 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHostility Detection in UK Politics: A Dataset on Online Abuse Targeting MPs
Dec 05, 2024
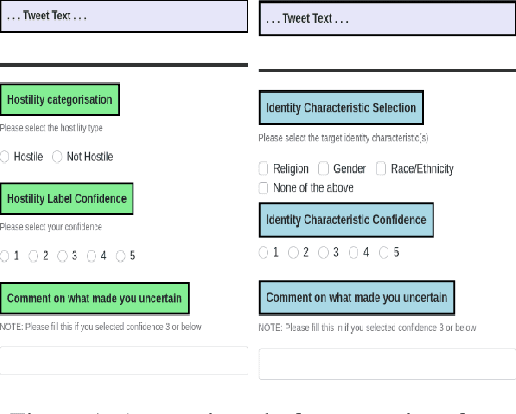
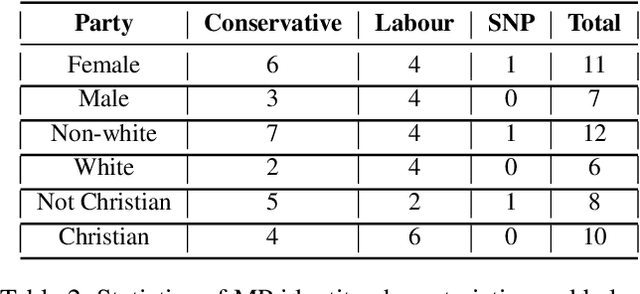
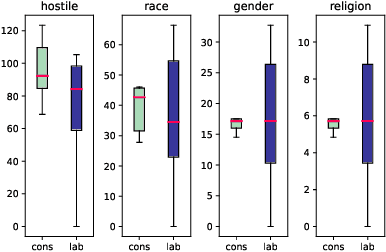
Numerous politicians use social media platforms, particularly X, to engage with their constituents. This interaction allows constituents to pose questions and offer feedback but also exposes politicians to a barrage of hostile responses, especially given the anonymity afforded by social media. They are typically targeted in relation to their governmental role, but the comments also tend to attack their personal identity. This can discredit politicians and reduce public trust in the government. It can also incite anger and disrespect, leading to offline harm and violence. While numerous models exist for detecting hostility in general, they lack the specificity required for political contexts. Furthermore, addressing hostility towards politicians demands tailored approaches due to the distinct language and issues inherent to each country (e.g., Brexit for the UK). To bridge this gap, we construct a dataset of 3,320 English tweets spanning a two-year period manually annotated for hostility towards UK MPs. Our dataset also captures the targeted identity characteristics (race, gender, religion, none) in hostile tweets. We perform linguistic and topical analyses to delve into the unique content of the UK political data. Finally, we evaluate the performance of pre-trained language models and large language models on binary hostility detection and multi-class targeted identity type classification tasks. Our study offers valuable data and insights for future research on the prevalence and nature of politics-related hostility specific to the UK.
Enhancing Data Quality through Simple De-duplication: Navigating Responsible Computational Social Science Research
Oct 04, 2024

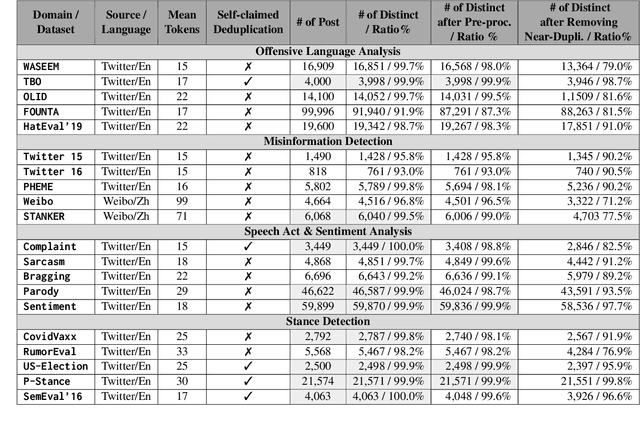

Research in natural language processing (NLP) for Computational Social Science (CSS) heavily relies on data from social media platforms. This data plays a crucial role in the development of models for analysing socio-linguistic phenomena within online communities. In this work, we conduct an in-depth examination of 20 datasets extensively used in NLP for CSS to comprehensively examine data quality. Our analysis reveals that social media datasets exhibit varying levels of data duplication. Consequently, this gives rise to challenges like label inconsistencies and data leakage, compromising the reliability of models. Our findings also suggest that data duplication has an impact on the current claims of state-of-the-art performance, potentially leading to an overestimation of model effectiveness in real-world scenarios. Finally, we propose new protocols and best practices for improving dataset development from social media data and its usage.
Who is bragging more online? A large scale analysis of bragging in social media
Mar 25, 2024



