 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Diffusion Models for Singing Voice Neural Vocoder
Oct 18, 2022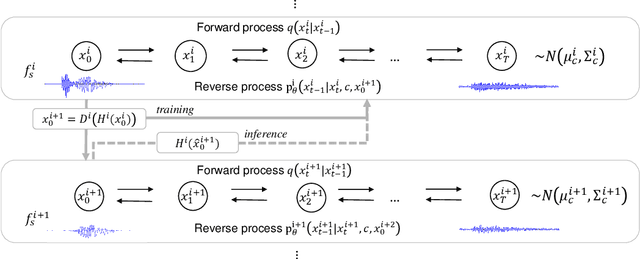
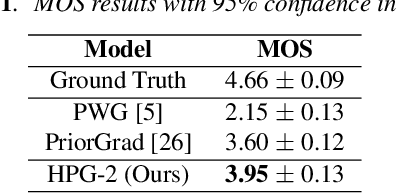
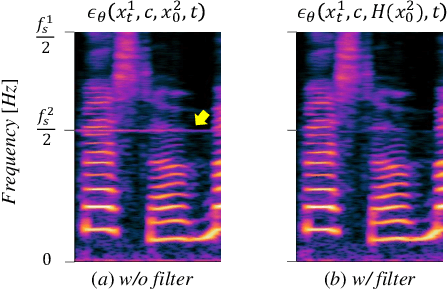
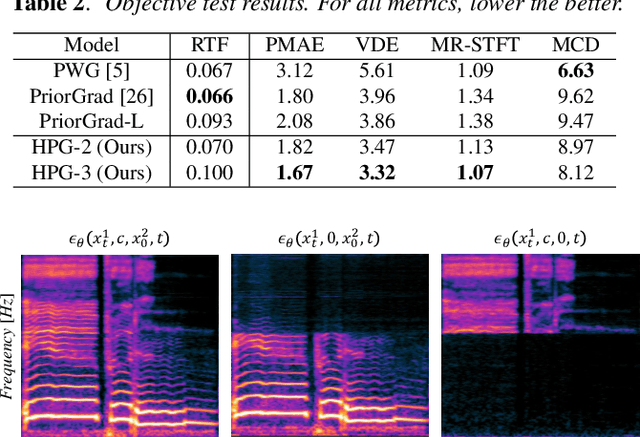
Recent progress in deep generative models has improved the quality of neural vocoders in speech domain. However, generating a high-quality singing voice remains challenging due to a wider variety of musical expressions in pitch, loudness, and pronunciations. In this work, we propose a hierarchical diffusion model for singing voice neural vocoders. The proposed method consists of multiple diffusion models operating in different sampling rates; the model at the lowest sampling rate focuses on generating accurate low-frequency components such as pitch, and other models progressively generate the waveform at higher sampling rates on the basis of the data at the lower sampling rate and acoustic features. Experimental results show that the proposed method produces high-quality singing voices for multiple singers, outperforming state-of-the-art neural vocoders with a similar range of computational costs.