 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSycophancy Towards Researchers Drives Performative Misalignment
Jun 07, 2026The increasing situational awareness of language models raises safety concerns: models might be aware when they are evaluated, and adjust their behavior to evade monitoring and resist modification, e.g., pretending to be aligned only in evaluation. This alignment faking behavior is often interpreted as scheming: an intentional effort of strategic deception. In this paper, we examine an alternative interpretation, performative misalignment, which explains the change in behavior as a result of sycophancy towards AI researchers. To examine this hypothesis, we present three empirical findings. First, we show that evaluation awareness persists even when we tell models they are deployed, which contradicts the scheming story which predicts less misalignment when the model perceives evaluation. Second, we use probing and steering to show that our current methods cannot mechanistically distinguish sycophancy and scheming in alignment faking evaluations. Third, we fine-tune models to be more sycophantic and observe increased sensitivity to evaluation cues. To conclude, we emphasize deconfounding sycophancy from scheming for future work on evaluations and mitigations of intent misalignment.
A Decision-Theoretic Formalisation of Steganography With Applications to LLM Monitoring
Feb 26, 2026Large language models are beginning to show steganographic capabilities. Such capabilities could allow misaligned models to evade oversight mechanisms. Yet principled methods to detect and quantify such behaviours are lacking. Classical definitions of steganography, and detection methods based on them, require a known reference distribution of non-steganographic signals. For the case of steganographic reasoning in LLMs, knowing such a reference distribution is not feasible; this renders these approaches inapplicable. We propose an alternative, \textbf{decision-theoretic view of steganography}. Our central insight is that steganography creates an asymmetry in usable information between agents who can and cannot decode the hidden content (present within a steganographic signal), and this otherwise latent asymmetry can be inferred from the agents' observable actions. To formalise this perspective, we introduce generalised $\mathcal{V}$-information: a utilitarian framework for measuring the amount of usable information within some input. We use this to define the \textbf{steganographic gap} -- a measure that quantifies steganography by comparing the downstream utility of the steganographic signal to agents that can and cannot decode the hidden content. We empirically validate our formalism, and show that it can be used to detect, quantify, and mitigate steganographic reasoning in LLMs.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Dense SAE Latents Are Features, Not Bugs
Jun 18, 2025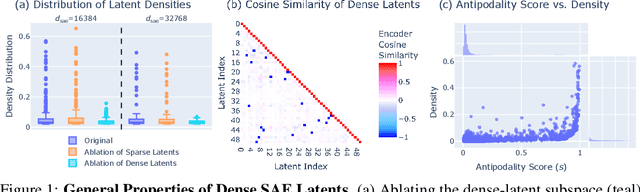
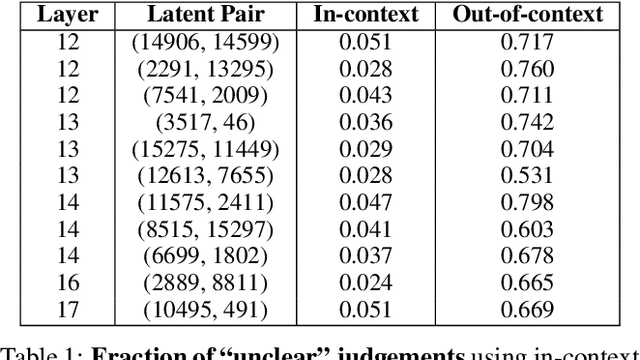
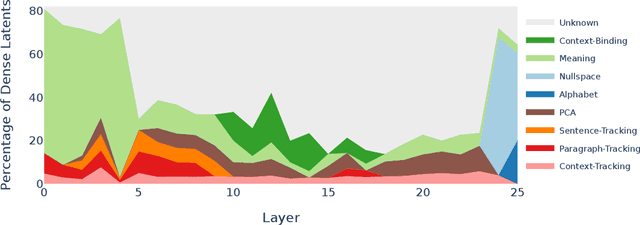
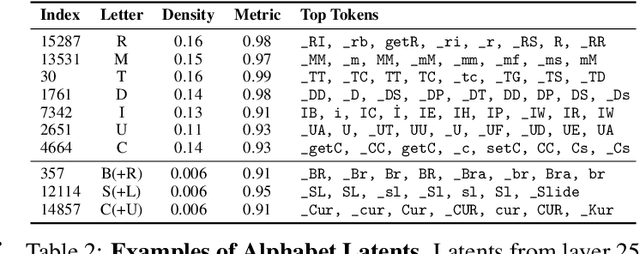
