 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRM: Learning the Language of Rotating Machinery for Self-Supervised Condition Monitoring
Apr 07, 2026We present LoRM (Language of Rotating Machinery), a self-supervised framework for multi-modal rotating-machinery signal understanding and real-time condition monitoring. LoRM is built on the idea that rotating-machinery signals can be viewed as a machine language: local signals can be tokenised into discrete symbolic units, and their future evolution can be predicted from observed multi-sensor context. Unlike conventional signal-processing methods that rely on hand-crafted transforms and features, LoRM reformulates multi-modal sensor data as a token-based sequence-prediction problem. For each data window, the observed context segment is retained in continuous form, while the future target segment of each sensing channel is quantised into a discrete token. Then, efficient knowledge transfer is achieved by partially fine-tuning a general-purpose pre-trained language model on industrial signals, avoiding the need to train a large model from scratch. Finally, condition monitoring is performed by tracking token-prediction errors as a health indicator, where increasing errors indicate degradation. In-situ tool condition monitoring (TCM) experiments demonstrate stable real-time tracking and strong cross-tool generalisation, showing that LoRM provides a practical bridge between language modelling and industrial signal analysis. The source code is publicly available at https://github.com/Q159753258/LormPHM.
ESG-Bench: Benchmarking Long-Context ESG Reports for Hallucination Mitigation
Mar 13, 2026As corporate responsibility increasingly incorporates environmental, social, and governance (ESG) criteria, ESG reporting is becoming a legal requirement in many regions and a key channel for documenting sustainability practices and assessing firms' long-term and ethical performance. However, the length and complexity of ESG disclosures make them difficult to interpret and automate the analysis reliably. To support scalable and trustworthy analysis, this paper introduces ESG-Bench, a benchmark dataset for ESG report understanding and hallucination mitigation in large language models (LLMs). ESG-Bench contains human-annotated question-answer (QA) pairs grounded in real-world ESG report contexts, with fine-grained labels indicating whether model outputs are factually supported or hallucinated. Framing ESG report analysis as a QA task with verifiability constraints enables systematic evaluation of LLMs' ability to extract and reason over ESG content and provides a new use case: mitigating hallucinations in socially sensitive, compliance-critical settings. We design task-specific Chain-of-Thought (CoT) prompting strategies and fine-tune multiple state-of-the-art LLMs on ESG-Bench using CoT-annotated rationales. Our experiments show that these CoT-based methods substantially outperform standard prompting and direct fine-tuning in reducing hallucinations, and that the gains transfer to existing QA benchmarks beyond the ESG domain.
Efficient Annotator Reliablity Assessment with EffiARA
Apr 01, 2025


Data annotation is an essential component of the machine learning pipeline; it is also a costly and time-consuming process. With the introduction of transformer-based models, annotation at the document level is increasingly popular; however, there is no standard framework for structuring such tasks. The EffiARA annotation framework is, to our knowledge, the first project to support the whole annotation pipeline, from understanding the resources required for an annotation task to compiling the annotated dataset and gaining insights into the reliability of individual annotators as well as the dataset as a whole. The framework's efficacy is supported by two previous studies: one improving classification performance through annotator-reliability-based soft label aggregation and sample weighting, and the other increasing the overall agreement among annotators through removing identifying and replacing an unreliable annotator. This work introduces the EffiARA Python package and its accompanying webtool, which provides an accessible graphical user interface for the system. We open-source the EffiARA Python package at https://github.com/MiniEggz/EffiARA and the webtool is publicly accessible at https://effiara.gate.ac.uk.
A Dataset for Analysing News Framing in Chinese Media
Mar 06, 2025



