 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense SAE Latents Are Features, Not Bugs
Jun 18, 2025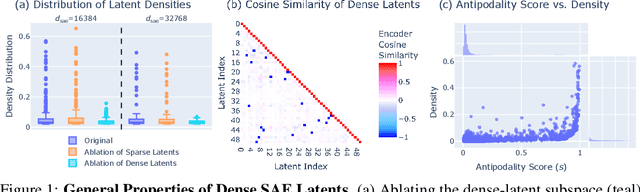
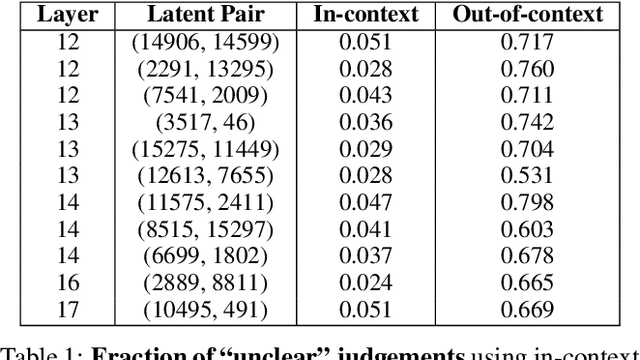
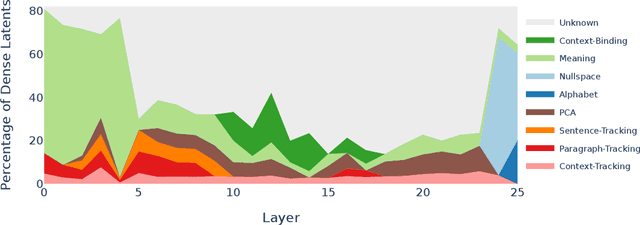
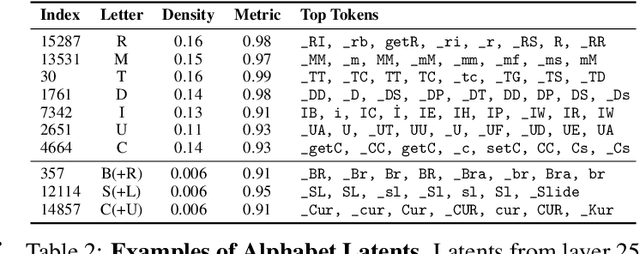
Sparse autoencoders (SAEs) are designed to extract interpretable features from language models by enforcing a sparsity constraint. Ideally, training an SAE would yield latents that are both sparse and semantically meaningful. However, many SAE latents activate frequently (i.e., are \emph{dense}), raising concerns that they may be undesirable artifacts of the training procedure. In this work, we systematically investigate the geometry, function, and origin of dense latents and show that they are not only persistent but often reflect meaningful model representations. We first demonstrate that dense latents tend to form antipodal pairs that reconstruct specific directions in the residual stream, and that ablating their subspace suppresses the emergence of new dense features in retrained SAEs -- suggesting that high density features are an intrinsic property of the residual space. We then introduce a taxonomy of dense latents, identifying classes tied to position tracking, context binding, entropy regulation, letter-specific output signals, part-of-speech, and principal component reconstruction. Finally, we analyze how these features evolve across layers, revealing a shift from structural features in early layers, to semantic features in mid layers, and finally to output-oriented signals in the last layers of the model. Our findings indicate that dense latents serve functional roles in language model computation and should not be dismissed as training noise.
GOD model: Privacy Preserved AI School for Personal Assistant
Feb 24, 2025



Personal AI assistants (e.g., Apple Intelligence, Meta AI) offer proactive recommendations that simplify everyday tasks, but their reliance on sensitive user data raises concerns about privacy and trust. To address these challenges, we introduce the Guardian of Data (GOD), a secure, privacy-preserving framework for training and evaluating AI assistants directly on-device. Unlike traditional benchmarks, the GOD model measures how well assistants can anticipate user needs-such as suggesting gifts-while protecting user data and autonomy. Functioning like an AI school, it addresses the cold start problem by simulating user queries and employing a curriculum-based approach to refine the performance of each assistant. Running within a Trusted Execution Environment (TEE), it safeguards user data while applying reinforcement and imitation learning to refine AI recommendations. A token-based incentive system encourages users to share data securely, creating a data flywheel that drives continuous improvement. By integrating privacy, personalization, and trust, the GOD model provides a scalable, responsible path for advancing personal AI assistants. For community collaboration, part of the framework is open-sourced at https://github.com/PIN-AI/God-Model.
