 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexTrace: A Facial Expressive Behaviour Analysis Tool for Continuous Affect Recognition
May 08, 2025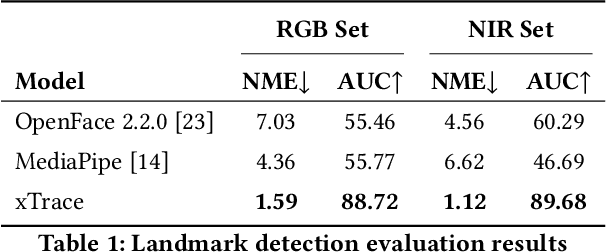
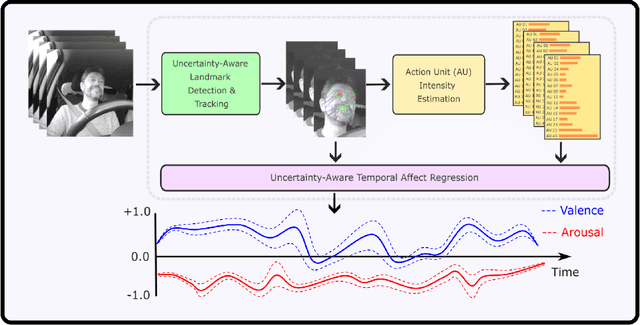

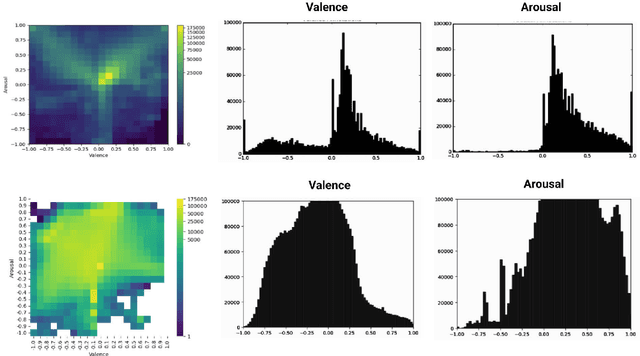
Recognising expressive behaviours in face videos is a long-standing challenge in Affective Computing. Despite significant advancements in recent years, it still remains a challenge to build a robust and reliable system for naturalistic and in-the-wild facial expressive behaviour analysis in real time. This paper addresses two key challenges in building such a system: (1). The paucity of large-scale labelled facial affect video datasets with extensive coverage of the 2D emotion space, and (2). The difficulty of extracting facial video features that are discriminative, interpretable, robust, and computationally efficient. Toward addressing these challenges, we introduce xTrace, a robust tool for facial expressive behaviour analysis and predicting continuous values of dimensional emotions, namely valence and arousal, from in-the-wild face videos. To address challenge (1), our affect recognition model is trained on the largest facial affect video data set, containing ~450k videos that cover most emotion zones in the dimensional emotion space, making xTrace highly versatile in analysing a wide spectrum of naturalistic expressive behaviours. To address challenge (2), xTrace uses facial affect descriptors that are not only explainable, but can also achieve a high degree of accuracy and robustness with low computational complexity. The key components of xTrace are benchmarked against three existing tools: MediaPipe, OpenFace, and Augsburg Affect Toolbox. On an in-the-wild validation set composed of 50k videos, xTrace achieves 0.86 mean CCC and 0.13 mean absolute error values. We present a detailed error analysis of affect predictions from xTrace, illustrating (a). its ability to recognise emotions with high accuracy across most bins in the 2D emotion space, (b). its robustness to non-frontal head pose angles, and (c). a strong correlation between its uncertainty estimates and its accuracy.
Efficient Annotator Reliability Assessment and Sample Weighting for Knowledge-Based Misinformation Detection on Social Media
Oct 18, 2024



Misinformation spreads rapidly on social media, confusing the truth and targetting potentially vulnerable people. To effectively mitigate the negative impact of misinformation, it must first be accurately detected before applying a mitigation strategy, such as X's community notes, which is currently a manual process. This study takes a knowledge-based approach to misinformation detection, modelling the problem similarly to one of natural language inference. The EffiARA annotation framework is introduced, aiming to utilise inter- and intra-annotator agreement to understand the reliability of each annotator and influence the training of large language models for classification based on annotator reliability. In assessing the EffiARA annotation framework, the Russo-Ukrainian Conflict Knowledge-Based Misinformation Classification Dataset (RUC-MCD) was developed and made publicly available. This study finds that sample weighting using annotator reliability performs the best, utilising both inter- and intra-annotator agreement and soft-label training. The highest classification performance achieved using Llama-3.2-1B was a macro-F1 of 0.757 and 0.740 using TwHIN-BERT-large.