 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Analysing News Framing in Chinese Media
Mar 06, 2025



Framing is an essential device in news reporting, allowing the writer to influence public perceptions of current affairs. While there are existing automatic news framing detection datasets in various languages, none of them focus on news framing in the Chinese language which has complex character meanings and unique linguistic features. This study introduces the first Chinese News Framing dataset, to be used as either a stand-alone dataset or a supplementary resource to the SemEval-2023 task 3 dataset. We detail its creation and we run baseline experiments to highlight the need for such a dataset and create benchmarks for future research, providing results obtained through fine-tuning XLM-RoBERTa-Base and using GPT-4o in the zero-shot setting. We find that GPT-4o performs significantly worse than fine-tuned XLM-RoBERTa across all languages. For the Chinese language, we obtain an F1-micro (the performance metric for SemEval task 3, subtask 2) score of 0.719 using only samples from our Chinese News Framing dataset and a score of 0.753 when we augment the SemEval dataset with Chinese news framing samples. With positive news frame detection results, this dataset is a valuable resource for detecting news frames in the Chinese language and is a valuable supplement to the SemEval-2023 task 3 dataset.
Enhancing Data Quality through Simple De-duplication: Navigating Responsible Computational Social Science Research
Oct 04, 2024

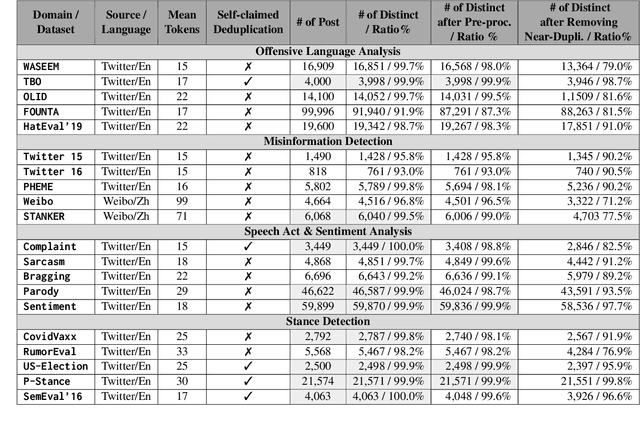

Research in natural language processing (NLP) for Computational Social Science (CSS) heavily relies on data from social media platforms. This data plays a crucial role in the development of models for analysing socio-linguistic phenomena within online communities. In this work, we conduct an in-depth examination of 20 datasets extensively used in NLP for CSS to comprehensively examine data quality. Our analysis reveals that social media datasets exhibit varying levels of data duplication. Consequently, this gives rise to challenges like label inconsistencies and data leakage, compromising the reliability of models. Our findings also suggest that data duplication has an impact on the current claims of state-of-the-art performance, potentially leading to an overestimation of model effectiveness in real-world scenarios. Finally, we propose new protocols and best practices for improving dataset development from social media data and its usage.
Addressing Topic Granularity and Hallucination in Large Language Models for Topic Modelling
May 01, 2024



Large language models (LLMs) with their strong zero-shot topic extraction capabilities offer an alternative to probabilistic topic modelling and closed-set topic classification approaches. As zero-shot topic extractors, LLMs are expected to understand human instructions to generate relevant and non-hallucinated topics based on the given documents. However, LLM-based topic modelling approaches often face difficulties in generating topics with adherence to granularity as specified in human instructions, often resulting in many near-duplicate topics. Furthermore, methods for addressing hallucinated topics generated by LLMs have not yet been investigated. In this paper, we focus on addressing the issues of topic granularity and hallucinations for better LLM-based topic modelling. To this end, we introduce a novel approach that leverages Direct Preference Optimisation (DPO) to fine-tune open-source LLMs, such as Mistral-7B. Our approach does not rely on traditional human annotation to rank preferred answers but employs a reconstruction pipeline to modify raw topics generated by LLMs, thus enabling a fast and efficient training and inference framework. Comparative experiments show that our fine-tuning approach not only significantly improves the LLM's capability to produce more coherent, relevant, and precise topics, but also reduces the number of hallucinated topics.
Large Language Models Offer an Alternative to the Traditional Approach of Topic Modelling
Mar 26, 2024Topic modelling, as a well-established unsupervised technique, has found extensive use in automatically detecting significant topics within a corpus of documents. However, classic topic modelling approaches (e.g., LDA) have certain drawbacks, such as the lack of semantic understanding and the presence of overlapping topics. In this work, we investigate the untapped potential of large language models (LLMs) as an alternative for uncovering the underlying topics within extensive text corpora. To this end, we introduce a framework that prompts LLMs to generate topics from a given set of documents and establish evaluation protocols to assess the clustering efficacy of LLMs. Our findings indicate that LLMs with appropriate prompts can stand out as a viable alternative, capable of generating relevant topic titles and adhering to human guidelines to refine and merge topics. Through in-depth experiments and evaluation, we summarise the advantages and constraints of employing LLMs in topic extraction.
Don't Waste a Single Annotation: Improving Single-Label Classifiers Through Soft Labels
Nov 09, 2023



