 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating label quality and errors in semantic segmentation data via any model
Paper and Code

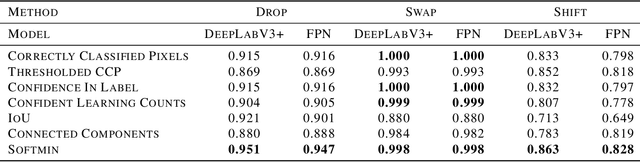

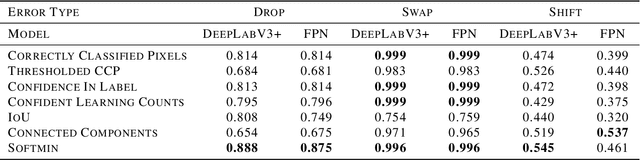
The labor-intensive annotation process of semantic segmentation datasets is often prone to errors, since humans struggle to label every pixel correctly. We study algorithms to automatically detect such annotation errors, in particular methods to score label quality, such that the images with the lowest scores are least likely to be correctly labeled. This helps prioritize what data to review in order to ensure a high-quality training/evaluation dataset, which is critical in sensitive applications such as medical imaging and autonomous vehicles. Widely applicable, our label quality scores rely on probabilistic predictions from a trained segmentation model -- any model architecture and training procedure can be utilized. Here we study 7 different label quality scoring methods used in conjunction with a DeepLabV3+ or a FPN segmentation model to detect annotation errors in a version of the SYNTHIA dataset. Precision-recall evaluations reveal a score -- the soft-minimum of the model-estimated likelihoods of each pixel's annotated class -- that is particularly effective to identify images that are mislabeled, across multiple types of annotation error.