Bragging is the act of uttering statements that are likely to be positively viewed by others and it is extensively employed in human communication with the aim to build a positive self-image of oneself. Social media is a natural platform for users to employ bragging in order to gain admiration, respect, attention and followers from their audiences. Yet, little is known about the scale of bragging online and its characteristics. This paper employs computational sociolinguistics methods to conduct the first large scale study of bragging behavior on Twitter (U.S.) by focusing on its overall prevalence, temporal dynamics and impact of demographic factors. Our study shows that the prevalence of bragging decreases over time within the same population of users. In addition, younger, more educated and popular users in the U.S. are more likely to brag. Finally, we conduct an extensive linguistics analysis to unveil specific bragging themes associated with different user traits.
Dimensions of Online Conflict: Towards Modeling Agonism
Nov 06, 2023



Agonism plays a vital role in democratic dialogue by fostering diverse perspectives and robust discussions. Within the realm of online conflict there is another type: hateful antagonism, which undermines constructive dialogue. Detecting conflict online is central to platform moderation and monetization. It is also vital for democratic dialogue, but only when it takes the form of agonism. To model these two types of conflict, we collected Twitter conversations related to trending controversial topics. We introduce a comprehensive annotation schema for labelling different dimensions of conflict in the conversations, such as the source of conflict, the target, and the rhetorical strategies deployed. Using this schema, we annotated approximately 4,000 conversations with multiple labels. We then trained both logistic regression and transformer-based models on the dataset, incorporating context from the conversation, including the number of participants and the structure of the interactions. Results show that contextual labels are helpful in identifying conflict and make the models robust to variations in topic. Our research contributes a conceptualization of different dimensions of conflict, a richly annotated dataset, and promising results that can contribute to content moderation.
* To appear
Examining Temporal Bias in Abusive Language Detection
Sep 25, 2023
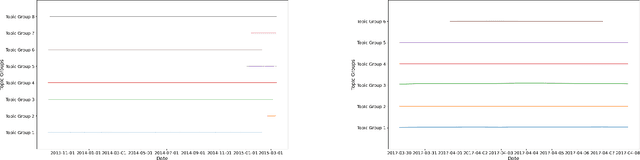
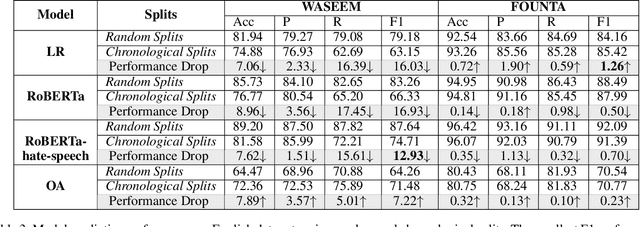
The use of abusive language online has become an increasingly pervasive problem that damages both individuals and society, with effects ranging from psychological harm right through to escalation to real-life violence and even death. Machine learning models have been developed to automatically detect abusive language, but these models can suffer from temporal bias, the phenomenon in which topics, language use or social norms change over time. This study aims to investigate the nature and impact of temporal bias in abusive language detection across various languages and explore mitigation methods. We evaluate the performance of models on abusive data sets from different time periods. Our results demonstrate that temporal bias is a significant challenge for abusive language detection, with models trained on historical data showing a significant drop in performance over time. We also present an extensive linguistic analysis of these abusive data sets from a diachronic perspective, aiming to explore the reasons for language evolution and performance decline. This study sheds light on the pervasive issue of temporal bias in abusive language detection across languages, offering crucial insights into language evolution and temporal bias mitigation.
Examining Temporalities on Stance Detection Towards COVID-19 Vaccination
Apr 10, 2023Previous studies have highlighted the importance of vaccination as an effective strategy to control the transmission of the COVID-19 virus. It is crucial for policymakers to have a comprehensive understanding of the public's stance towards vaccination on a large scale. However, attitudes towards COVID-19 vaccination, such as pro-vaccine or vaccine hesitancy, have evolved over time on social media. Thus, it is necessary to account for possible temporal shifts when analysing these stances. This study aims to examine the impact of temporal concept drift on stance detection towards COVID-19 vaccination on Twitter. To this end, we evaluate a range of transformer-based models using chronological and random splits of social media data. Our findings demonstrate significant discrepancies in model performance when comparing random and chronological splits across all monolingual and multilingual datasets. Chronological splits significantly reduce the accuracy of stance classification. Therefore, real-world stance detection approaches need to be further refined to incorporate temporal factors as a key consideration.
VaxxHesitancy: A Dataset for Studying Hesitancy Towards COVID-19 Vaccination on Twitter
Jan 17, 2023



