 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLM-Based Grant Proposal Review via Structured Perturbations
Mar 11, 2026As AI-assisted grant proposals outpace manual review capacity in a kind of ``Malthusian trap'' for the research ecosystem, this paper investigates the capabilities and limitations of LLM-based grant reviewing for high-stakes evaluation. Using six EPSRC proposals, we develop a perturbation-based framework probing LLM sensitivity across six quality axes: funding, timeline, competency, alignment, clarity, and impact. We compare three review architectures: single-pass review, section-by-section analysis, and a 'Council of Personas' ensemble emulating expert panels. The section-level approach significantly outperforms alternatives in both detection rate and scoring reliability, while the computationally expensive council method performs no better than baseline. Detection varies substantially by perturbation type, with alignment issues readily identified but clarity flaws largely missed by all systems. Human evaluation shows LLM feedback is largely valid but skewed toward compliance checking over holistic assessment. We conclude that current LLMs may provide supplementary value within EPSRC review but exhibit high variability and misaligned review priorities. We release our code and any non-protected data.
Exploring the Influence of Label Aggregation on Minority Voices: Implications for Dataset Bias and Model Training
Dec 05, 2024



Resolving disagreement in manual annotation typically consists of removing unreliable annotators and using a label aggregation strategy such as majority vote or expert opinion to resolve disagreement. These may have the side-effect of silencing or under-representing minority but equally valid opinions. In this paper, we study the impact of standard label aggregation strategies on minority opinion representation in sexism detection. We investigate the quality and value of minority annotations, and then examine their effect on the class distributions in gold labels, as well as how this affects the behaviour of models trained on the resulting datasets. Finally, we discuss the potential biases introduced by each method and how they can be amplified by the models.
Hostility Detection in UK Politics: A Dataset on Online Abuse Targeting MPs
Dec 05, 2024
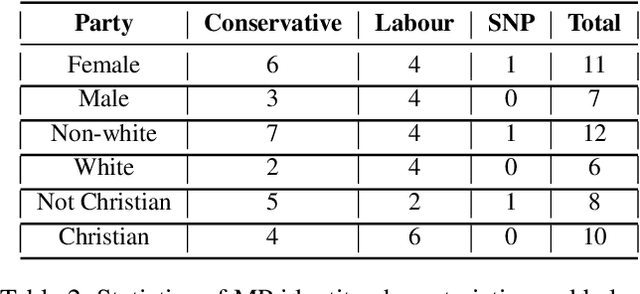
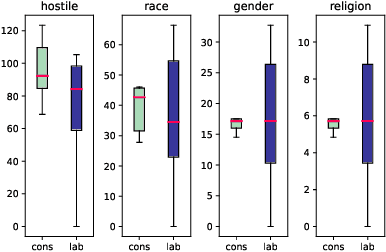
Numerous politicians use social media platforms, particularly X, to engage with their constituents. This interaction allows constituents to pose questions and offer feedback but also exposes politicians to a barrage of hostile responses, especially given the anonymity afforded by social media. They are typically targeted in relation to their governmental role, but the comments also tend to attack their personal identity. This can discredit politicians and reduce public trust in the government. It can also incite anger and disrespect, leading to offline harm and violence. While numerous models exist for detecting hostility in general, they lack the specificity required for political contexts. Furthermore, addressing hostility towards politicians demands tailored approaches due to the distinct language and issues inherent to each country (e.g., Brexit for the UK). To bridge this gap, we construct a dataset of 3,320 English tweets spanning a two-year period manually annotated for hostility towards UK MPs. Our dataset also captures the targeted identity characteristics (race, gender, religion, none) in hostile tweets. We perform linguistic and topical analyses to delve into the unique content of the UK political data. Finally, we evaluate the performance of pre-trained language models and large language models on binary hostility detection and multi-class targeted identity type classification tasks. Our study offers valuable data and insights for future research on the prevalence and nature of politics-related hostility specific to the UK.
