 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Funding: Reconstructing a Unified Dataset of the UK Funding Lifecycle
Mar 27, 2026We present a reconstruction of UKRI's Gateway to Research (GtR) database that links funding opportunities to their resulting project proposals through panel meeting outcomes. Unlike existing work that focuses primarily on funded projects and their outcomes, we close the complete funding lifecycle by integrating three previously disconnected data sources: the GtR project database, UKRI funding opportunities, and competitive funding decision records across UKRI's research councils. We describe the technical challenges of data collection, including navigating inconsistent publication formats and restricted access to panel decisions. The resulting dataset enables a holistic interrogation of the entire funding process, from opportunity announcement to research outcomes. We release the database and associated code.
Evaluating LLM-Based Grant Proposal Review via Structured Perturbations
Mar 11, 2026As AI-assisted grant proposals outpace manual review capacity in a kind of ``Malthusian trap'' for the research ecosystem, this paper investigates the capabilities and limitations of LLM-based grant reviewing for high-stakes evaluation. Using six EPSRC proposals, we develop a perturbation-based framework probing LLM sensitivity across six quality axes: funding, timeline, competency, alignment, clarity, and impact. We compare three review architectures: single-pass review, section-by-section analysis, and a 'Council of Personas' ensemble emulating expert panels. The section-level approach significantly outperforms alternatives in both detection rate and scoring reliability, while the computationally expensive council method performs no better than baseline. Detection varies substantially by perturbation type, with alignment issues readily identified but clarity flaws largely missed by all systems. Human evaluation shows LLM feedback is largely valid but skewed toward compliance checking over holistic assessment. We conclude that current LLMs may provide supplementary value within EPSRC review but exhibit high variability and misaligned review priorities. We release our code and any non-protected data.
Comparing Apples to Oranges: A Dataset & Analysis of LLM Humour Understanding from Traditional Puns to Topical Jokes
Jul 17, 2025
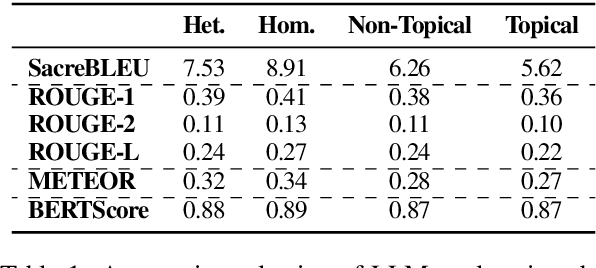
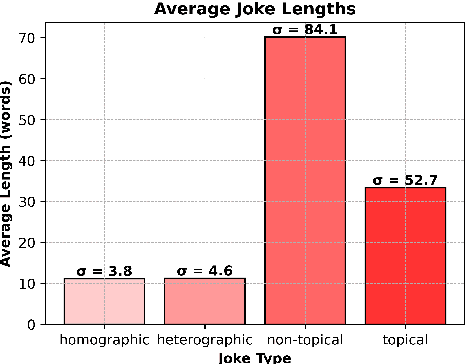
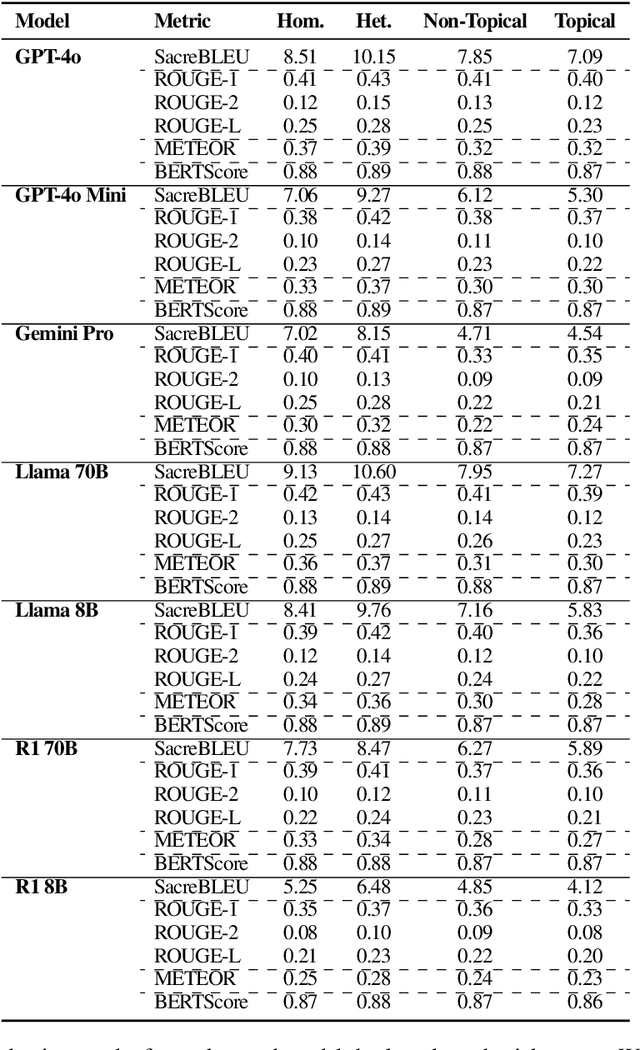
