 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Data Curation for Robust Language Model Fine-Tuning
Mar 19, 2024



Large Language Models have become the de facto approach to sequence-to-sequence text generation tasks, but for specialized tasks/domains, a pretrained LLM lacks specific capabilities to produce accurate or well-formatted responses. Supervised fine-tuning specializes a LLM by training it on dataset of example prompts with target responses, but real-world data tends to be noisy. While many fine-tuning algorithms exist, here we consider a \emph{data-centric AI} perspective on LLM fine-tuning, studying how to \emph{systematically} curate the training dataset to improve the LLM produced via \emph{any} fine-tuning algorithm. We introduce an automated data curation pipeline CLEAR (Confidence-based LLM Evaluation And Rectification) for instruction tuning datasets, that can be used with any LLM and fine-tuning procedure. CLEAR estimates which training data is low-quality and either filters or corrects it. Automatically identifying which data to filter or correct is done via LLM-derived confidence estimates, to ensure only confident modifications to the dataset. Unlike existing data curation techniques, CLEAR is a comprehensive framework that can improve a dataset (and trained model outputs) without additional fine-tuning computations. We don't assume access to a stronger LLM than the model being fine-tuned (e.g.\ relying on GPT-4 when fine-tuning GPT-3.5), to see whether CLEAR can meaningfully improve the capabilities of any LLM. Experiments reveal that CLEAR consistently improves the performance of fine-tuned models across many datasets and models (like GPT-3.5 and Llama2).
ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data
Sep 02, 2023Despite powering sensitive systems like autonomous vehicles, object detection remains fairly brittle in part due to annotation errors that plague most real-world training datasets. We propose ObjectLab, a straightforward algorithm to detect diverse errors in object detection labels, including: overlooked bounding boxes, badly located boxes, and incorrect class label assignments. ObjectLab utilizes any trained object detection model to score the label quality of each image, such that mislabeled images can be automatically prioritized for label review/correction. Properly handling erroneous data enables training a better version of the same object detection model, without any change in existing modeling code. Across different object detection datasets (including COCO) and different models (including Detectron-X101 and Faster-RCNN), ObjectLab consistently detects annotation errors with much better precision/recall compared to other label quality scores.
Quantifying Uncertainty in Answers from any Language Model via Intrinsic and Extrinsic Confidence Assessment
Aug 30, 2023We introduce BSDetector, a method for detecting bad and speculative answers from a pretrained Large Language Model by estimating a numeric confidence score for any output it generated. Our uncertainty quantification technique works for any LLM accessible only via a black-box API, and combines intrinsic and extrinsic assessments of confidence into a single trustworthiness estimate for any LLM response to a given prompt. Our method is extremely general and can applied to all of the best LLMs available today (whose training data remains unknown). By expending a bit of extra computation, users of any LLM API can now get the same response as they would ordinarily, as well as a confidence estimate that caution when not to trust this response. Experiments on both closed and open-form Question-Answer benchmarks reveal that BSDetector more accurately identifies incorrect LLM responses than alternative uncertainty estimation procedures (for both GPT-3 and ChatGPT). By sampling multiple responses from the LLM and considering the one with the highest confidence score, we can additionally obtain more accurate responses from the same LLM, without any extra training steps.
Estimating label quality and errors in semantic segmentation data via any model
Jul 11, 2023
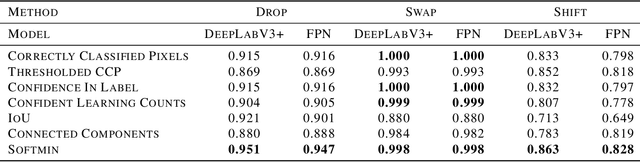

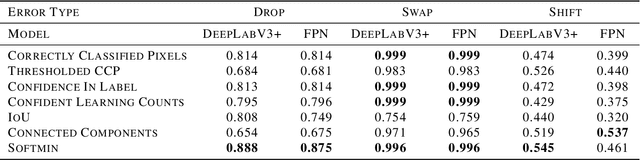
The labor-intensive annotation process of semantic segmentation datasets is often prone to errors, since humans struggle to label every pixel correctly. We study algorithms to automatically detect such annotation errors, in particular methods to score label quality, such that the images with the lowest scores are least likely to be correctly labeled. This helps prioritize what data to review in order to ensure a high-quality training/evaluation dataset, which is critical in sensitive applications such as medical imaging and autonomous vehicles. Widely applicable, our label quality scores rely on probabilistic predictions from a trained segmentation model -- any model architecture and training procedure can be utilized. Here we study 7 different label quality scoring methods used in conjunction with a DeepLabV3+ or a FPN segmentation model to detect annotation errors in a version of the SYNTHIA dataset. Precision-recall evaluations reveal a score -- the soft-minimum of the model-estimated likelihoods of each pixel's annotated class -- that is particularly effective to identify images that are mislabeled, across multiple types of annotation error.
