 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-inspired tail oscillation enables robot fast crawling on deformable granular terrains
Sep 15, 2025



Deformable substrates such as sand and mud present significant challenges for terrestrial robots due to complex robot-terrain interactions. Inspired by mudskippers, amphibious animals that naturally adjust their tail morphology and movement jointly to navigate such environments, we investigate how tail design and control can jointly enhance flipper-driven locomotion on granular media. Using a bio-inspired robot modeled after the mudskipper, we experimentally compared locomotion performance between idle and actively oscillating tail configurations. Tail oscillation increased robot speed by 67% and reduced body drag by 46%. Shear force measurements revealed that this improvement was enabled by tail oscillation fluidizing the substrate, thereby reducing resistance. Additionally, tail morphology strongly influenced the oscillation strategy: designs with larger horizontal surface areas leveraged the oscillation-reduced shear resistance more effectively by limiting insertion depth. Based on these findings, we present a design principle to inform tail action selection based on substrate strength and tail morphology. Our results offer new insights into tail design and control for improving robot locomotion on deformable substrates, with implications for agricultural robotics, search and rescue, and environmental exploration.
Securing Genomic Data Against Inference Attacks in Federated Learning Environments
May 12, 2025



Federated Learning (FL) offers a promising framework for collaboratively training machine learning models across decentralized genomic datasets without direct data sharing. While this approach preserves data locality, it remains susceptible to sophisticated inference attacks that can compromise individual privacy. In this study, we simulate a federated learning setup using synthetic genomic data and assess its vulnerability to three key attack vectors: Membership Inference Attack (MIA), Gradient-Based Membership Inference Attack, and Label Inference Attack (LIA). Our experiments reveal that Gradient-Based MIA achieves the highest effectiveness, with a precision of 0.79 and F1-score of 0.87, underscoring the risk posed by gradient exposure in federated updates. Additionally, we visualize comparative attack performance through radar plots and quantify model leakage across clients. The findings emphasize the inadequacy of na\"ive FL setups in safeguarding genomic privacy and motivate the development of more robust privacy-preserving mechanisms tailored to the unique sensitivity of genomic data.
Ultrasound Image Synthesis Using Generative AI for Lung Ultrasound Detection
Jan 10, 2025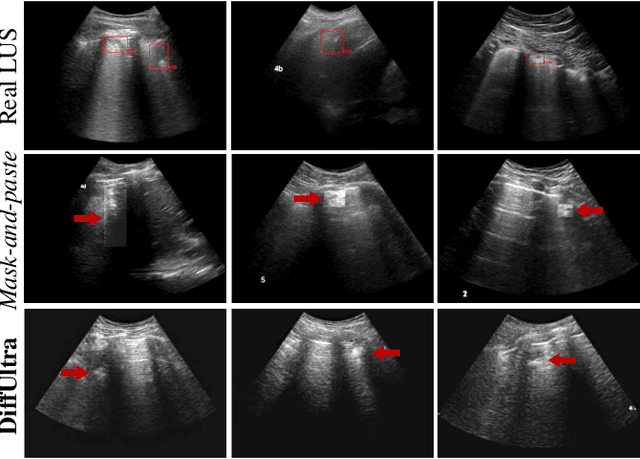