Framing is an essential device in news reporting, allowing the writer to influence public perceptions of current affairs. While there are existing automatic news framing detection datasets in various languages, none of them focus on news framing in the Chinese language which has complex character meanings and unique linguistic features. This study introduces the first Chinese News Framing dataset, to be used as either a stand-alone dataset or a supplementary resource to the SemEval-2023 task 3 dataset. We detail its creation and we run baseline experiments to highlight the need for such a dataset and create benchmarks for future research, providing results obtained through fine-tuning XLM-RoBERTa-Base and using GPT-4o in the zero-shot setting. We find that GPT-4o performs significantly worse than fine-tuned XLM-RoBERTa across all languages. For the Chinese language, we obtain an F1-micro (the performance metric for SemEval task 3, subtask 2) score of 0.719 using only samples from our Chinese News Framing dataset and a score of 0.753 when we augment the SemEval dataset with Chinese news framing samples. With positive news frame detection results, this dataset is a valuable resource for detecting news frames in the Chinese language and is a valuable supplement to the SemEval-2023 task 3 dataset.
Efficient Annotator Reliability Assessment and Sample Weighting for Knowledge-Based Misinformation Detection on Social Media
Oct 18, 2024



Misinformation spreads rapidly on social media, confusing the truth and targetting potentially vulnerable people. To effectively mitigate the negative impact of misinformation, it must first be accurately detected before applying a mitigation strategy, such as X's community notes, which is currently a manual process. This study takes a knowledge-based approach to misinformation detection, modelling the problem similarly to one of natural language inference. The EffiARA annotation framework is introduced, aiming to utilise inter- and intra-annotator agreement to understand the reliability of each annotator and influence the training of large language models for classification based on annotator reliability. In assessing the EffiARA annotation framework, the Russo-Ukrainian Conflict Knowledge-Based Misinformation Classification Dataset (RUC-MCD) was developed and made publicly available. This study finds that sample weighting using annotator reliability performs the best, utilising both inter- and intra-annotator agreement and soft-label training. The highest classification performance achieved using Llama-3.2-1B was a macro-F1 of 0.757 and 0.740 using TwHIN-BERT-large.
Enhancing Data Quality through Simple De-duplication: Navigating Responsible Computational Social Science Research
Oct 04, 2024

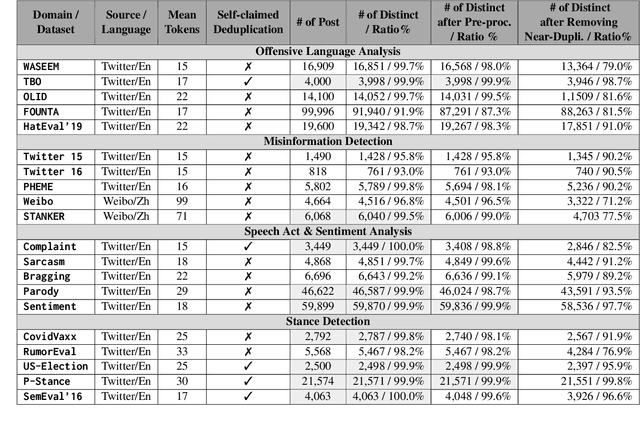

Research in natural language processing (NLP) for Computational Social Science (CSS) heavily relies on data from social media platforms. This data plays a crucial role in the development of models for analysing socio-linguistic phenomena within online communities. In this work, we conduct an in-depth examination of 20 datasets extensively used in NLP for CSS to comprehensively examine data quality. Our analysis reveals that social media datasets exhibit varying levels of data duplication. Consequently, this gives rise to challenges like label inconsistencies and data leakage, compromising the reliability of models. Our findings also suggest that data duplication has an impact on the current claims of state-of-the-art performance, potentially leading to an overestimation of model effectiveness in real-world scenarios. Finally, we propose new protocols and best practices for improving dataset development from social media data and its usage.
Cross-Modal Augmentation for Few-Shot Multimodal Fake News Detection
Jul 16, 2024