Detecting Errors in Numerical Data via any Regression Model
Jun 03, 2023Noise plagues many numerical datasets, where the recorded values in the data may fail to match the true underlying values due to reasons including: erroneous sensors, data entry/processing mistakes, or imperfect human estimates. Here we consider estimating which data values are incorrect along a numerical column. We present a model-agnostic approach that can utilize any regressor (i.e. statistical or machine learning model) which was fit to predict values in this column based on the other variables in the dataset. By accounting for various uncertainties, our approach distinguishes between genuine anomalies and natural data fluctuations, conditioned on the available information in the dataset. We establish theoretical guarantees for our method and show that other approaches like conformal inference struggle to detect errors. We also contribute a new error detection benchmark involving 5 regression datasets with real-world numerical errors (for which the true values are also known). In this benchmark and additional simulation studies, our method identifies incorrect values with better precision/recall than other approaches.
Detecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors
May 25, 2023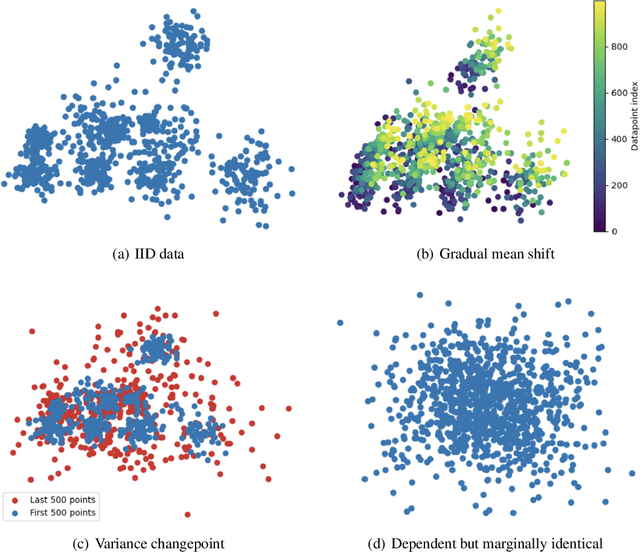
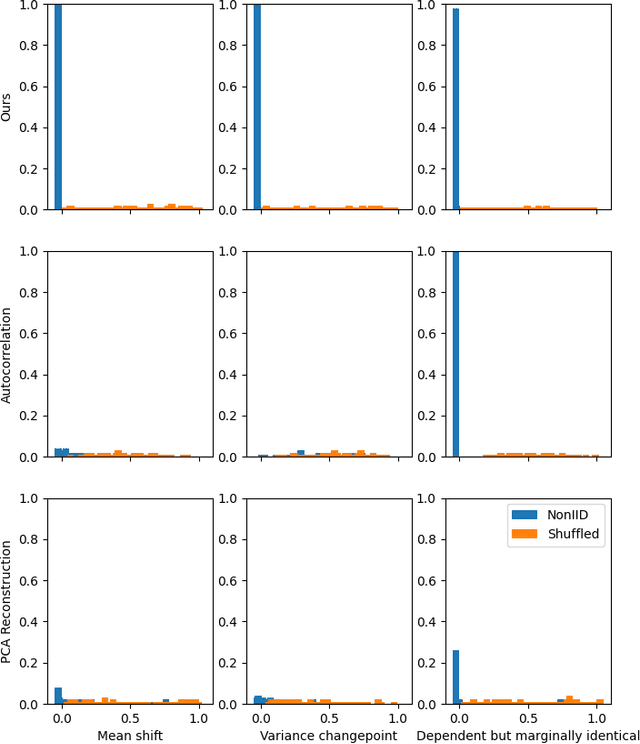
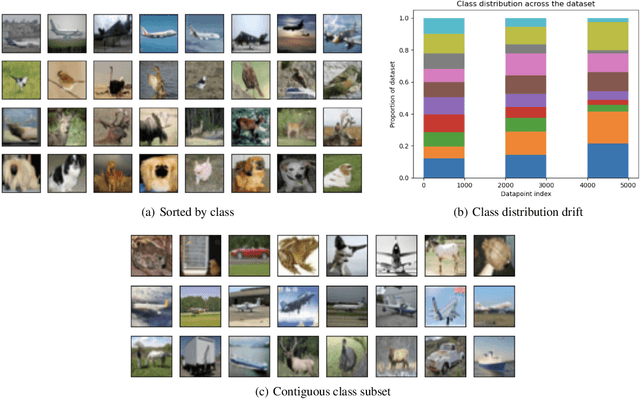
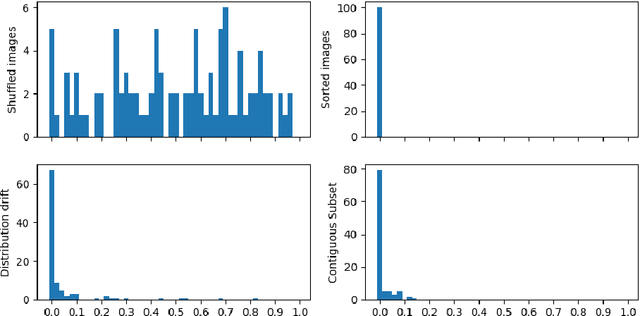
We present a straightforward statistical test to detect certain violations of the assumption that the data are Independent and Identically Distributed (IID). The specific form of violation considered is common across real-world applications: whether the examples are ordered in the dataset such that almost adjacent examples tend to have more similar feature values (e.g. due to distributional drift, or attractive interactions between datapoints). Based on a k-Nearest Neighbors estimate, our approach can be used to audit any multivariate numeric data as well as other data types (image, text, audio, etc.) that can be numerically represented, perhaps with model embeddings. Compared with existing methods to detect drift or auto-correlation, our approach is both applicable to more types of data and also able to detect a wider variety of IID violations in practice. Code: https://github.com/cleanlab/cleanlab
ActiveLab: Active Learning with Re-Labeling by Multiple Annotators
Jan 27, 2023In real-world data labeling applications, annotators often provide imperfect labels. It is thus common to employ multiple annotators to label data with some overlap between their examples. We study active learning in such settings, aiming to train an accurate classifier by collecting a dataset with the fewest total annotations. Here we propose ActiveLab, a practical method to decide what to label next that works with any classifier model and can be used in pool-based batch active learning with one or multiple annotators. ActiveLab automatically estimates when it is more informative to re-label examples vs. labeling entirely new ones. This is a key aspect of producing high quality labels and trained models within a limited annotation budget. In experiments on image and tabular data, ActiveLab reliably trains more accurate classifiers with far fewer annotations than a wide variety of popular active learning methods.