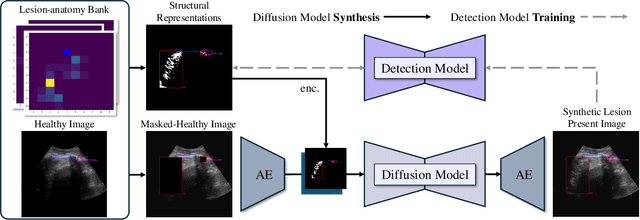

Developing reliable healthcare AI models requires training with representative and diverse data. In imbalanced datasets, model performance tends to plateau on the more prevalent classes while remaining low on less common cases. To overcome this limitation, we propose DiffUltra, the first generative AI technique capable of synthesizing realistic Lung Ultrasound (LUS) images with extensive lesion variability. Specifically, we condition the generative AI by the introduced Lesion-anatomy Bank, which captures the lesion's structural and positional properties from real patient data to guide the image synthesis.We demonstrate that DiffUltra improves consolidation detection by 5.6% in AP compared to the models trained solely on real patient data. More importantly, DiffUltra increases data diversity and prevalence of rare cases, leading to a 25% AP improvement in detecting rare instances such as large lung consolidations, which make up only 10% of the dataset.
SAM Fewshot Finetuning for Anatomical Segmentation in Medical Images
Jul 05, 2024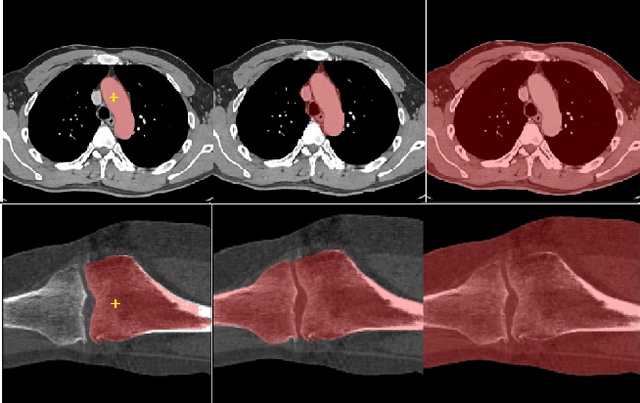
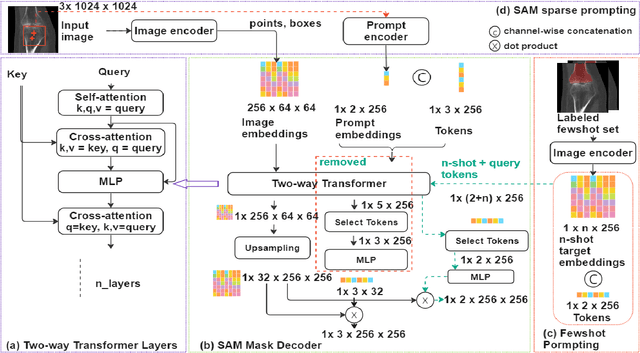
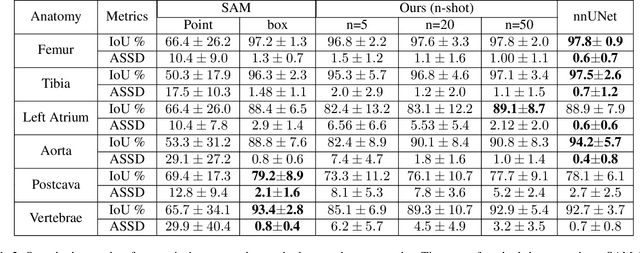
We propose a straightforward yet highly effective few-shot fine-tuning strategy for adapting the Segment Anything (SAM) to anatomical segmentation tasks in medical images. Our novel approach revolves around reformulating the mask decoder within SAM, leveraging few-shot embeddings derived from a limited set of labeled images (few-shot collection) as prompts for querying anatomical objects captured in image embeddings. This innovative reformulation greatly reduces the need for time-consuming online user interactions for labeling volumetric images, such as exhaustively marking points and bounding boxes to provide prompts slice by slice. With our method, users can manually segment a few 2D slices offline, and the embeddings of these annotated image regions serve as effective prompts for online segmentation tasks. Our method prioritizes the efficiency of the fine-tuning process by exclusively training the mask decoder through caching mechanisms while keeping the image encoder frozen. Importantly, this approach is not limited to volumetric medical images, but can generically be applied to any 2D/3D segmentation task. To thoroughly evaluate our method, we conducted extensive validation on four datasets, covering six anatomical segmentation tasks across two modalities. Furthermore, we conducted a comparative analysis of different prompting options within SAM and the fully-supervised nnU-Net. The results demonstrate the superior performance of our method compared to SAM employing only point prompts (approximately 50% improvement in IoU) and performs on-par with fully supervised methods whilst reducing the requirement of labeled data by at least an order of magnitude.
Contrastive Self-Supervised Learning for Spatio-Temporal Analysis of Lung Ultrasound Videos
Oct 14, 2023Self-supervised learning (SSL) methods have shown promise for medical imaging applications by learning meaningful visual representations, even when the amount of labeled data is limited. Here, we extend state-of-the-art contrastive learning SSL methods to 2D+time medical ultrasound video data by introducing a modified encoder and augmentation method capable of learning meaningful spatio-temporal representations, without requiring constraints on the input data. We evaluate our method on the challenging clinical task of identifying lung consolidations (an important pathological feature) in ultrasound videos. Using a multi-center dataset of over 27k lung ultrasound videos acquired from over 500 patients, we show that our method can significantly improve performance on downstream localization and classification of lung consolidation. Comparisons against baseline models trained without SSL show that the proposed methods are particularly advantageous when the size of labeled training data is limited (e.g., as little as 5% of the training set).
Weakly Semi-Supervised Detection in Lung Ultrasound Videos
Aug 08, 2023Frame-by-frame annotation of bounding boxes by clinical experts is often required to train fully supervised object detection models on medical video data. We propose a method for improving object detection in medical videos through weak supervision from video-level labels. More concretely, we aggregate individual detection predictions into video-level predictions and extend a teacher-student training strategy to provide additional supervision via a video-level loss. We also introduce improvements to the underlying teacher-student framework, including methods to improve the quality of pseudo-labels based on weak supervision and adaptive schemes to optimize knowledge transfer between the student and teacher networks. We apply this approach to the clinically important task of detecting lung consolidations (seen in respiratory infections such as COVID-19 pneumonia) in medical ultrasound videos. Experiments reveal that our framework improves detection accuracy and robustness compared to baseline semi-supervised models, and improves efficiency in data and annotation usage.