The nascent topic of fake news requires automatic detection methods to quickly learn from limited annotated samples. Therefore, the capacity to rapidly acquire proficiency in a new task with limited guidance, also known as few-shot learning, is critical for detecting fake news in its early stages. Existing approaches either involve fine-tuning pre-trained language models which come with a large number of parameters, or training a complex neural network from scratch with large-scale annotated datasets. This paper presents a multimodal fake news detection model which augments multimodal features using unimodal features. For this purpose, we introduce Cross-Modal Augmentation (CMA), a simple approach for enhancing few-shot multimodal fake news detection by transforming n-shot classification into a more robust (n $\times$ z)-shot problem, where z represents the number of supplementary features. The proposed CMA achieves SOTA results over three benchmark datasets, utilizing a surprisingly simple linear probing method to classify multimodal fake news with only a few training samples. Furthermore, our method is significantly more lightweight than prior approaches, particularly in terms of the number of trainable parameters and epoch times. The code is available here: \url{https://github.com/zgjiangtoby/FND_fewshot}
Confidence Regulation Neurons in Language Models
Jun 24, 2024Despite their widespread use, the mechanisms by which large language models (LLMs) represent and regulate uncertainty in next-token predictions remain largely unexplored. This study investigates two critical components believed to influence this uncertainty: the recently discovered entropy neurons and a new set of components that we term token frequency neurons. Entropy neurons are characterized by an unusually high weight norm and influence the final layer normalization (LayerNorm) scale to effectively scale down the logits. Our work shows that entropy neurons operate by writing onto an unembedding null space, allowing them to impact the residual stream norm with minimal direct effect on the logits themselves. We observe the presence of entropy neurons across a range of models, up to 7 billion parameters. On the other hand, token frequency neurons, which we discover and describe here for the first time, boost or suppress each token's logit proportionally to its log frequency, thereby shifting the output distribution towards or away from the unigram distribution. Finally, we present a detailed case study where entropy neurons actively manage confidence in the setting of induction, i.e. detecting and continuing repeated subsequences.
Identifying and Aligning Medical Claims Made on Social Media with Medical Evidence
May 18, 2024



Evidence-based medicine is the practice of making medical decisions that adhere to the latest, and best known evidence at that time. Currently, the best evidence is often found in the form of documents, such as randomized control trials, meta-analyses and systematic reviews. This research focuses on aligning medical claims made on social media platforms with this medical evidence. By doing so, individuals without medical expertise can more effectively assess the veracity of such medical claims. We study three core tasks: identifying medical claims, extracting medical vocabulary from these claims, and retrieving evidence relevant to those identified medical claims. We propose a novel system that can generate synthetic medical claims to aid each of these core tasks. We additionally introduce a novel dataset produced by our synthetic generator that, when applied to these tasks, demonstrates not only a more flexible and holistic approach, but also an improvement in all comparable metrics. We make our dataset, the Expansive Medical Claim Corpus (EMCC), available at https://zenodo.org/records/8321460
Addressing Topic Granularity and Hallucination in Large Language Models for Topic Modelling
May 01, 2024



Large language models (LLMs) with their strong zero-shot topic extraction capabilities offer an alternative to probabilistic topic modelling and closed-set topic classification approaches. As zero-shot topic extractors, LLMs are expected to understand human instructions to generate relevant and non-hallucinated topics based on the given documents. However, LLM-based topic modelling approaches often face difficulties in generating topics with adherence to granularity as specified in human instructions, often resulting in many near-duplicate topics. Furthermore, methods for addressing hallucinated topics generated by LLMs have not yet been investigated. In this paper, we focus on addressing the issues of topic granularity and hallucinations for better LLM-based topic modelling. To this end, we introduce a novel approach that leverages Direct Preference Optimisation (DPO) to fine-tune open-source LLMs, such as Mistral-7B. Our approach does not rely on traditional human annotation to rank preferred answers but employs a reconstruction pipeline to modify raw topics generated by LLMs, thus enabling a fast and efficient training and inference framework. Comparative experiments show that our fine-tuning approach not only significantly improves the LLM's capability to produce more coherent, relevant, and precise topics, but also reduces the number of hallucinated topics.