 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond validation loss: Clinically-tailored optimization metrics improve a model's clinical performance
Jan 22, 2026A key task in ML is to optimize models at various stages, e.g. by choosing hyperparameters or picking a stopping point. A traditional ML approach is to use validation loss, i.e. to apply the training loss function on a validation set to guide these optimizations. However, ML for healthcare has a distinct goal from traditional ML: Models must perform well relative to specific clinical requirements, vs. relative to the loss function used for training. These clinical requirements can be captured more precisely by tailored metrics. Since many optimization tasks do not require the driving metric to be differentiable, they allow a wider range of options, including the use of metrics tailored to be clinically-relevant. In this paper we describe two controlled experiments which show how the use of clinically-tailored metrics provide superior model optimization compared to validation loss, in the sense of better performance on the clinical task. The use of clinically-relevant metrics for optimization entails some extra effort, to define the metrics and to code them into the pipeline. But it can yield models that better meet the central goal of ML for healthcare: strong performance in the clinic.
Driving down Poisson error can offset classification error in clinical tasks
May 09, 2024Medical machine learning algorithms are typically evaluated based on accuracy vs. a clinician-defined ground truth, a reasonable choice because trained clinicians are usually better classifiers than ML models. However, this metric does not fully reflect the clinical task: it neglects the fact that humans, even with perfect accuracy, are subject to sometimes significant error from the Poisson statistics of rare events, because clinical protocols often specify that a relatively small sample be examined. For example, to quantitate malaria on a thin blood film a clinician examines only 2000 red blood cells (0.0004 uL), which can yield large variation in actual number of parasites present due to Poisson variability, so that a perfect human's count can differ substantially from the true average load. In contrast, ML systems may be less accurate on an object level, but they also may have the option to examine more blood (e.g. 0.1 uL, or 250x). So while their accuracy as to parasite count in a particular sample is lower, the Poisson variability of their estimate is also lower due to larger sample size. Crucially, when an ML system moves out of the proof-of-concept stage and targets deployment in a clinical setting, its performance must match current standard of care. To this end, it may have the option to offset its lower accuracy by increasing sample size to reduce Poisson error, and thus attain the same net clinical performance as a perfectly accurate human limited by smaller sample size. In this paper, we analyze the mathematics of the trade-off between these two types of error, to enable teams developing ML systems to leverage a relative strength (larger sample sizes) to offset a relative weakness (classification accuracy). We illustrate the methods with two concrete examples: diagnosis and quantitation of malaria on blood films.
Contrastive Self-Supervised Learning for Spatio-Temporal Analysis of Lung Ultrasound Videos
Oct 14, 2023Self-supervised learning (SSL) methods have shown promise for medical imaging applications by learning meaningful visual representations, even when the amount of labeled data is limited. Here, we extend state-of-the-art contrastive learning SSL methods to 2D+time medical ultrasound video data by introducing a modified encoder and augmentation method capable of learning meaningful spatio-temporal representations, without requiring constraints on the input data. We evaluate our method on the challenging clinical task of identifying lung consolidations (an important pathological feature) in ultrasound videos. Using a multi-center dataset of over 27k lung ultrasound videos acquired from over 500 patients, we show that our method can significantly improve performance on downstream localization and classification of lung consolidation. Comparisons against baseline models trained without SSL show that the proposed methods are particularly advantageous when the size of labeled training data is limited (e.g., as little as 5% of the training set).
How Good Are Synthetic Medical Images? An Empirical Study with Lung Ultrasound
Oct 05, 2023Acquiring large quantities of data and annotations is known to be effective for developing high-performing deep learning models, but is difficult and expensive to do in the healthcare context. Adding synthetic training data using generative models offers a low-cost method to deal effectively with the data scarcity challenge, and can also address data imbalance and patient privacy issues. In this study, we propose a comprehensive framework that fits seamlessly into model development workflows for medical image analysis. We demonstrate, with datasets of varying size, (i) the benefits of generative models as a data augmentation method; (ii) how adversarial methods can protect patient privacy via data substitution; (iii) novel performance metrics for these use cases by testing models on real holdout data. We show that training with both synthetic and real data outperforms training with real data alone, and that models trained solely with synthetic data approach their real-only counterparts. Code is available at https://github.com/Global-Health-Labs/US-DCGAN.