Humour, as a complex language form, is derived from myriad aspects of life, whilst existing work on computational humour has focussed almost exclusively on short pun-based jokes. In this work, we investigate whether the ability of Large Language Models (LLMs) to explain humour depends on the particular humour form. We compare models on simple puns and more complex topical humour that requires knowledge of real-world entities and events. In doing so, we curate a dataset of 600 jokes split across 4 joke types and manually write high-quality explanations. These jokes include heterographic and homographic puns, contemporary internet humour, and topical jokes, where understanding relies on reasoning beyond "common sense", rooted instead in world knowledge regarding news events and pop culture. Using this dataset, we compare the zero-shot abilities of a range of LLMs to accurately and comprehensively explain jokes of different types, identifying key research gaps in the task of humour explanation. We find that none of the tested models (inc. reasoning models) are capable of reliably generating adequate explanations of all joke types, further highlighting the narrow focus of most works in computational humour on overly simple joke forms.
Increasing the Difficulty of Automatically Generated Questions via Reinforcement Learning with Synthetic Preference
Oct 10, 2024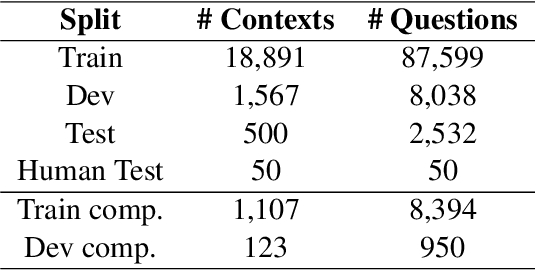

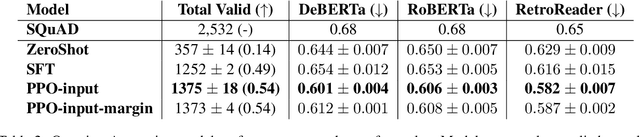

As the cultural heritage sector increasingly adopts technologies like Retrieval-Augmented Generation (RAG) to provide more personalised search experiences and enable conversations with collections data, the demand for specialised evaluation datasets has grown. While end-to-end system testing is essential, it's equally important to assess individual components. We target the final, answering task, which is well-suited to Machine Reading Comprehension (MRC). Although existing MRC datasets address general domains, they lack the specificity needed for cultural heritage information. Unfortunately, the manual creation of such datasets is prohibitively expensive for most heritage institutions. This paper presents a cost-effective approach for generating domain-specific MRC datasets with increased difficulty using Reinforcement Learning from Human Feedback (RLHF) from synthetic preference data. Our method leverages the performance of existing question-answering models on a subset of SQuAD to create a difficulty metric, assuming that more challenging questions are answered correctly less frequently. This research contributes: (1) A methodology for increasing question difficulty using PPO and synthetic data; (2) Empirical evidence of the method's effectiveness, including human evaluation; (3) An in-depth error analysis and study of emergent phenomena; and (4) An open-source codebase and set of three llama-2-chat adapters for reproducibility and adaptation.