Identifying Incorrect Annotations in Multi-Label Classification Data
Nov 25, 2022In multi-label classification, each example in a dataset may be annotated as belonging to one or more classes (or none of the classes). Example applications include image (or document) tagging where each possible tag either applies to a particular image (or document) or not. With many possible classes to consider, data annotators are likely to make errors when labeling such data in practice. Here we consider algorithms for finding mislabeled examples in multi-label classification datasets. We propose an extension of the Confident Learning framework to this setting, as well as a label quality score that ranks examples with label errors much higher than those which are correctly labeled. Both approaches can utilize any trained classifier. After demonstrating that our methodology empirically outperforms other algorithms for label error detection, we apply our approach to discover many label errors in the CelebA image tagging dataset.
Utilizing supervised models to infer consensus labels and their quality from data with multiple annotators
Oct 13, 2022


Real-world data for classification is often labeled by multiple annotators. For analyzing such data, we introduce CROWDLAB, a straightforward approach to estimate: (1) A consensus label for each example that aggregates the individual annotations (more accurately than aggregation via majority-vote or other algorithms used in crowdsourcing); (2) A confidence score for how likely each consensus label is correct (via well-calibrated estimates that account for the number of annotations for each example and their agreement, prediction-confidence from a trained classifier, and trustworthiness of each annotator vs. the classifier); (3) A rating for each annotator quantifying the overall correctness of their labels. While many algorithms have been proposed to estimate related quantities in crowdsourcing, these often rely on sophisticated generative models with iterative inference schemes, whereas CROWDLAB is based on simple weighted ensembling. Many algorithms also rely solely on annotator statistics, ignoring the features of the examples from which the annotations derive. CROWDLAB in contrast utilizes any classifier model trained on these features, which can generalize between examples with similar features. In evaluations on real-world multi-annotator image data, our proposed method provides superior estimates for (1)-(3) than many alternative algorithms.
