 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors
Paper and Code
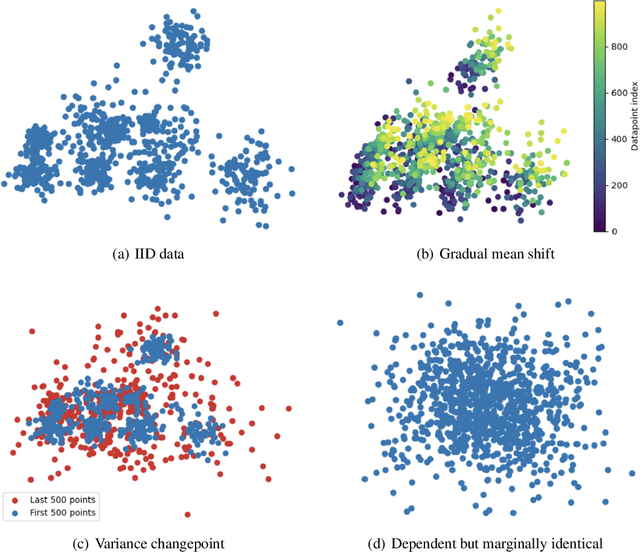
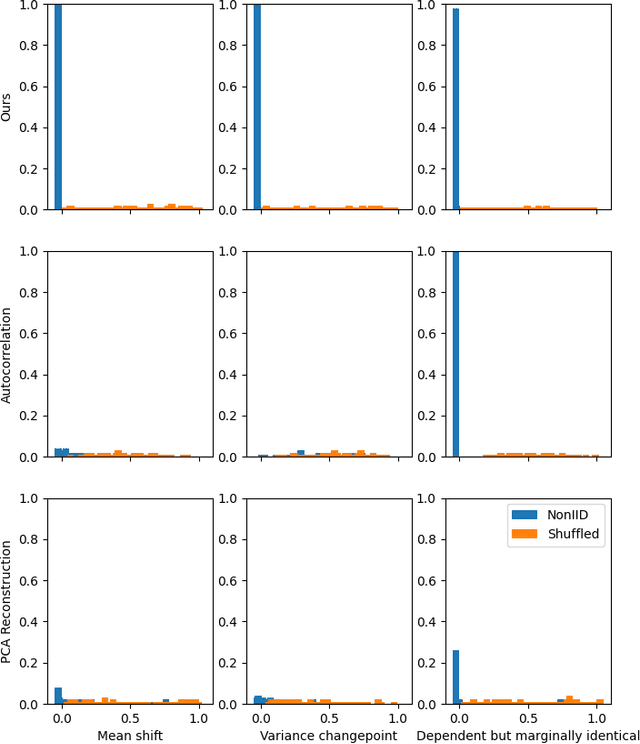
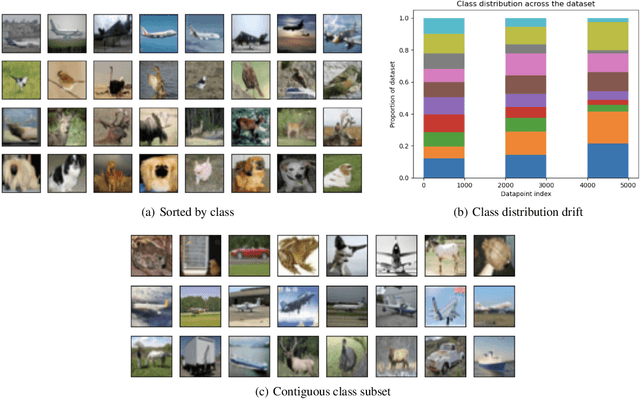
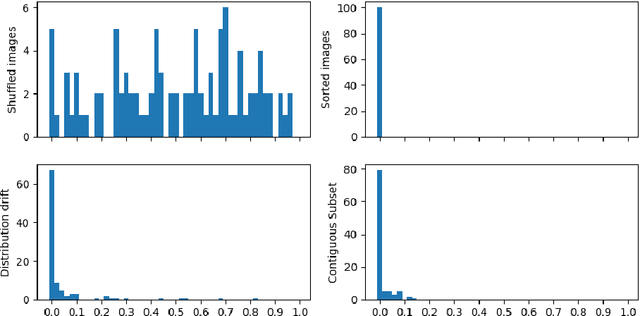
We present a straightforward statistical test to detect certain violations of the assumption that the data are Independent and Identically Distributed (IID). The specific form of violation considered is common across real-world applications: whether the examples are ordered in the dataset such that almost adjacent examples tend to have more similar feature values (e.g. due to distributional drift, or attractive interactions between datapoints). Based on a k-Nearest Neighbors estimate, our approach can be used to audit any multivariate numeric data as well as other data types (image, text, audio, etc.) that can be numerically represented, perhaps with model embeddings. Compared with existing methods to detect drift or auto-correlation, our approach is both applicable to more types of data and also able to detect a wider variety of IID violations in practice. Code: https://github.com/cleanlab/cleanlab