Bio-SIEVE: Exploring Instruction Tuning Large Language Models for Systematic Review Automation
Aug 12, 2023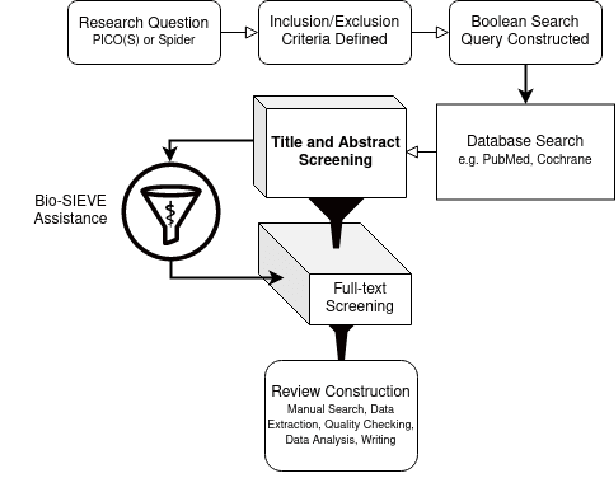
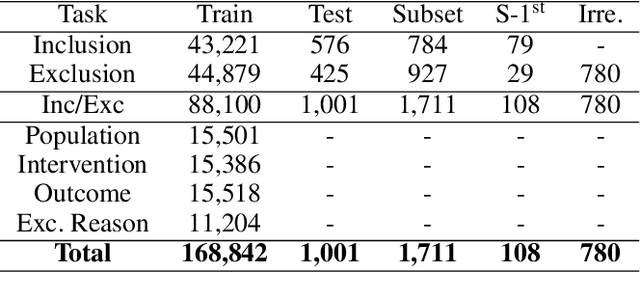
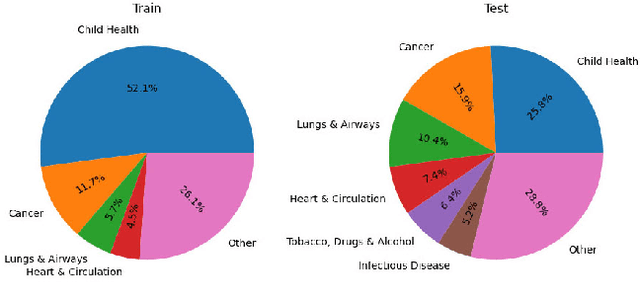
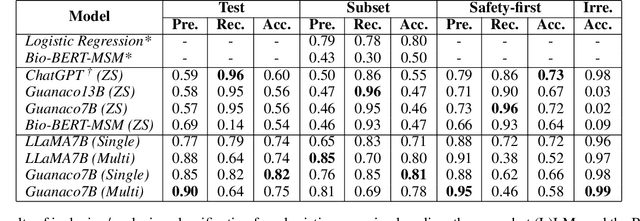
Medical systematic reviews can be very costly and resource intensive. We explore how Large Language Models (LLMs) can support and be trained to perform literature screening when provided with a detailed set of selection criteria. Specifically, we instruction tune LLaMA and Guanaco models to perform abstract screening for medical systematic reviews. Our best model, Bio-SIEVE, outperforms both ChatGPT and trained traditional approaches, and generalises better across medical domains. However, there remains the challenge of adapting the model to safety-first scenarios. We also explore the impact of multi-task training with Bio-SIEVE-Multi, including tasks such as PICO extraction and exclusion reasoning, but find that it is unable to match single-task Bio-SIEVE's performance. We see Bio-SIEVE as an important step towards specialising LLMs for the biomedical systematic review process and explore its future developmental opportunities. We release our models, code and a list of DOIs to reconstruct our dataset for reproducibility.
