 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Federated Fraud Detection in Payment Transactions with NVIDIA FLARE
Mar 13, 2026Fraud-related financial losses continue to rise, while regulatory, privacy, and data-sovereignty constraints increasingly limit the feasibility of centralized fraud detection systems. Federated Learning (FL) has emerged as a promising paradigm for enabling collaborative model training across institutions without sharing raw transaction data. Yet, its practical effectiveness under realistic, non-IID financial data distributions remains insufficiently validated. In this work, we present a multi-institution, industry-oriented proof-of-concept study evaluating federated anomaly detection for payment transactions using the NVIDIA FLARE framework. We simulate a realistic federation of heterogeneous financial institutions, each observing distinct fraud typologies and operating under strict data isolation. Using a deep neural network trained via federated averaging (FedAvg), we demonstrate that federated models achieve a mean F1-score of 0.903 - substantially outperforming locally trained models (0.643) and closely approaching centralized training performance (0.925), while preserving full data sovereignty. We further analyze convergence behavior, showing that strong performance is achieved within 10 federated communication rounds, highlighting the operational viability of FL in latency- and cost-sensitive financial environments. To support deployment in regulated settings, we evaluate model interpretability using Shapley-based feature attribution and confirm that federated models rely on semantically coherent, domain-relevant decision signals. Finally, we incorporate sample-level differential privacy via DP-SGD and demonstrate favorable privacy-utility trade-offs...
FHAIM: Fully Homomorphic AIM For Private Synthetic Data Generation
Feb 05, 2026Data is the lifeblood of AI, yet much of the most valuable data remains locked in silos due to privacy and regulations. As a result, AI remains heavily underutilized in many of the most important domains, including healthcare, education, and finance. Synthetic data generation (SDG), i.e. the generation of artificial data with a synthesizer trained on real data, offers an appealing solution to make data available while mitigating privacy concerns, however existing SDG-as-a-service workflow require data holders to trust providers with access to private data.We propose FHAIM, the first fully homomorphic encryption (FHE) framework for training a marginal-based synthetic data generator on encrypted tabular data. FHAIM adapts the widely used AIM algorithm to the FHE setting using novel FHE protocols, ensuring that the private data remains encrypted throughout and is released only with differential privacy guarantees. Our empirical analysis show that FHAIM preserves the performance of AIM while maintaining feasible runtimes.
SAMAY: System for Acoustic Measurement and Analysis
Dec 15, 2025This paper describes an automatic bird call recording system called SAMAY, which is developed to study bird species by creating a database of large amounts of bird acoustic data. By analysing the recorded bird call data, the system can also be used for automatic classification of bird species, monitoring bird populations and analysing the impact of environmental changes. The system is driven through a powerful STM32F407 series microcontroller, supports 4 microphones, is equipped with 128 GB of storage capacity, and is powered by a 10400 mAh battery pack interfaced with a solar charger. In addition, the device is user-configurable over USB and Wi-Fi during runtime, ensuring user-friendly operation during field deployment.
TFHE-Coder: Evaluating LLM-agentic Fully Homomorphic Encryption Code Generation
Mar 15, 2025



Fully Homomorphic Encryption over the torus (TFHE) enables computation on encrypted data without decryption, making it a cornerstone of secure and confidential computing. Despite its potential in privacy preserving machine learning, secure multi party computation, private blockchain transactions, and secure medical diagnostics, its adoption remains limited due to cryptographic complexity and usability challenges. While various TFHE libraries and compilers exist, practical code generation remains a hurdle. We propose a compiler integrated framework to evaluate LLM inference and agentic optimization for TFHE code generation, focusing on logic gates and ReLU activation. Our methodology assesses error rates, compilability, and structural similarity across open and closedsource LLMs. Results highlight significant limitations in off-the-shelf models, while agentic optimizations such as retrieval augmented generation (RAG) and few-shot prompting reduce errors and enhance code fidelity. This work establishes the first benchmark for TFHE code generation, demonstrating how LLMs, when augmented with domain-specific feedback, can bridge the expertise gap in FHE code generation.
