 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Temporal Bias in Abusive Language Detection
Paper and Code

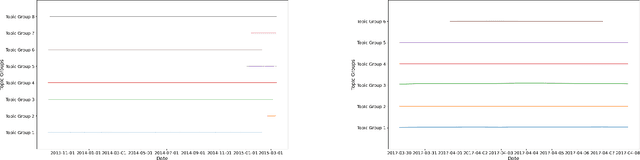
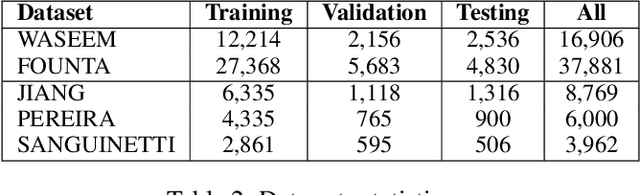
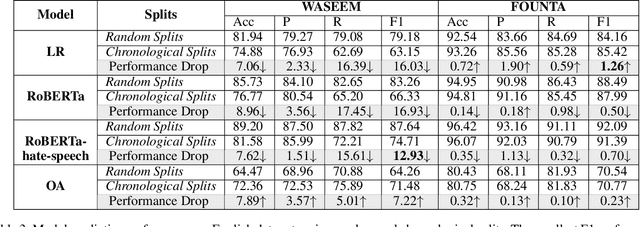
The use of abusive language online has become an increasingly pervasive problem that damages both individuals and society, with effects ranging from psychological harm right through to escalation to real-life violence and even death. Machine learning models have been developed to automatically detect abusive language, but these models can suffer from temporal bias, the phenomenon in which topics, language use or social norms change over time. This study aims to investigate the nature and impact of temporal bias in abusive language detection across various languages and explore mitigation methods. We evaluate the performance of models on abusive data sets from different time periods. Our results demonstrate that temporal bias is a significant challenge for abusive language detection, with models trained on historical data showing a significant drop in performance over time. We also present an extensive linguistic analysis of these abusive data sets from a diachronic perspective, aiming to explore the reasons for language evolution and performance decline. This study sheds light on the pervasive issue of temporal bias in abusive language detection across languages, offering crucial insights into language evolution and temporal bias mitigation.