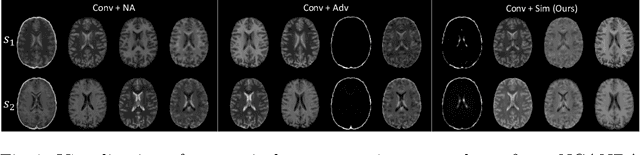

Multi-modal MR images are widely used in neuroimaging applications to provide complementary information about the brain structures. Recent works have suggested that multi-modal deep learning analysis can benefit from explicitly disentangling anatomical (shape) and modality (appearance) representations from the images. In this work, we challenge existing strategies by showing that they do not naturally lead to representation disentanglement both in theory and in practice. To address this issue, we propose a margin loss that regularizes the similarity relationships of the representations across subjects and modalities. To enable a robust training, we further introduce a modified conditional convolution to design a single model for encoding images of all modalities. Lastly, we propose a fusion function to combine the disentangled anatomical representations as a set of modality-invariant features for downstream tasks. We evaluate the proposed method on three multi-modal neuroimaging datasets. Experiments show that our proposed method can achieve superior disentangled representations compared to existing disentanglement strategies. Results also indicate that the fused anatomical representation has great potential in the downstream task of zero-dose PET reconstruction and brain tumor segmentation.
Recurrent Neural Networks with Longitudinal Pooling and Consistency Regularization
Mar 31, 2020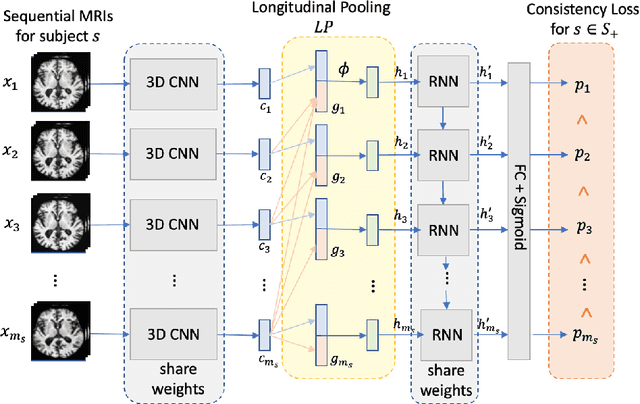

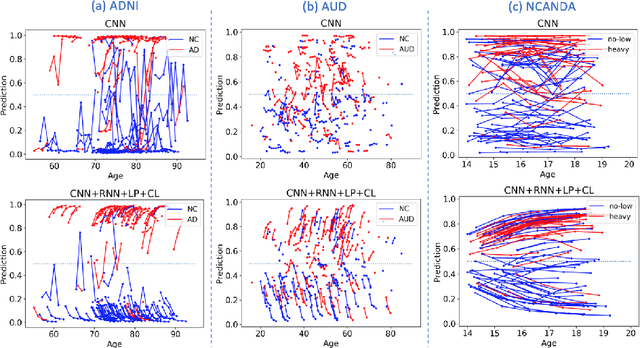

Most neurological diseases are characterized by gradual deterioration of brain structure and function. To identify the impact of such diseases, studies have been acquiring large longitudinal MRI datasets and applied deep-learning to predict diagnosis label(s). These learning models apply Convolutional Neural Networks (CNN) to extract informative features from each time point of the longitudinal MRI and Recurrent Neural Networks (RNN) to classify each time point based on those features. However, they neglect the progressive nature of the disease, which may result in clinically implausible predictions across visits. In this paper, we propose a framework that injects the extracted features from CNNs at each time point to the RNN cells considering the dependencies across different time points in the longitudinal data. On the feature level, we propose a novel longitudinal pooling layer to couple features of a visit with those of proceeding ones. On the prediction level, we add a consistency regularization to the classification objective in line with the nature of the disease progression across visits. We evaluate the proposed method on the longitudinal structural MRIs from three neuroimaging datasets: Alzheimer's Disease Neuroimaging Initiative (ADNI, N=404), a dataset composed of 274 healthy controls and 329 patients with Alcohol Use Disorder (AUD), and 255 youths from the National Consortium on Alcohol and NeuroDevelopment in Adolescence (NCANDA). All three experiments show that our method is superior to the widely used methods. The code is available at https://github.com/ouyangjiahong/longitudinal-pooling.