Increasing the Difficulty of Automatically Generated Questions via Reinforcement Learning with Synthetic Preference
Oct 10, 2024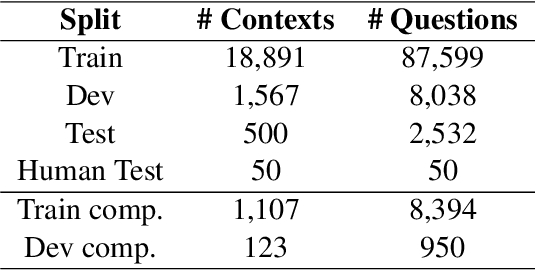

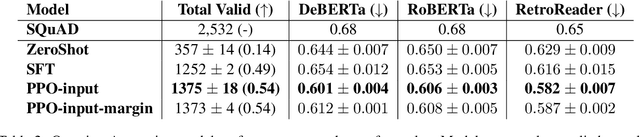

As the cultural heritage sector increasingly adopts technologies like Retrieval-Augmented Generation (RAG) to provide more personalised search experiences and enable conversations with collections data, the demand for specialised evaluation datasets has grown. While end-to-end system testing is essential, it's equally important to assess individual components. We target the final, answering task, which is well-suited to Machine Reading Comprehension (MRC). Although existing MRC datasets address general domains, they lack the specificity needed for cultural heritage information. Unfortunately, the manual creation of such datasets is prohibitively expensive for most heritage institutions. This paper presents a cost-effective approach for generating domain-specific MRC datasets with increased difficulty using Reinforcement Learning from Human Feedback (RLHF) from synthetic preference data. Our method leverages the performance of existing question-answering models on a subset of SQuAD to create a difficulty metric, assuming that more challenging questions are answered correctly less frequently. This research contributes: (1) A methodology for increasing question difficulty using PPO and synthetic data; (2) Empirical evidence of the method's effectiveness, including human evaluation; (3) An in-depth error analysis and study of emergent phenomena; and (4) An open-source codebase and set of three llama-2-chat adapters for reproducibility and adaptation.
Cross-Modal Augmentation for Few-Shot Multimodal Fake News Detection
Jul 16, 2024



The nascent topic of fake news requires automatic detection methods to quickly learn from limited annotated samples. Therefore, the capacity to rapidly acquire proficiency in a new task with limited guidance, also known as few-shot learning, is critical for detecting fake news in its early stages. Existing approaches either involve fine-tuning pre-trained language models which come with a large number of parameters, or training a complex neural network from scratch with large-scale annotated datasets. This paper presents a multimodal fake news detection model which augments multimodal features using unimodal features. For this purpose, we introduce Cross-Modal Augmentation (CMA), a simple approach for enhancing few-shot multimodal fake news detection by transforming n-shot classification into a more robust (n $\times$ z)-shot problem, where z represents the number of supplementary features. The proposed CMA achieves SOTA results over three benchmark datasets, utilizing a surprisingly simple linear probing method to classify multimodal fake news with only a few training samples. Furthermore, our method is significantly more lightweight than prior approaches, particularly in terms of the number of trainable parameters and epoch times. The code is available here: \url{https://github.com/zgjiangtoby/FND_fewshot}
Dimensions of Online Conflict: Towards Modeling Agonism
Nov 06, 2023



Agonism plays a vital role in democratic dialogue by fostering diverse perspectives and robust discussions. Within the realm of online conflict there is another type: hateful antagonism, which undermines constructive dialogue. Detecting conflict online is central to platform moderation and monetization. It is also vital for democratic dialogue, but only when it takes the form of agonism. To model these two types of conflict, we collected Twitter conversations related to trending controversial topics. We introduce a comprehensive annotation schema for labelling different dimensions of conflict in the conversations, such as the source of conflict, the target, and the rhetorical strategies deployed. Using this schema, we annotated approximately 4,000 conversations with multiple labels. We then trained both logistic regression and transformer-based models on the dataset, incorporating context from the conversation, including the number of participants and the structure of the interactions. Results show that contextual labels are helpful in identifying conflict and make the models robust to variations in topic. Our research contributes a conceptualization of different dimensions of conflict, a richly annotated dataset, and promising results that can contribute to content moderation.
