 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors
May 25, 2023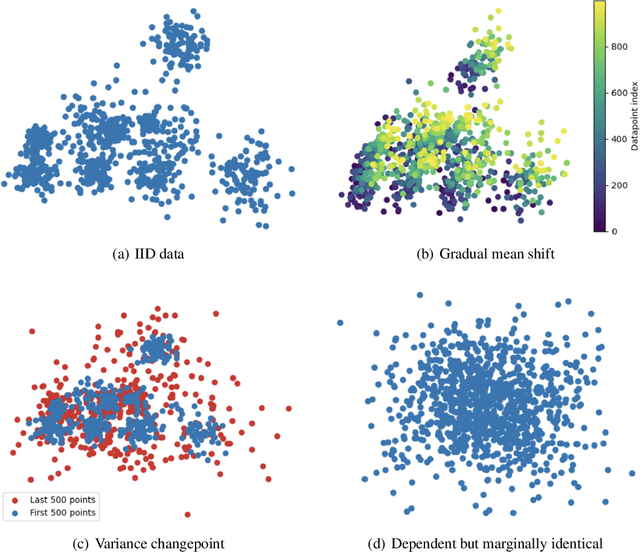
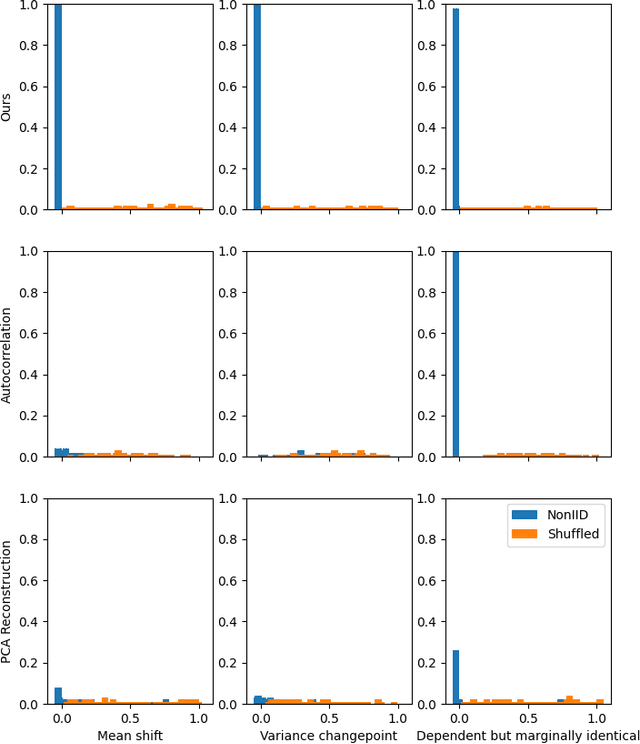
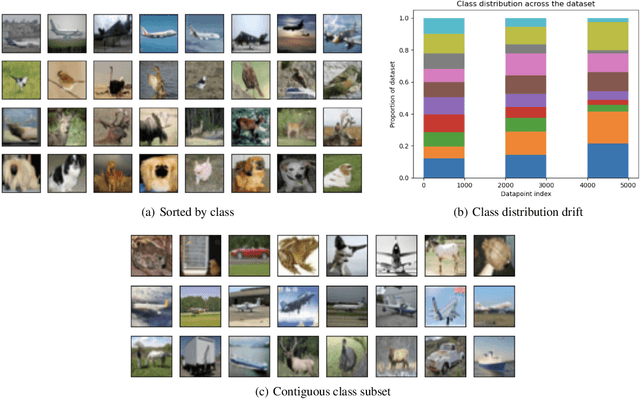
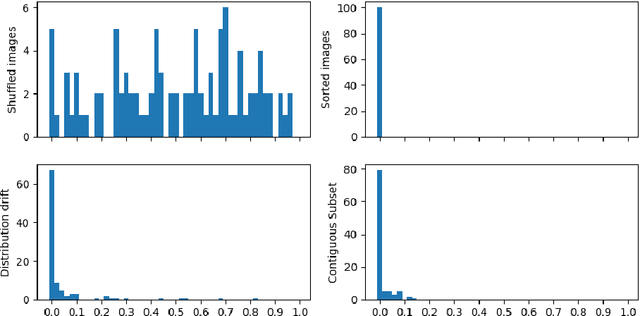
We present a straightforward statistical test to detect certain violations of the assumption that the data are Independent and Identically Distributed (IID). The specific form of violation considered is common across real-world applications: whether the examples are ordered in the dataset such that almost adjacent examples tend to have more similar feature values (e.g. due to distributional drift, or attractive interactions between datapoints). Based on a k-Nearest Neighbors estimate, our approach can be used to audit any multivariate numeric data as well as other data types (image, text, audio, etc.) that can be numerically represented, perhaps with model embeddings. Compared with existing methods to detect drift or auto-correlation, our approach is both applicable to more types of data and also able to detect a wider variety of IID violations in practice. Code: https://github.com/cleanlab/cleanlab
Identifying Incorrect Annotations in Multi-Label Classification Data
Nov 25, 2022In multi-label classification, each example in a dataset may be annotated as belonging to one or more classes (or none of the classes). Example applications include image (or document) tagging where each possible tag either applies to a particular image (or document) or not. With many possible classes to consider, data annotators are likely to make errors when labeling such data in practice. Here we consider algorithms for finding mislabeled examples in multi-label classification datasets. We propose an extension of the Confident Learning framework to this setting, as well as a label quality score that ranks examples with label errors much higher than those which are correctly labeled. Both approaches can utilize any trained classifier. After demonstrating that our methodology empirically outperforms other algorithms for label error detection, we apply our approach to discover many label errors in the CelebA image tagging dataset.