Navigating Prompt Complexity for Zero-Shot Classification: A Study of Large Language Models in Computational Social Science
May 23, 2023
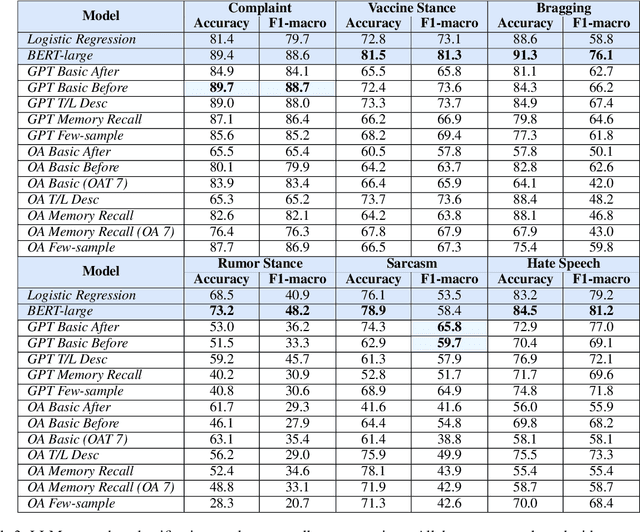
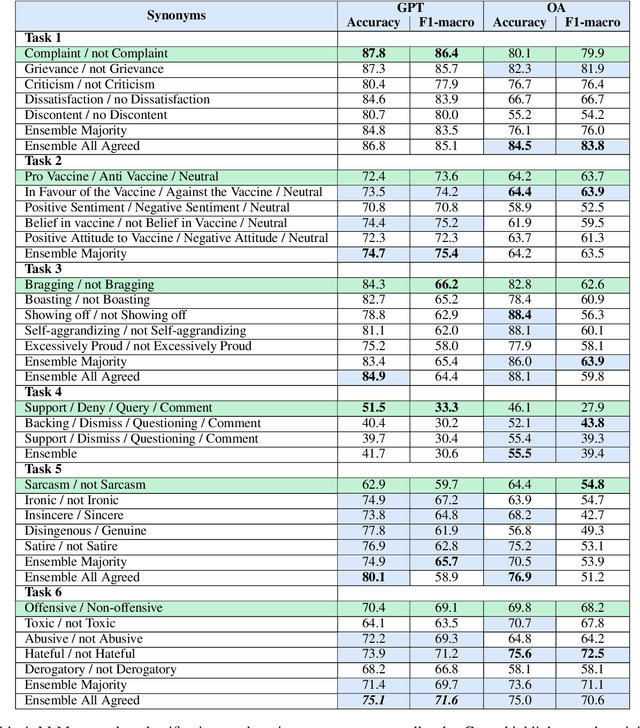
Instruction-tuned Large Language Models (LLMs) have exhibited impressive language understanding and the capacity to generate responses that follow specific instructions. However, due to the computational demands associated with training these models, their applications often rely on zero-shot settings. In this paper, we evaluate the zero-shot performance of two publicly accessible LLMs, ChatGPT and OpenAssistant, in the context of Computational Social Science classification tasks, while also investigating the effects of various prompting strategies. Our experiment considers the impact of prompt complexity, including the effect of incorporating label definitions into the prompt, using synonyms for label names, and the influence of integrating past memories during the foundation model training. The findings indicate that in a zero-shot setting, the current LLMs are unable to match the performance of smaller, fine-tuned baseline transformer models (such as BERT). Additionally, we find that different prompting strategies can significantly affect classification accuracy, with variations in accuracy and F1 scores exceeding 10%.