Weakly Semi-Supervised Detection in Lung Ultrasound Videos
Aug 08, 2023Frame-by-frame annotation of bounding boxes by clinical experts is often required to train fully supervised object detection models on medical video data. We propose a method for improving object detection in medical videos through weak supervision from video-level labels. More concretely, we aggregate individual detection predictions into video-level predictions and extend a teacher-student training strategy to provide additional supervision via a video-level loss. We also introduce improvements to the underlying teacher-student framework, including methods to improve the quality of pseudo-labels based on weak supervision and adaptive schemes to optimize knowledge transfer between the student and teacher networks. We apply this approach to the clinically important task of detecting lung consolidations (seen in respiratory infections such as COVID-19 pneumonia) in medical ultrasound videos. Experiments reveal that our framework improves detection accuracy and robustness compared to baseline semi-supervised models, and improves efficiency in data and annotation usage.
Fully-automated patient-level malaria assessment on field-prepared thin blood film microscopy images, including Supplementary Information
Aug 05, 2019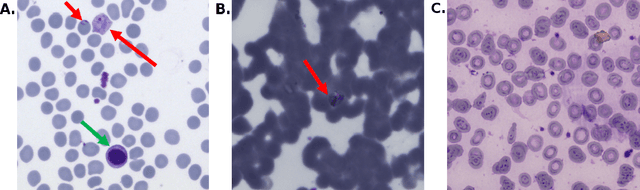
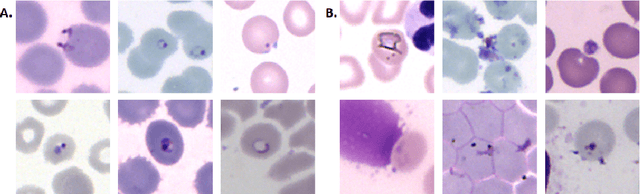
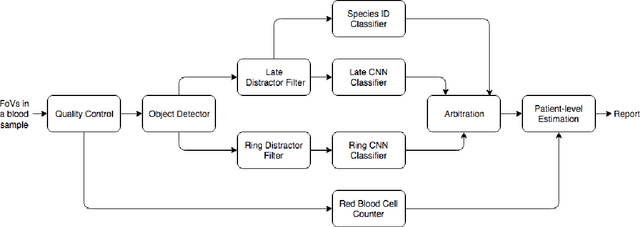
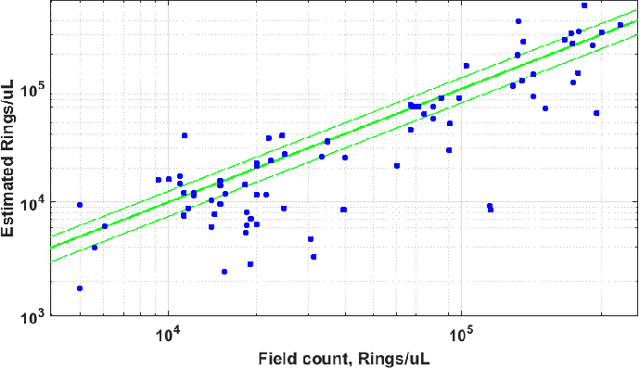
Malaria is a life-threatening disease affecting millions. Microscopy-based assessment of thin blood films is a standard method to (i) determine malaria species and (ii) quantitate high-parasitemia infections. Full automation of malaria microscopy by machine learning (ML) is a challenging task because field-prepared slides vary widely in quality and presentation, and artifacts often heavily outnumber relatively rare parasites. In this work, we describe a complete, fully-automated framework for thin film malaria analysis that applies ML methods, including convolutional neural nets (CNNs), trained on a large and diverse dataset of field-prepared thin blood films. Quantitation and species identification results are close to sufficiently accurate for the concrete needs of drug resistance monitoring and clinical use-cases on field-prepared samples. We focus our methods and our performance metrics on the field use-case requirements. We discuss key issues and important metrics for the application of ML methods to malaria microscopy.