* To appear
Examining Temporal Bias in Abusive Language Detection
Sep 25, 2023
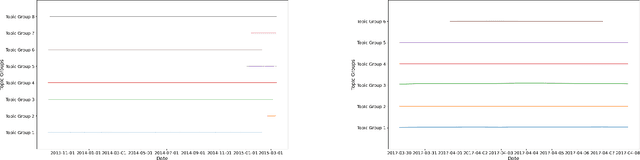
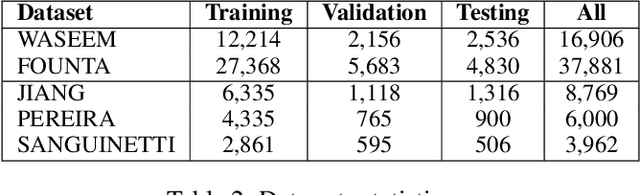
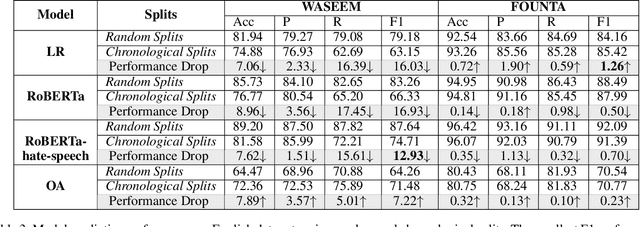
The use of abusive language online has become an increasingly pervasive problem that damages both individuals and society, with effects ranging from psychological harm right through to escalation to real-life violence and even death. Machine learning models have been developed to automatically detect abusive language, but these models can suffer from temporal bias, the phenomenon in which topics, language use or social norms change over time. This study aims to investigate the nature and impact of temporal bias in abusive language detection across various languages and explore mitigation methods. We evaluate the performance of models on abusive data sets from different time periods. Our results demonstrate that temporal bias is a significant challenge for abusive language detection, with models trained on historical data showing a significant drop in performance over time. We also present an extensive linguistic analysis of these abusive data sets from a diachronic perspective, aiming to explore the reasons for language evolution and performance decline. This study sheds light on the pervasive issue of temporal bias in abusive language detection across languages, offering crucial insights into language evolution and temporal bias mitigation.
Similarity-Aware Multimodal Prompt Learning for Fake News Detection
Apr 20, 2023



The standard paradigm for fake news detection mainly utilizes text information to model the truthfulness of news. However, the discourse of online fake news is typically subtle and it requires expert knowledge to use textual information to debunk fake news. Recently, studies focusing on multimodal fake news detection have outperformed text-only methods. Recent approaches utilizing the pre-trained model to extract unimodal features, or fine-tuning the pre-trained model directly, have become a new paradigm for detecting fake news. Again, this paradigm either requires a large number of training instances, or updates the entire set of pre-trained model parameters, making real-world fake news detection impractical. Furthermore, traditional multimodal methods fuse the cross-modal features directly without considering that the uncorrelated semantic representation might inject noise into the multimodal features. This paper proposes a Similarity-Aware Multimodal Prompt Learning (SAMPLE) framework. First, we incorporate prompt learning into multimodal fake news detection. Prompt learning, which only tunes prompts with a frozen language model, can reduce memory usage significantly and achieve comparable performances, compared with fine-tuning. We analyse three prompt templates with a soft verbalizer to detect fake news. In addition, we introduce the similarity-aware fusing method to adaptively fuse the intensity of multimodal representation and mitigate the noise injection via uncorrelated cross-modal features. For evaluation, SAMPLE surpasses the F1 and the accuracies of previous works on two benchmark multimodal datasets, demonstrating the effectiveness of the proposed method in detecting fake news. In addition, SAMPLE also is superior to other approaches regardless of few-shot and data-rich settings.