In this paper, we address the limitations of the common data annotation and training methods for objective single-label classification tasks. Typically, when annotating such tasks annotators are only asked to provide a single label for each sample and annotator disagreement is discarded when a final hard label is decided through majority voting. We challenge this traditional approach, acknowledging that determining the appropriate label can be difficult due to the ambiguity and lack of context in the data samples. Rather than discarding the information from such ambiguous annotations, our soft label method makes use of them for training. Our findings indicate that additional annotator information, such as confidence, secondary label and disagreement, can be used to effectively generate soft labels. Training classifiers with these soft labels then leads to improved performance and calibration on the hard label test set.
Examining Temporal Bias in Abusive Language Detection
Sep 25, 2023
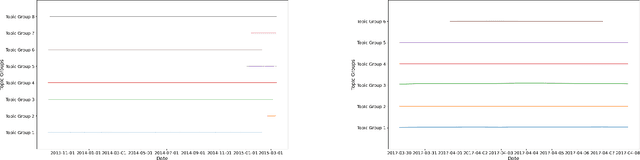
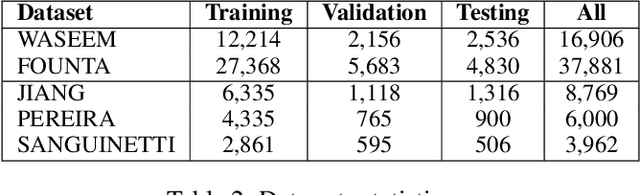
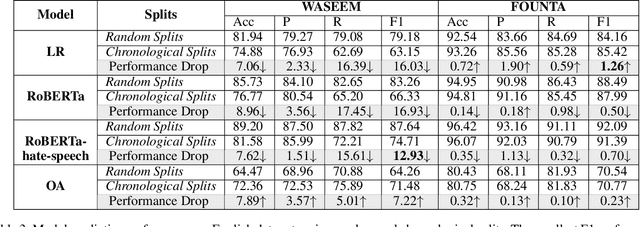
The use of abusive language online has become an increasingly pervasive problem that damages both individuals and society, with effects ranging from psychological harm right through to escalation to real-life violence and even death. Machine learning models have been developed to automatically detect abusive language, but these models can suffer from temporal bias, the phenomenon in which topics, language use or social norms change over time. This study aims to investigate the nature and impact of temporal bias in abusive language detection across various languages and explore mitigation methods. We evaluate the performance of models on abusive data sets from different time periods. Our results demonstrate that temporal bias is a significant challenge for abusive language detection, with models trained on historical data showing a significant drop in performance over time. We also present an extensive linguistic analysis of these abusive data sets from a diachronic perspective, aiming to explore the reasons for language evolution and performance decline. This study sheds light on the pervasive issue of temporal bias in abusive language detection across languages, offering crucial insights into language evolution and temporal bias mitigation.
Examining the Limitations of Computational Rumor Detection Models Trained on Static Datasets
Sep 20, 2023A crucial aspect of a rumor detection model is its ability to generalize, particularly its ability to detect emerging, previously unknown rumors. Past research has indicated that content-based (i.e., using solely source posts as input) rumor detection models tend to perform less effectively on unseen rumors. At the same time, the potential of context-based models remains largely untapped. The main contribution of this paper is in the in-depth evaluation of the performance gap between content and context-based models specifically on detecting new, unseen rumors. Our empirical findings demonstrate that context-based models are still overly dependent on the information derived from the rumors' source post and tend to overlook the significant role that contextual information can play. We also study the effect of data split strategies on classifier performance. Based on our experimental results, the paper also offers practical suggestions on how to minimize the effects of temporal concept drift in static datasets during the training of rumor detection methods.
Classification-Aware Neural Topic Model Combined With Interpretable Analysis -- For Conflict Classification
Aug 29, 2023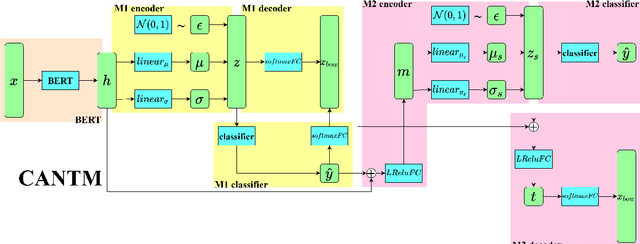