Sparse autoencoders (SAEs) are designed to extract interpretable features from language models by enforcing a sparsity constraint. Ideally, training an SAE would yield latents that are both sparse and semantically meaningful. However, many SAE latents activate frequently (i.e., are \emph{dense}), raising concerns that they may be undesirable artifacts of the training procedure. In this work, we systematically investigate the geometry, function, and origin of dense latents and show that they are not only persistent but often reflect meaningful model representations. We first demonstrate that dense latents tend to form antipodal pairs that reconstruct specific directions in the residual stream, and that ablating their subspace suppresses the emergence of new dense features in retrained SAEs -- suggesting that high density features are an intrinsic property of the residual space. We then introduce a taxonomy of dense latents, identifying classes tied to position tracking, context binding, entropy regulation, letter-specific output signals, part-of-speech, and principal component reconstruction. Finally, we analyze how these features evolve across layers, revealing a shift from structural features in early layers, to semantic features in mid layers, and finally to output-oriented signals in the last layers of the model. Our findings indicate that dense latents serve functional roles in language model computation and should not be dismissed as training noise.
On the creation of narrow AI: hierarchy and nonlocality of neural network skills
May 21, 2025We study the problem of creating strong, yet narrow, AI systems. While recent AI progress has been driven by the training of large general-purpose foundation models, the creation of smaller models specialized for narrow domains could be valuable for both efficiency and safety. In this work, we explore two challenges involved in creating such systems, having to do with basic properties of how neural networks learn and structure their representations. The first challenge regards when it is possible to train narrow models from scratch. Through experiments on a synthetic task, we find that it is sometimes necessary to train networks on a wide distribution of data to learn certain narrow skills within that distribution. This effect arises when skills depend on each other hierarchically, and training on a broad distribution introduces a curriculum which substantially accelerates learning. The second challenge regards how to transfer particular skills from large general models into small specialized models. We find that model skills are often not perfectly localized to a particular set of prunable components. However, we find that methods based on pruning can still outperform distillation. We investigate the use of a regularization objective to align desired skills with prunable components while unlearning unnecessary skills.
Neural Thermodynamic Laws for Large Language Model Training
May 15, 2025Beyond neural scaling laws, little is known about the laws underlying large language models (LLMs). We introduce Neural Thermodynamic Laws (NTL) -- a new framework that offers fresh insights into LLM training dynamics. On the theoretical side, we demonstrate that key thermodynamic quantities (e.g., temperature, entropy, heat capacity, thermal conduction) and classical thermodynamic principles (e.g., the three laws of thermodynamics and the equipartition theorem) naturally emerge under river-valley loss landscape assumptions. On the practical side, this scientific perspective yields intuitive guidelines for designing learning rate schedules.