Money on the Table: Statistical information ignored by Softmax can improve classifier accuracy
Jan 26, 2019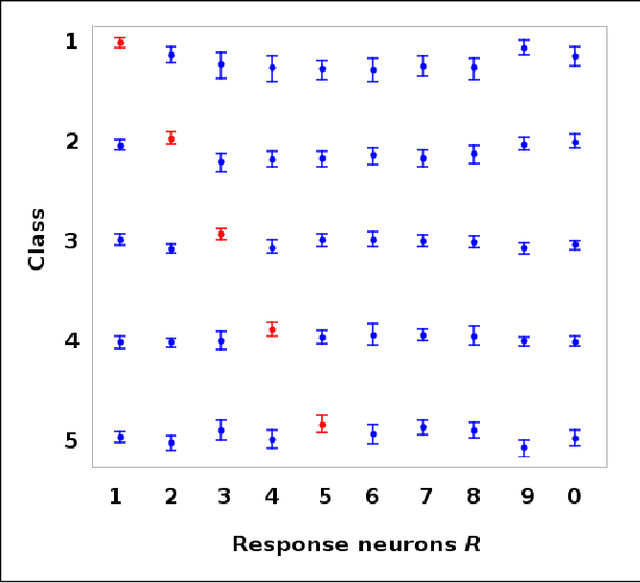
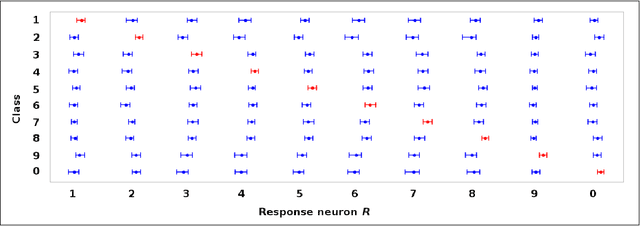
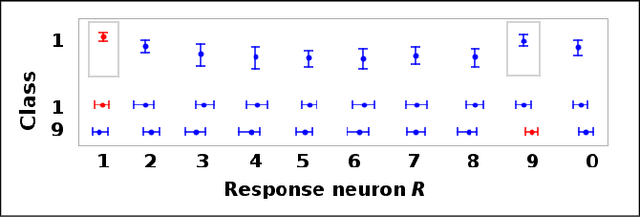
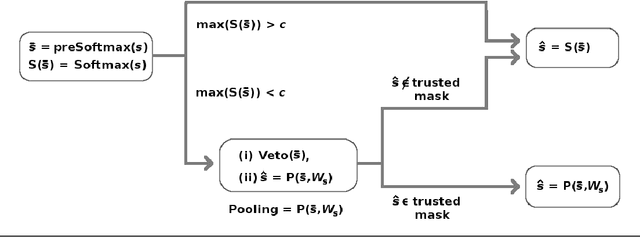
Softmax is a standard final layer used in Neural Nets (NNs) to summarize information encoded in the trained NN and return a prediction. However, Softmax leverages only a subset of the class-specific structure encoded in the trained model and ignores potentially valuable information: During training, models encode an array $D$ of class response distributions, where $D_{ij}$ is the distribution of the $j^{th}$ pre-Softmax readout neuron's responses to the $i^{th}$ class. Given a test sample, Softmax implicitly uses only the row of this array $D$ that corresponds to the readout neurons' responses to the sample's true class. Leveraging more of this array $D$ can improve classifier accuracy, because the likelihoods of two competing classes can be encoded in other rows of $D$. To explore this potential resource, we develop a hybrid classifier (Softmax-Pooling Hybrid, $SPH$) that uses Softmax on high-scoring samples, but on low-scoring samples uses a log-likelihood method that pools the information from the full array $D$. We apply $SPH$ to models trained on a vectorized MNIST dataset to varying levels of accuracy. $SPH$ replaces only the final Softmax layer in the trained NN, at test time only. All training is the same as for Softmax. Because the pooling classifier performs better than Softmax on low-scoring samples, $SPH$ reduces test set error by 6% to 23%, using the exact same trained model, whatever the baseline Softmax accuracy. This reduction in error reflects hidden capacity of the trained NN that is left unused by Softmax.