Efficient Annotator Reliability Assessment and Sample Weighting for Knowledge-Based Misinformation Detection on Social Media
Oct 18, 2024



Misinformation spreads rapidly on social media, confusing the truth and targetting potentially vulnerable people. To effectively mitigate the negative impact of misinformation, it must first be accurately detected before applying a mitigation strategy, such as X's community notes, which is currently a manual process. This study takes a knowledge-based approach to misinformation detection, modelling the problem similarly to one of natural language inference. The EffiARA annotation framework is introduced, aiming to utilise inter- and intra-annotator agreement to understand the reliability of each annotator and influence the training of large language models for classification based on annotator reliability. In assessing the EffiARA annotation framework, the Russo-Ukrainian Conflict Knowledge-Based Misinformation Classification Dataset (RUC-MCD) was developed and made publicly available. This study finds that sample weighting using annotator reliability performs the best, utilising both inter- and intra-annotator agreement and soft-label training. The highest classification performance achieved using Llama-3.2-1B was a macro-F1 of 0.757 and 0.740 using TwHIN-BERT-large.
Confidence Regulation Neurons in Language Models
Jun 24, 2024Despite their widespread use, the mechanisms by which large language models (LLMs) represent and regulate uncertainty in next-token predictions remain largely unexplored. This study investigates two critical components believed to influence this uncertainty: the recently discovered entropy neurons and a new set of components that we term token frequency neurons. Entropy neurons are characterized by an unusually high weight norm and influence the final layer normalization (LayerNorm) scale to effectively scale down the logits. Our work shows that entropy neurons operate by writing onto an unembedding null space, allowing them to impact the residual stream norm with minimal direct effect on the logits themselves. We observe the presence of entropy neurons across a range of models, up to 7 billion parameters. On the other hand, token frequency neurons, which we discover and describe here for the first time, boost or suppress each token's logit proportionally to its log frequency, thereby shifting the output distribution towards or away from the unigram distribution. Finally, we present a detailed case study where entropy neurons actively manage confidence in the setting of induction, i.e. detecting and continuing repeated subsequences.
Don't Waste a Single Annotation: Improving Single-Label Classifiers Through Soft Labels
Nov 09, 2023



In this paper, we address the limitations of the common data annotation and training methods for objective single-label classification tasks. Typically, when annotating such tasks annotators are only asked to provide a single label for each sample and annotator disagreement is discarded when a final hard label is decided through majority voting. We challenge this traditional approach, acknowledging that determining the appropriate label can be difficult due to the ambiguity and lack of context in the data samples. Rather than discarding the information from such ambiguous annotations, our soft label method makes use of them for training. Our findings indicate that additional annotator information, such as confidence, secondary label and disagreement, can be used to effectively generate soft labels. Training classifiers with these soft labels then leads to improved performance and calibration on the hard label test set.
Comparison between parameter-efficient techniques and full fine-tuning: A case study on multilingual news article classification
Aug 14, 2023Adapters and Low-Rank Adaptation (LoRA) are parameter-efficient fine-tuning techniques designed to make the training of language models more efficient. Previous results demonstrated that these methods can even improve performance on some classification tasks. This paper complements the existing research by investigating how these techniques influence the classification performance and computation costs compared to full fine-tuning when applied to multilingual text classification tasks (genre, framing, and persuasion techniques detection; with different input lengths, number of predicted classes and classification difficulty), some of which have limited training data. In addition, we conduct in-depth analyses of their efficacy across different training scenarios (training on the original multilingual data; on the translations into English; and on a subset of English-only data) and different languages. Our findings provide valuable insights into the applicability of the parameter-efficient fine-tuning techniques, particularly to complex multilingual and multilabel classification tasks.
