 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Remarkable Robustness of LLMs: Stages of Inference?
Jun 27, 2024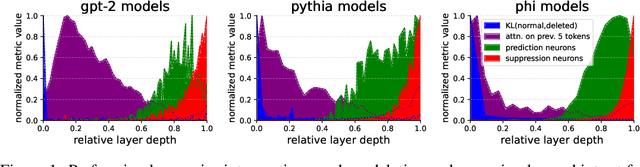
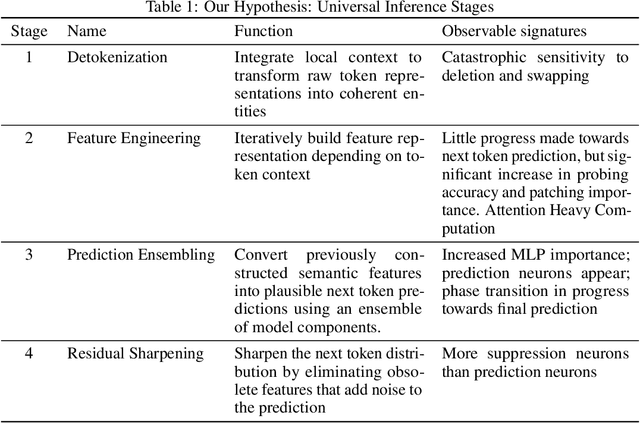
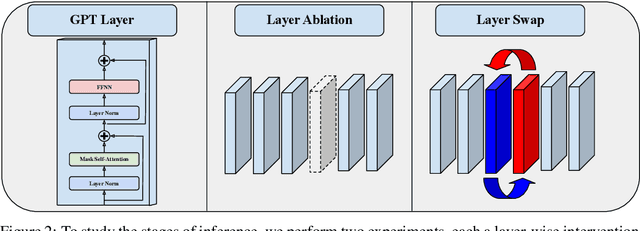

We demonstrate and investigate the remarkable robustness of Large Language Models by deleting and swapping adjacent layers. We find that deleting and swapping interventions retain 72-95\% of the original model's prediction accuracy without fine-tuning, whereas models with more layers exhibit more robustness. Based on the results of the layer-wise intervention and further experiments, we hypothesize the existence of four universal stages of inference across eight different models: detokenization, feature engineering, prediction ensembling, and residual sharpening. The first stage integrates local information, lifting raw token representations into higher-level contextual representations. Next is the iterative refinement of task and entity-specific features. Then, the second half of the model begins with a phase transition, where hidden representations align more with the vocabulary space due to specialized model components. Finally, the last layer sharpens the following token distribution by eliminating obsolete features that add noise to the prediction.
Opening the AI black box: program synthesis via mechanistic interpretability
Feb 07, 2024We present MIPS, a novel method for program synthesis based on automated mechanistic interpretability of neural networks trained to perform the desired task, auto-distilling the learned algorithm into Python code. We test MIPS on a benchmark of 62 algorithmic tasks that can be learned by an RNN and find it highly complementary to GPT-4: MIPS solves 32 of them, including 13 that are not solved by GPT-4 (which also solves 30). MIPS uses an integer autoencoder to convert the RNN into a finite state machine, then applies Boolean or integer symbolic regression to capture the learned algorithm. As opposed to large language models, this program synthesis technique makes no use of (and is therefore not limited by) human training data such as algorithms and code from GitHub. We discuss opportunities and challenges for scaling up this approach to make machine-learned models more interpretable and trustworthy.
Estimating label quality and errors in semantic segmentation data via any model
Jul 11, 2023
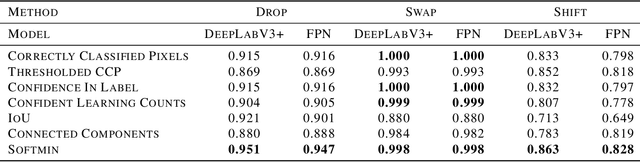

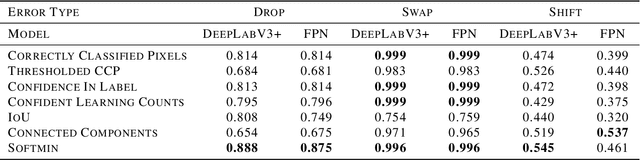
The labor-intensive annotation process of semantic segmentation datasets is often prone to errors, since humans struggle to label every pixel correctly. We study algorithms to automatically detect such annotation errors, in particular methods to score label quality, such that the images with the lowest scores are least likely to be correctly labeled. This helps prioritize what data to review in order to ensure a high-quality training/evaluation dataset, which is critical in sensitive applications such as medical imaging and autonomous vehicles. Widely applicable, our label quality scores rely on probabilistic predictions from a trained segmentation model -- any model architecture and training procedure can be utilized. Here we study 7 different label quality scoring methods used in conjunction with a DeepLabV3+ or a FPN segmentation model to detect annotation errors in a version of the SYNTHIA dataset. Precision-recall evaluations reveal a score -- the soft-minimum of the model-estimated likelihoods of each pixel's annotated class -- that is particularly effective to identify images that are mislabeled, across multiple types of annotation error.