 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensions of Online Conflict: Towards Modeling Agonism
Nov 06, 2023



Agonism plays a vital role in democratic dialogue by fostering diverse perspectives and robust discussions. Within the realm of online conflict there is another type: hateful antagonism, which undermines constructive dialogue. Detecting conflict online is central to platform moderation and monetization. It is also vital for democratic dialogue, but only when it takes the form of agonism. To model these two types of conflict, we collected Twitter conversations related to trending controversial topics. We introduce a comprehensive annotation schema for labelling different dimensions of conflict in the conversations, such as the source of conflict, the target, and the rhetorical strategies deployed. Using this schema, we annotated approximately 4,000 conversations with multiple labels. We then trained both logistic regression and transformer-based models on the dataset, incorporating context from the conversation, including the number of participants and the structure of the interactions. Results show that contextual labels are helpful in identifying conflict and make the models robust to variations in topic. Our research contributes a conceptualization of different dimensions of conflict, a richly annotated dataset, and promising results that can contribute to content moderation.
* To appear
Radar de Parité: An NLP system to measure gender representation in French news stories
Apr 19, 2023We present the Radar de Parit\'e, an automated Natural Language Processing (NLP) system that measures the proportion of women and men quoted daily in six Canadian French-language media outlets. We outline the system's architecture and detail the challenges we overcame to address French-specific issues, in particular regarding coreference resolution, a new contribution to the NLP literature on French. We also showcase statistics covering over one year's worth of data (282,512 news articles). Our results highlight the underrepresentation of women in news stories, while also illustrating the application of modern NLP methods to measure gender representation and address societal issues.
* Full conference paper plus appendix
Classifying Constructive Comments
Apr 14, 2020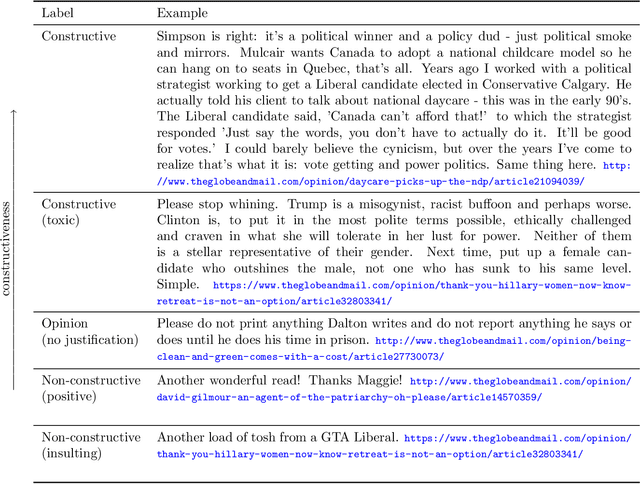
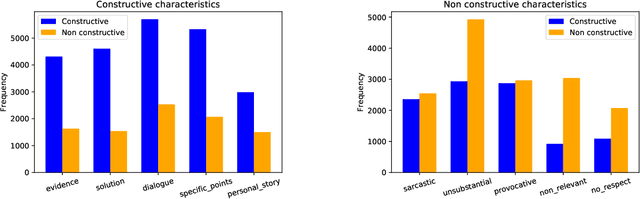
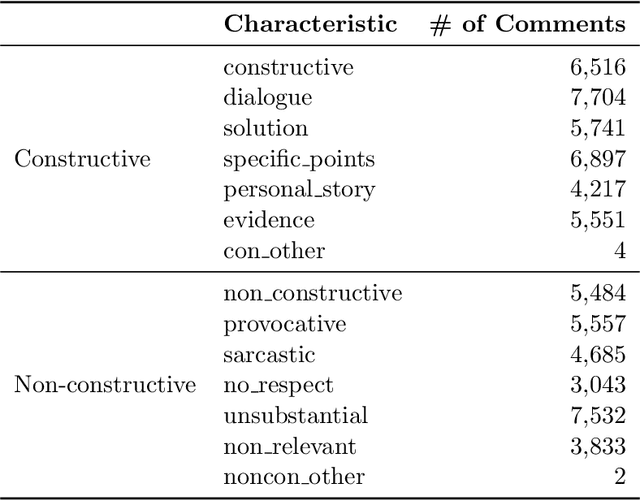

We introduce the Constructive Comments Corpus (C3), comprised of 12,000 annotated news comments, intended to help build new tools for online communities to improve the quality of their discussions. We define constructive comments as high-quality comments that make a contribution to the conversation. We explain the crowd worker annotation scheme and define a taxonomy of sub-characteristics of constructiveness. The quality of the annotation scheme and the resulting dataset is evaluated using measurements of inter-annotator agreement, expert assessment of a sample, and by the constructiveness sub-characteristics, which we show provide a proxy for the general constructiveness concept. We provide models for constructiveness trained on C3 using both feature-based and a variety of deep learning approaches and demonstrate that these models capture general rather than topic- or domain-specific characteristics of constructiveness, through domain adaptation experiments. We examine the role that length plays in our models, as comment length could be easily gamed if models depend heavily upon this feature. By examining the errors made by each model and their distribution by length, we show that the best performing models are less correlated with comment length.The constructiveness corpus and our experiments pave the way for a moderation tool focused on promoting comments that make a contribution, rather than only filtering out undesirable content.
Semantic descriptions of 24 evaluational adjectives, for application in sentiment analysis
Aug 24, 2016
We apply the Natural Semantic Metalanguage (NSM) approach (Goddard and Wierzbicka 2014) to the lexical-semantic analysis of English evaluational adjectives and compare the results with the picture developed in the Appraisal Framework (Martin and White 2005). The analysis is corpus-assisted, with examples mainly drawn from film and book reviews, and supported by collocational and statistical information from WordBanks Online. We propose NSM explications for 24 evaluational adjectives, arguing that they fall into five groups, each of which corresponds to a distinct semantic template. The groups can be sketched as follows: "First-person thought-plus-affect", e.g. wonderful; "Experiential", e.g. entertaining; "Experiential with bodily reaction", e.g. gripping; "Lasting impact", e.g. memorable; "Cognitive evaluation", e.g. complex, excellent. These groupings and semantic templates are compared with the classifications in the Appraisal Framework's system of Appreciation. In addition, we are particularly interested in sentiment analysis, the automatic identification of evaluation and subjectivity in text. We discuss the relevance of the two frameworks for sentiment analysis and other language technology applications.