Team SheffieldVeraAI at SemEval-2023 Task 3: Mono and multilingual approaches for news genre, topic and persuasion technique classification
Mar 16, 2023



This paper describes our approach for SemEval-2023 Task 3: Detecting the category, the framing, and the persuasion techniques in online news in a multi-lingual setup. For Subtask 1 (News Genre), we propose an ensemble of fully trained and adapter mBERT models which was ranked joint-first for German, and had the highest mean rank of multi-language teams. For Subtask 2 (Framing), we achieved first place in 3 languages, and the best average rank across all the languages, by using two separate ensembles: a monolingual RoBERTa-MUPPETLARGE and an ensemble of XLM-RoBERTaLARGE with adapters and task adaptive pretraining. For Subtask 3 (Persuasion Techniques), we train a monolingual RoBERTa-Base model for English and a multilingual mBERT model for the remaining languages, which achieved top 10 for all languages, including 2nd for English. For each subtask, we compare monolingual and multilingual approaches, and consider class imbalance techniques.
Sub-Nyquist Sampling with Optical Pulses for Photonic Blind Source Separation
Jul 25, 2021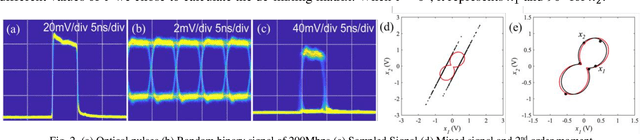
We proposed and demonstrated an optical pulse sampling method for photonic blind source separation. It can separate large bandwidth of mixed signals by small sampling frequency, which can reduce the workload of digital signal processing.
Photonic Interference Cancellation with Hybrid Free Space Optical Communication and MIMO Receiver
Jul 25, 2021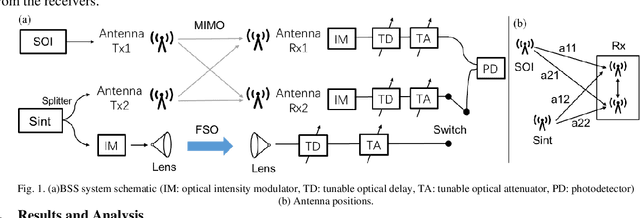
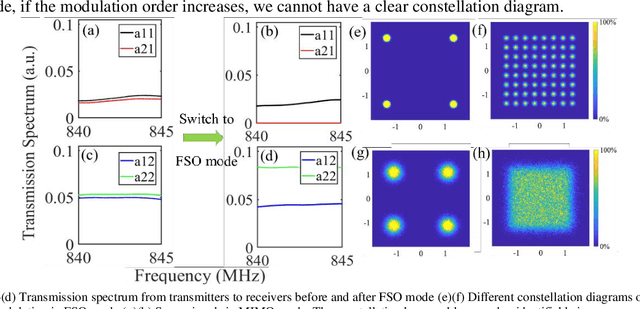
We proposed and demonstrated a hybrid blind source separation system which can switch between multiple-input and multi-output mode and free space optical communication mode depends on different situation to get best condition for separation.
Radio Frequency Interference Management with Free-Space Optical Communication and Photonic Signal Processing
Jul 25, 2021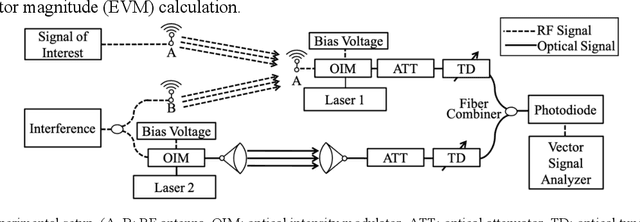
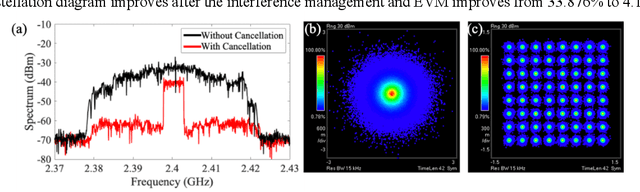
We design and experimentally demonstrate a radio frequency interference management system with free-space optical communication and photonic signal processing. The system provides real-time interference cancellation in 6 GHz wide bandwidth.