Detecting Label Errors in Token Classification Data
Oct 08, 2022
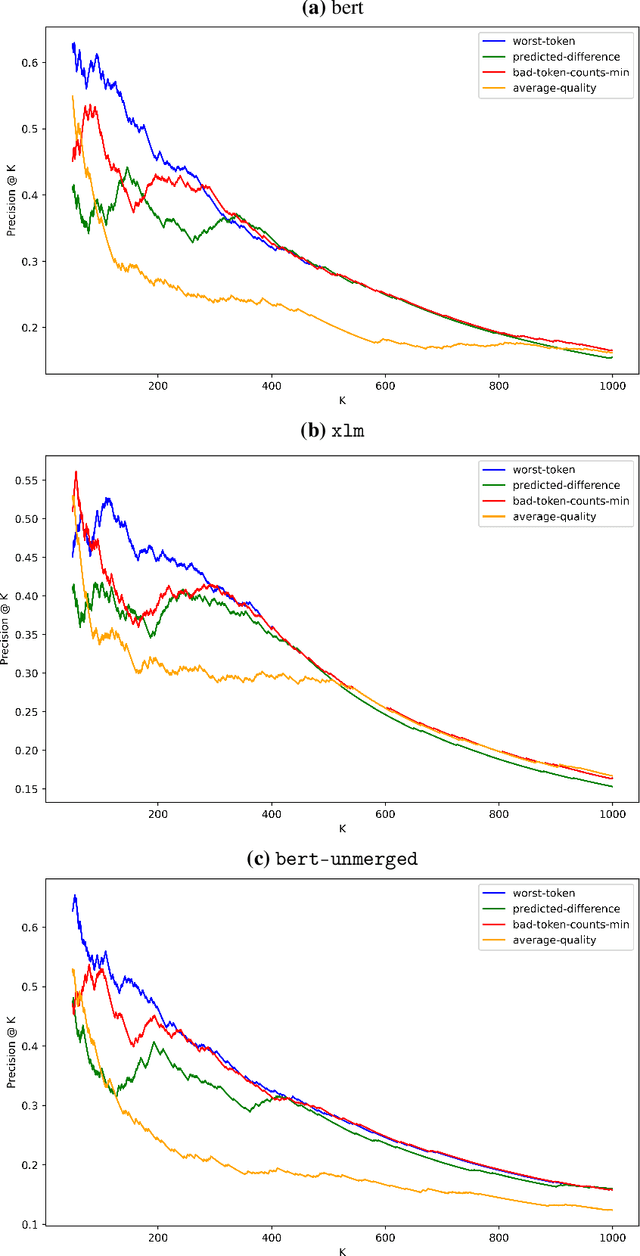
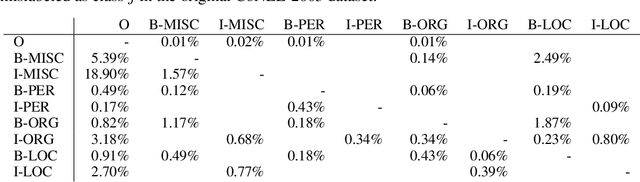
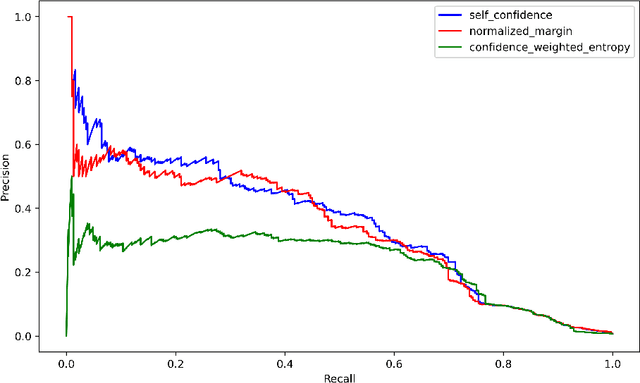
Mislabeled examples are a common issue in real-world data, particularly for tasks like token classification where many labels must be chosen on a fine-grained basis. Here we consider the task of finding sentences that contain label errors in token classification datasets. We study 11 different straightforward methods that score tokens/sentences based on the predicted class probabilities output by a (any) token classification model (trained via any procedure). In precision-recall evaluations based on real-world label errors in entity recognition data from CoNLL-2003, we identify a simple and effective method that consistently detects those sentences containing label errors when applied with different token classification models.