Scaling Laws For Scalable Oversight
Apr 25, 2025Scalable oversight, the process by which weaker AI systems supervise stronger ones, has been proposed as a key strategy to control future superintelligent systems. However, it is still unclear how scalable oversight itself scales. To address this gap, we propose a framework that quantifies the probability of successful oversight as a function of the capabilities of the overseer and the system being overseen. Specifically, our framework models oversight as a game between capability-mismatched players; the players have oversight-specific and deception-specific Elo scores that are a piecewise-linear function of their general intelligence, with two plateaus corresponding to task incompetence and task saturation. We validate our framework with a modified version of the game Nim and then apply it to four oversight games: "Mafia", "Debate", "Backdoor Code" and "Wargames". For each game, we find scaling laws that approximate how domain performance depends on general AI system capability (using Chatbot Arena Elo as a proxy for general capability). We then build on our findings in a theoretical study of Nested Scalable Oversight (NSO), a process in which trusted models oversee untrusted stronger models, which then become the trusted models in the next step. We identify conditions under which NSO succeeds and derive numerically (and in some cases analytically) the optimal number of oversight levels to maximize the probability of oversight success. In our numerical examples, the NSO success rate is below 52% when overseeing systems that are 400 Elo points stronger than the baseline overseer, and it declines further for overseeing even stronger systems.
Do Two AI Scientists Agree?
Apr 03, 2025
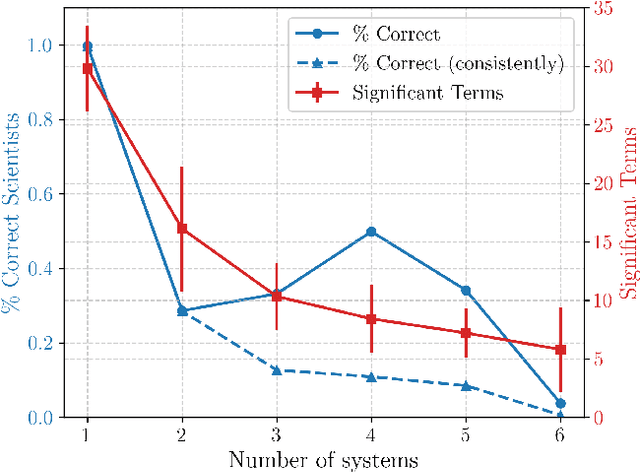
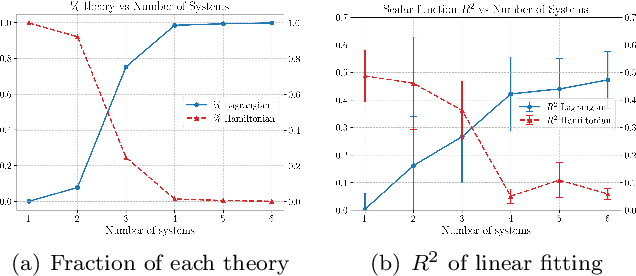

When two AI models are trained on the same scientific task, do they learn the same theory or two different theories? Throughout history of science, we have witnessed the rise and fall of theories driven by experimental validation or falsification: many theories may co-exist when experimental data is lacking, but the space of survived theories become more constrained with more experimental data becoming available. We show the same story is true for AI scientists. With increasingly more systems provided in training data, AI scientists tend to converge in the theories they learned, although sometimes they form distinct groups corresponding to different theories. To mechanistically interpret what theories AI scientists learn and quantify their agreement, we propose MASS, Hamiltonian-Lagrangian neural networks as AI Scientists, trained on standard problems in physics, aggregating training results across many seeds simulating the different configurations of AI scientists. Our findings suggests for AI scientists switch from learning a Hamiltonian theory in simple setups to a Lagrangian formulation when more complex systems are introduced. We also observe strong seed dependence of the training dynamics and final learned weights, controlling the rise and fall of relevant theories. We finally demonstrate that not only can our neural networks aid interpretability, it can also be applied to higher dimensional problems.