Classification Aware Neural Topic Model and its Application on a New COVID-19 Disinformation Corpus
Jun 05, 2020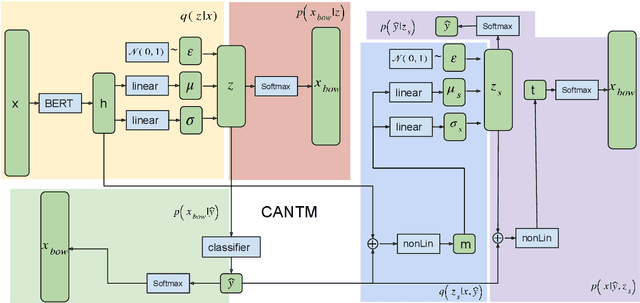
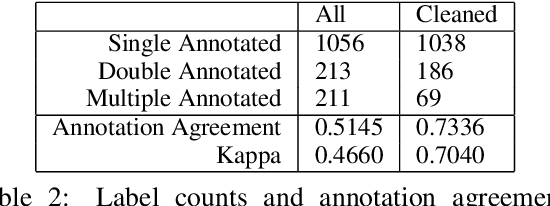
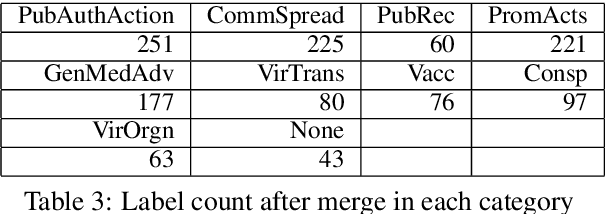
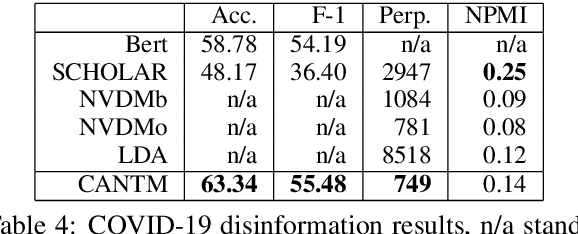
The explosion of disinformation related to the COVID-19 pandemic has overloaded fact-checkers and media worldwide. To help tackle this, we developed computational methods to support COVID-19 disinformation debunking and social impacts research. This paper presents: 1) the currently largest available manually annotated COVID-19 disinformation category dataset; and 2) a classification-aware neural topic model (CANTM) that combines classification and topic modelling under a variational autoencoder framework. We demonstrate that CANTM efficiently improves classification performance with low resources, and is scalable. In addition, the classification-aware topics help researchers and end-users to better understand the classification results.
Helping Crisis Responders Find the Informative Needle in the Tweet Haystack
Jan 29, 2018
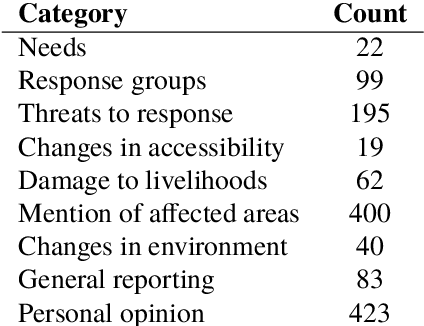
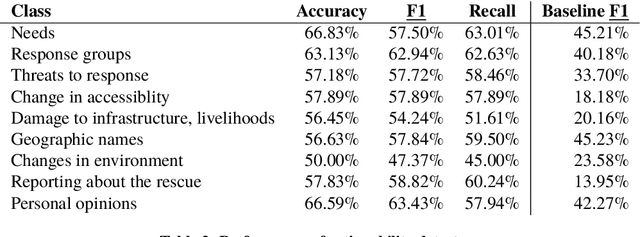
Crisis responders are increasingly using social media, data and other digital sources of information to build a situational understanding of a crisis situation in order to design an effective response. However with the increased availability of such data, the challenge of identifying relevant information from it also increases. This paper presents a successful automatic approach to handling this problem. Messages are filtered for informativeness based on a definition of the concept drawn from prior research and crisis response experts. Informative messages are tagged for actionable data -- for example, people in need, threats to rescue efforts, changes in environment, and so on. In all, eight categories of actionability are identified. The two components -- informativeness and actionability classification -- are packaged together as an openly-available tool called Emina (Emergent Informativeness and Actionability).