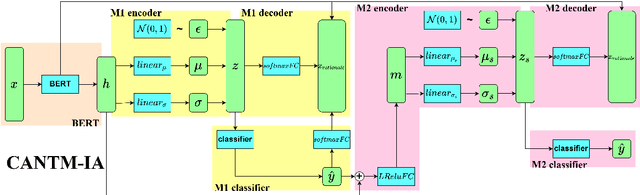

A large number of conflict events are affecting the world all the time. In order to analyse such conflict events effectively, this paper presents a Classification-Aware Neural Topic Model (CANTM-IA) for Conflict Information Classification and Topic Discovery. The model provides a reliable interpretation of classification results and discovered topics by introducing interpretability analysis. At the same time, interpretation is introduced into the model architecture to improve the classification performance of the model and to allow interpretation to focus further on the details of the data. Finally, the model architecture is optimised to reduce the complexity of the model.
Navigating Prompt Complexity for Zero-Shot Classification: A Study of Large Language Models in Computational Social Science
May 23, 2023
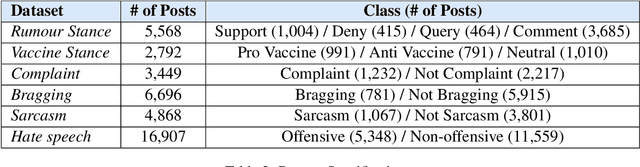
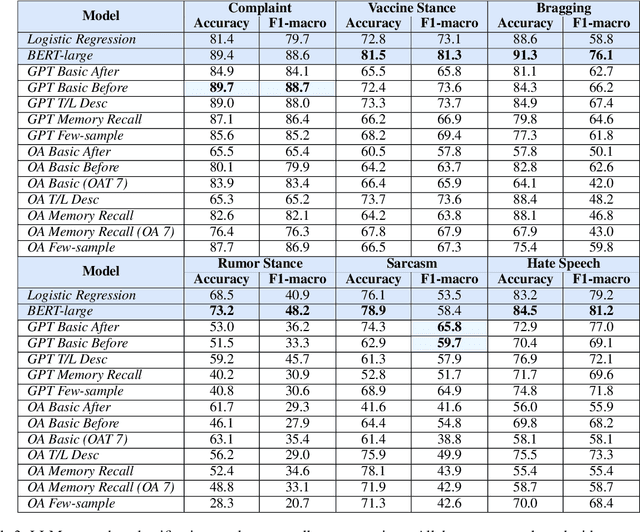
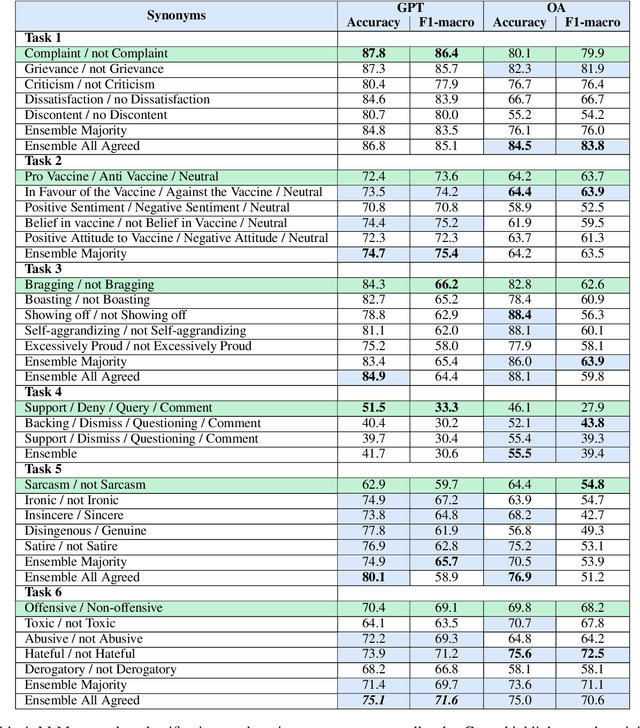
Instruction-tuned Large Language Models (LLMs) have exhibited impressive language understanding and the capacity to generate responses that follow specific instructions. However, due to the computational demands associated with training these models, their applications often rely on zero-shot settings. In this paper, we evaluate the zero-shot performance of two publicly accessible LLMs, ChatGPT and OpenAssistant, in the context of Computational Social Science classification tasks, while also investigating the effects of various prompting strategies. Our experiment considers the impact of prompt complexity, including the effect of incorporating label definitions into the prompt, using synonyms for label names, and the influence of integrating past memories during the foundation model training. The findings indicate that in a zero-shot setting, the current LLMs are unable to match the performance of smaller, fine-tuned baseline transformer models (such as BERT). Additionally, we find that different prompting strategies can significantly affect classification accuracy, with variations in accuracy and F1 scores exceeding 10%.
A Large-Scale Comparative Study of Accurate COVID-19 Information versus Misinformation
Apr 10, 2023



The COVID-19 pandemic led to an infodemic where an overwhelming amount of COVID-19 related content was being disseminated at high velocity through social media. This made it challenging for citizens to differentiate between accurate and inaccurate information about COVID-19. This motivated us to carry out a comparative study of the characteristics of COVID-19 misinformation versus those of accurate COVID-19 information through a large-scale computational analysis of over 242 million tweets. The study makes comparisons alongside four key aspects: 1) the distribution of topics, 2) the live status of tweets, 3) language analysis and 4) the spreading power over time. An added contribution of this study is the creation of a COVID-19 misinformation classification dataset. Finally, we demonstrate that this new dataset helps improve misinformation classification by more than 9% based on average F1 measure.