SAM Fewshot Finetuning for Anatomical Segmentation in Medical Images
Jul 05, 2024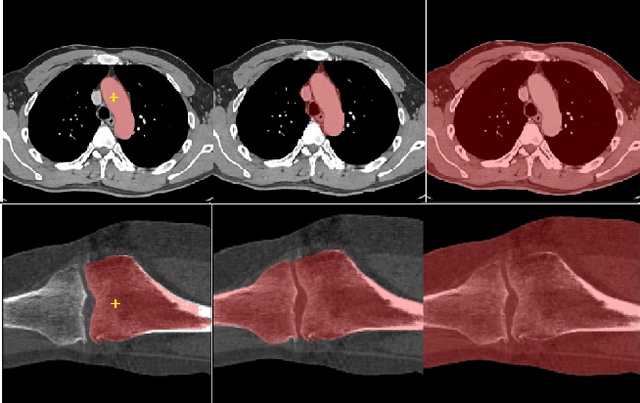
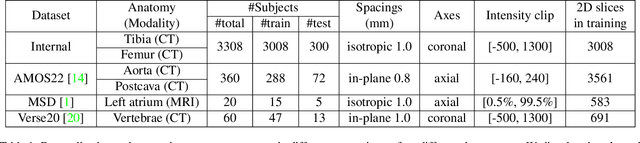
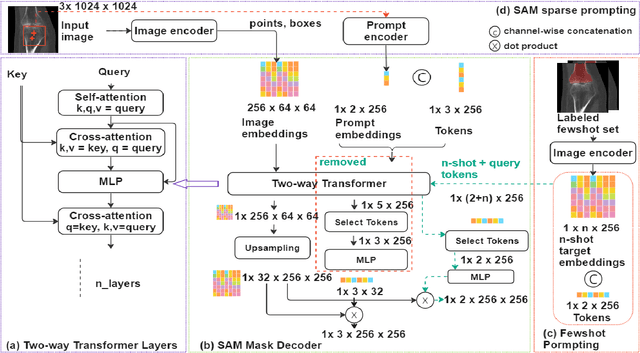
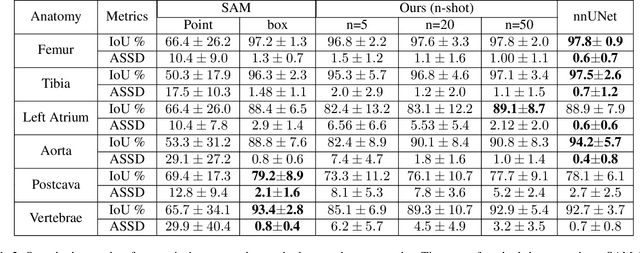
We propose a straightforward yet highly effective few-shot fine-tuning strategy for adapting the Segment Anything (SAM) to anatomical segmentation tasks in medical images. Our novel approach revolves around reformulating the mask decoder within SAM, leveraging few-shot embeddings derived from a limited set of labeled images (few-shot collection) as prompts for querying anatomical objects captured in image embeddings. This innovative reformulation greatly reduces the need for time-consuming online user interactions for labeling volumetric images, such as exhaustively marking points and bounding boxes to provide prompts slice by slice. With our method, users can manually segment a few 2D slices offline, and the embeddings of these annotated image regions serve as effective prompts for online segmentation tasks. Our method prioritizes the efficiency of the fine-tuning process by exclusively training the mask decoder through caching mechanisms while keeping the image encoder frozen. Importantly, this approach is not limited to volumetric medical images, but can generically be applied to any 2D/3D segmentation task. To thoroughly evaluate our method, we conducted extensive validation on four datasets, covering six anatomical segmentation tasks across two modalities. Furthermore, we conducted a comparative analysis of different prompting options within SAM and the fully-supervised nnU-Net. The results demonstrate the superior performance of our method compared to SAM employing only point prompts (approximately 50% improvement in IoU) and performs on-par with fully supervised methods whilst reducing the requirement of labeled data by at least an order of magnitude.
