 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Embeddings with Sparse Autoencoders: A Data Analysis Toolkit
Dec 10, 2025Analyzing large-scale text corpora is a core challenge in machine learning, crucial for tasks like identifying undesirable model behaviors or biases in training data. Current methods often rely on costly LLM-based techniques (e.g. annotating dataset differences) or dense embedding models (e.g. for clustering), which lack control over the properties of interest. We propose using sparse autoencoders (SAEs) to create SAE embeddings: representations whose dimensions map to interpretable concepts. Through four data analysis tasks, we show that SAE embeddings are more cost-effective and reliable than LLMs and more controllable than dense embeddings. Using the large hypothesis space of SAEs, we can uncover insights such as (1) semantic differences between datasets and (2) unexpected concept correlations in documents. For instance, by comparing model responses, we find that Grok-4 clarifies ambiguities more often than nine other frontier models. Relative to LLMs, SAE embeddings uncover bigger differences at 2-8x lower cost and identify biases more reliably. Additionally, SAE embeddings are controllable: by filtering concepts, we can (3) cluster documents along axes of interest and (4) outperform dense embeddings on property-based retrieval. Using SAE embeddings, we study model behavior with two case studies: investigating how OpenAI model behavior has changed over time and finding "trigger" phrases learned by Tulu-3 (Lambert et al., 2024) from its training data. These results position SAEs as a versatile tool for unstructured data analysis and highlight the neglected importance of interpreting models through their data.
Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025



We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.
Dense SAE Latents Are Features, Not Bugs
Jun 18, 2025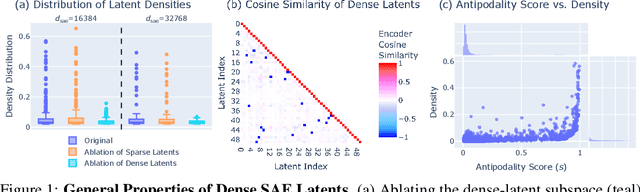
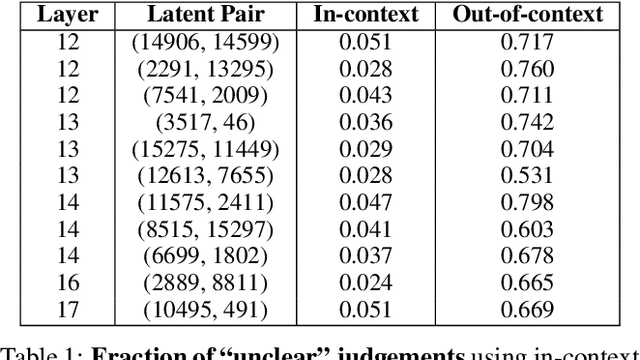
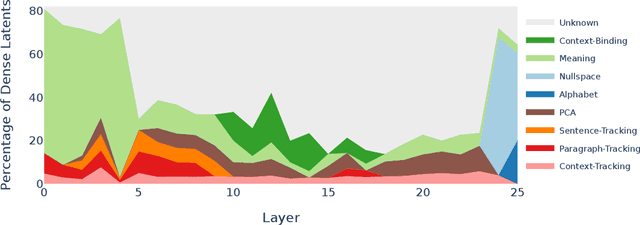
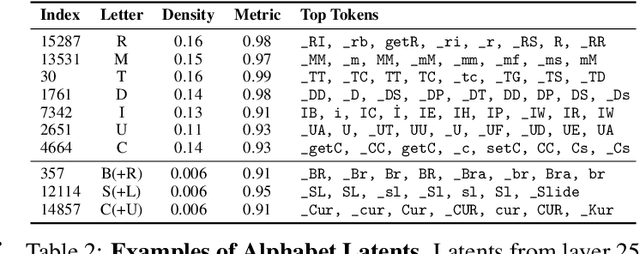
Sparse autoencoders (SAEs) are designed to extract interpretable features from language models by enforcing a sparsity constraint. Ideally, training an SAE would yield latents that are both sparse and semantically meaningful. However, many SAE latents activate frequently (i.e., are \emph{dense}), raising concerns that they may be undesirable artifacts of the training procedure. In this work, we systematically investigate the geometry, function, and origin of dense latents and show that they are not only persistent but often reflect meaningful model representations. We first demonstrate that dense latents tend to form antipodal pairs that reconstruct specific directions in the residual stream, and that ablating their subspace suppresses the emergence of new dense features in retrained SAEs -- suggesting that high density features are an intrinsic property of the residual space. We then introduce a taxonomy of dense latents, identifying classes tied to position tracking, context binding, entropy regulation, letter-specific output signals, part-of-speech, and principal component reconstruction. Finally, we analyze how these features evolve across layers, revealing a shift from structural features in early layers, to semantic features in mid layers, and finally to output-oriented signals in the last layers of the model. Our findings indicate that dense latents serve functional roles in language model computation and should not be dismissed as training noise.
Augmenting Interpretable Knowledge Tracing by Ability Attribute and Attention Mechanism
Feb 04, 2023



Knowledge tracing aims to model students' past answer sequences to track the change in their knowledge acquisition during exercise activities and to predict their future learning performance. Most existing approaches ignore the fact that students' abilities are constantly changing or vary between individuals, and lack the interpretability of model predictions. To this end, in this paper, we propose a novel model based on ability attributes and attention mechanism. We first segment the interaction sequences and captures students' ability attributes, then dynamically assign students to groups with similar abilities, and quantify the relevance of the exercises to the skill by calculating the attention weights between the exercises and the skill to enhance the interpretability of the model. We conducted extensive experiments and evaluate real online education datasets. The results confirm that the proposed model is better at predicting performance than five well-known representative knowledge tracing models, and the model prediction results are explained through an inference path.
HinDom: A Robust Malicious Domain Detection System based on Heterogeneous Information Network with Transductive Classification
Sep 04, 2019

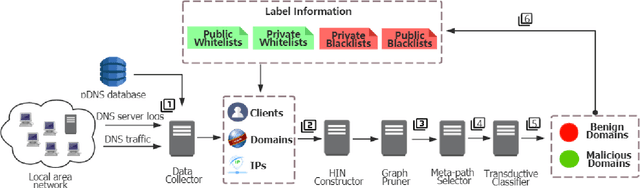

Domain name system (DNS) is a crucial part of the Internet, yet has been widely exploited by cyber attackers. Apart from making static methods like blacklists or sinkholes infeasible, some weasel attackers can even bypass detection systems with machine learning based classifiers. As a solution to this problem, we propose a robust domain detection system named HinDom. Instead of relying on manually selected features, HinDom models the DNS scene as a Heterogeneous Information Network (HIN) consist of clients, domains, IP addresses and their diverse relationships. Besides, the metapath-based transductive classification method enables HinDom to detect malicious domains with only a small fraction of labeled samples. So far as we know, this is the first work to apply HIN in DNS analysis. We build a prototype of HinDom and evaluate it in CERNET2 and TUNET. The results reveal that HinDom is accurate, robust and can identify previously unknown malicious domains.