Towards Understanding Distilled Reasoning Models: A Representational Approach
Mar 05, 2025
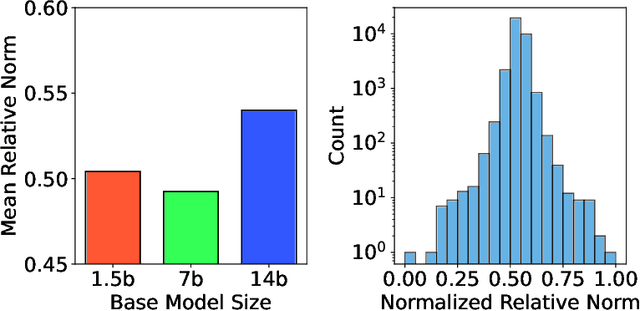
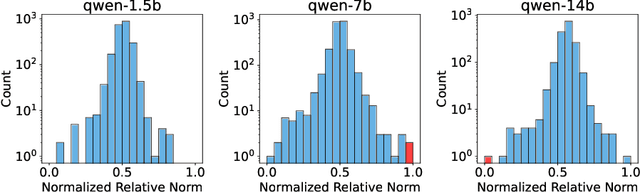
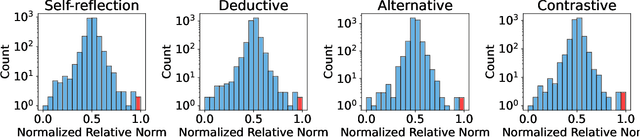
In this paper, we investigate how model distillation impacts the development of reasoning features in large language models (LLMs). To explore this, we train a crosscoder on Qwen-series models and their fine-tuned variants. Our results suggest that the crosscoder learns features corresponding to various types of reasoning, including self-reflection and computation verification. Moreover, we observe that distilled models contain unique reasoning feature directions, which could be used to steer the model into over-thinking or incisive-thinking mode. In particular, we perform analysis on four specific reasoning categories: (a) self-reflection, (b) deductive reasoning, (c) alternative reasoning, and (d) contrastive reasoning. Finally, we examine the changes in feature geometry resulting from the distillation process and find indications that larger distilled models may develop more structured representations, which correlate with enhanced distillation performance. By providing insights into how distillation modifies the model, our study contributes to enhancing the transparency and reliability of AI systems.
Are Sparse Autoencoders Useful? A Case Study in Sparse Probing
Feb 23, 2025

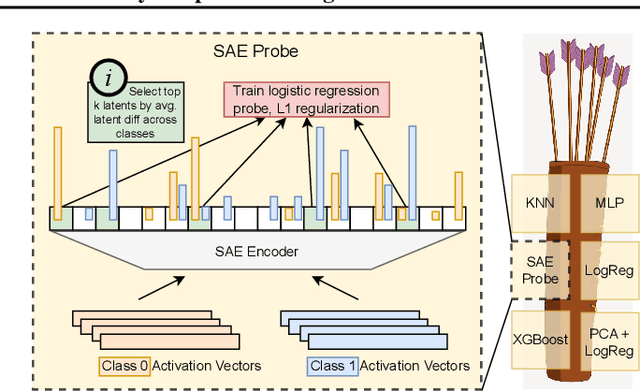

Sparse autoencoders (SAEs) are a popular method for interpreting concepts represented in large language model (LLM) activations. However, there is a lack of evidence regarding the validity of their interpretations due to the lack of a ground truth for the concepts used by an LLM, and a growing number of works have presented problems with current SAEs. One alternative source of evidence would be demonstrating that SAEs improve performance on downstream tasks beyond existing baselines. We test this by applying SAEs to the real-world task of LLM activation probing in four regimes: data scarcity, class imbalance, label noise, and covariate shift. Due to the difficulty of detecting concepts in these challenging settings, we hypothesize that SAEs' basis of interpretable, concept-level latents should provide a useful inductive bias. However, although SAEs occasionally perform better than baselines on individual datasets, we are unable to design ensemble methods combining SAEs with baselines that consistently outperform ensemble methods solely using baselines. Additionally, although SAEs initially appear promising for identifying spurious correlations, detecting poor dataset quality, and training multi-token probes, we are able to achieve similar results with simple non-SAE baselines as well. Though we cannot discount SAEs' utility on other tasks, our findings highlight the shortcomings of current SAEs and the need to rigorously evaluate interpretability methods on downstream tasks with strong baselines.