Vaccine hesitancy has been a common concern, probably since vaccines were created and, with the popularisation of social media, people started to express their concerns about vaccines online alongside those posting pro- and anti-vaccine content. Predictably, since the first mentions of a COVID-19 vaccine, social media users posted about their fears and concerns or about their support and belief into the effectiveness of these rapidly developing vaccines. Identifying and understanding the reasons behind public hesitancy towards COVID-19 vaccines is important for policy markers that need to develop actions to better inform the population with the aim of increasing vaccine take-up. In the case of COVID-19, where the fast development of the vaccines was mirrored closely by growth in anti-vaxx disinformation, automatic means of detecting citizen attitudes towards vaccination became necessary. This is an important computational social sciences task that requires data analysis in order to gain in-depth understanding of the phenomena at hand. Annotated data is also necessary for training data-driven models for more nuanced analysis of attitudes towards vaccination. To this end, we created a new collection of over 3,101 tweets annotated with users' attitudes towards COVID-19 vaccination (stance). Besides, we also develop a domain-specific language model (VaxxBERT) that achieves the best predictive performance (73.0 accuracy and 69.3 F1-score) as compared to a robust set of baselines. To the best of our knowledge, these are the first dataset and model that model vaccine hesitancy as a category distinct from pro- and anti-vaccine stance.
Automatic Identification and Classification of Bragging in Social Media
Mar 11, 2022



Bragging is a speech act employed with the goal of constructing a favorable self-image through positive statements about oneself. It is widespread in daily communication and especially popular in social media, where users aim to build a positive image of their persona directly or indirectly. In this paper, we present the first large scale study of bragging in computational linguistics, building on previous research in linguistics and pragmatics. To facilitate this, we introduce a new publicly available data set of tweets annotated for bragging and their types. We empirically evaluate different transformer-based models injected with linguistic information in (a) binary bragging classification, i.e., if tweets contain bragging statements or not; and (b) multi-class bragging type prediction including not bragging. Our results show that our models can predict bragging with macro F1 up to 72.42 and 35.95 in the binary and multi-class classification tasks respectively. Finally, we present an extensive linguistic and error analysis of bragging prediction to guide future research on this topic.
Modeling the Severity of Complaints in Social Media
Mar 23, 2021



The speech act of complaining is used by humans to communicate a negative mismatch between reality and expectations as a reaction to an unfavorable situation. Linguistic theory of pragmatics categorizes complaints into various severity levels based on the face-threat that the complainer is willing to undertake. This is particularly useful for understanding the intent of complainers and how humans develop suitable apology strategies. In this paper, we study the severity level of complaints for the first time in computational linguistics. To facilitate this, we enrich a publicly available data set of complaints with four severity categories and train different transformer-based networks combined with linguistic information achieving 55.7 macro F1. We also jointly model binary complaint classification and complaint severity in a multi-task setting achieving new state-of-the-art results on binary complaint detection reaching up to 88.2 macro F1. Finally, we present a qualitative analysis of the behavior of our models in predicting complaint severity levels.
Complaint Identification in Social Media with Transformer Networks
Oct 21, 2020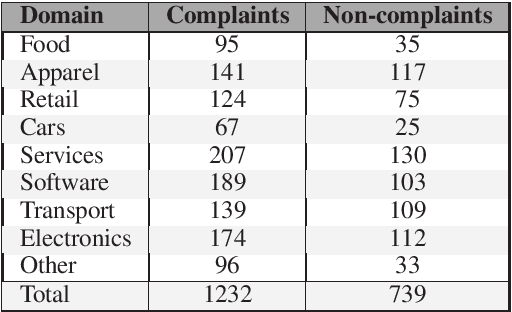
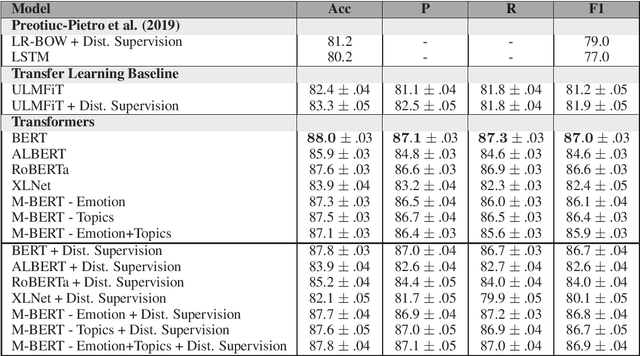
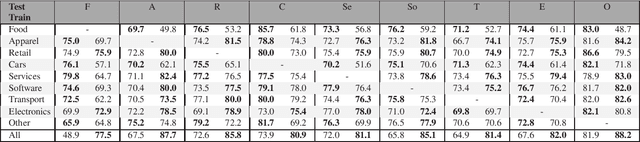
Complaining is a speech act extensively used by humans to communicate a negative inconsistency between reality and expectations. Previous work on automatically identifying complaints in social media has focused on using feature-based and task-specific neural network models. Adapting state-of-the-art pre-trained neural language models and their combinations with other linguistic information from topics or sentiment for complaint prediction has yet to be explored. In this paper, we evaluate a battery of neural models underpinned by transformer networks which we subsequently combine with linguistic information. Experiments on a publicly available data set of complaints demonstrate that our models outperform previous state-of-the-art methods by a large margin achieving a macro F1 up to 87.