Detecting Errors in Numerical Data via any Regression Model
Jun 03, 2023Noise plagues many numerical datasets, where the recorded values in the data may fail to match the true underlying values due to reasons including: erroneous sensors, data entry/processing mistakes, or imperfect human estimates. Here we consider estimating which data values are incorrect along a numerical column. We present a model-agnostic approach that can utilize any regressor (i.e. statistical or machine learning model) which was fit to predict values in this column based on the other variables in the dataset. By accounting for various uncertainties, our approach distinguishes between genuine anomalies and natural data fluctuations, conditioned on the available information in the dataset. We establish theoretical guarantees for our method and show that other approaches like conformal inference struggle to detect errors. We also contribute a new error detection benchmark involving 5 regression datasets with real-world numerical errors (for which the true values are also known). In this benchmark and additional simulation studies, our method identifies incorrect values with better precision/recall than other approaches.
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Oct 18, 2022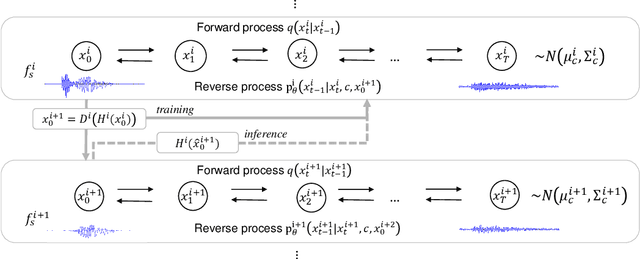
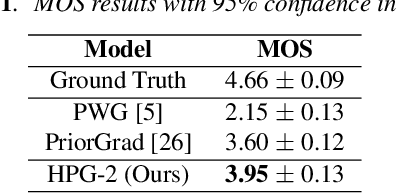
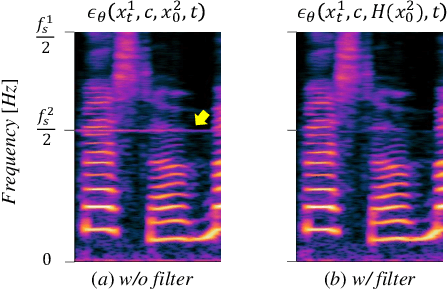
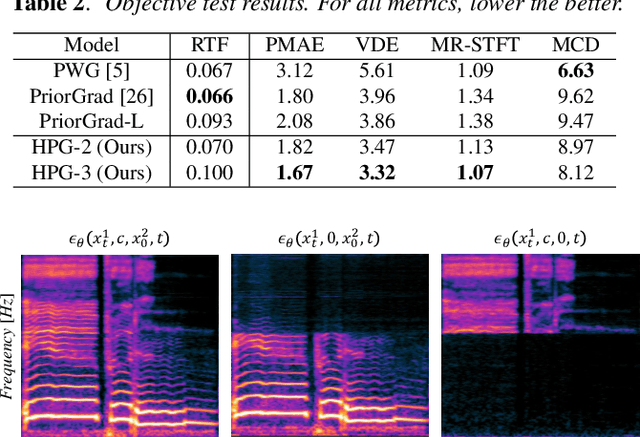
Recent progress in deep generative models has improved the quality of neural vocoders in speech domain. However, generating a high-quality singing voice remains challenging due to a wider variety of musical expressions in pitch, loudness, and pronunciations. In this work, we propose a hierarchical diffusion model for singing voice neural vocoders. The proposed method consists of multiple diffusion models operating in different sampling rates; the model at the lowest sampling rate focuses on generating accurate low-frequency components such as pitch, and other models progressively generate the waveform at higher sampling rates on the basis of the data at the lower sampling rate and acoustic features. Experimental results show that the proposed method produces high-quality singing voices for multiple singers, outperforming state-of-the-art neural vocoders with a similar range of computational costs.
DistancePPG: Robust non-contact vital signs monitoring using a camera
Mar 24, 2015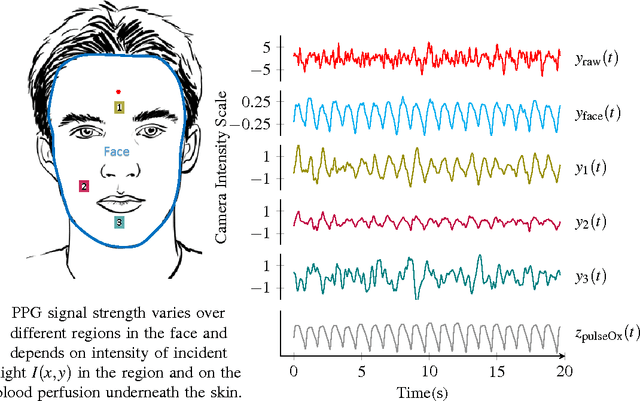

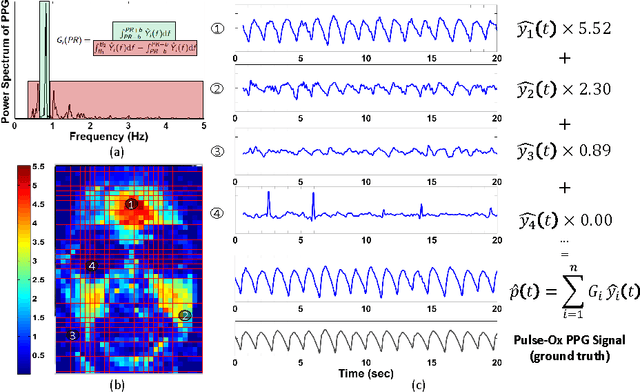
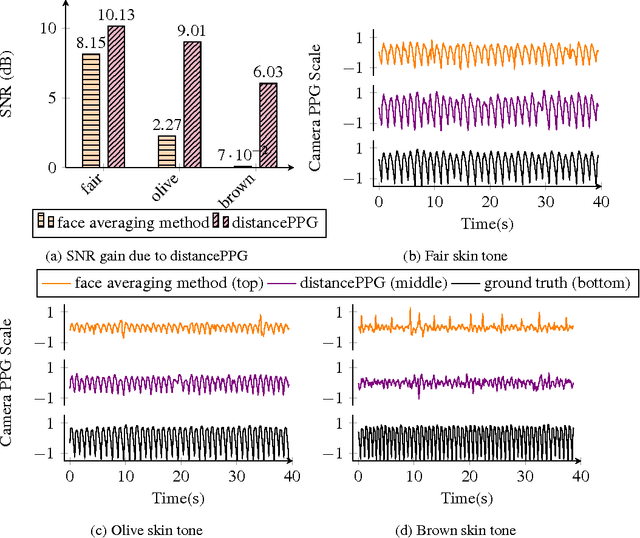
Vital signs such as pulse rate and breathing rate are currently measured using contact probes. But, non-contact methods for measuring vital signs are desirable both in hospital settings (e.g. in NICU) and for ubiquitous in-situ health tracking (e.g. on mobile phone and computers with webcams). Recently, camera-based non-contact vital sign monitoring have been shown to be feasible. However, camera-based vital sign monitoring is challenging for people with darker skin tone, under low lighting conditions, and/or during movement of an individual in front of the camera. In this paper, we propose distancePPG, a new camera-based vital sign estimation algorithm which addresses these challenges. DistancePPG proposes a new method of combining skin-color change signals from different tracked regions of the face using a weighted average, where the weights depend on the blood perfusion and incident light intensity in the region, to improve the signal-to-noise ratio (SNR) of camera-based estimate. One of our key contributions is a new automatic method for determining the weights based only on the video recording of the subject. The gains in SNR of camera-based PPG estimated using distancePPG translate into reduction of the error in vital sign estimation, and thus expand the scope of camera-based vital sign monitoring to potentially challenging scenarios. Further, a dataset will be released, comprising of synchronized video recordings of face and pulse oximeter based ground truth recordings from the earlobe for people with different skin tones, under different lighting conditions and for various motion scenarios.