 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Difficulty of Automatically Generated Questions via Reinforcement Learning with Synthetic Preference
Paper and Code
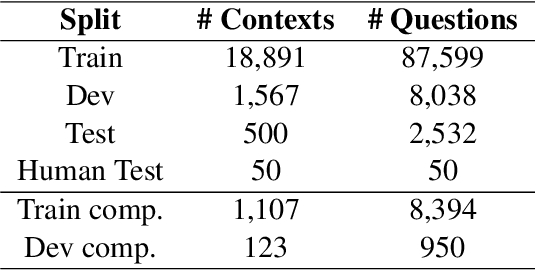

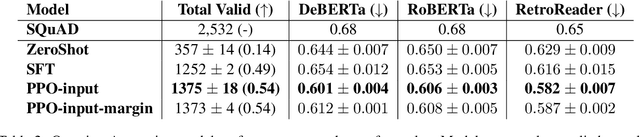

As the cultural heritage sector increasingly adopts technologies like Retrieval-Augmented Generation (RAG) to provide more personalised search experiences and enable conversations with collections data, the demand for specialised evaluation datasets has grown. While end-to-end system testing is essential, it's equally important to assess individual components. We target the final, answering task, which is well-suited to Machine Reading Comprehension (MRC). Although existing MRC datasets address general domains, they lack the specificity needed for cultural heritage information. Unfortunately, the manual creation of such datasets is prohibitively expensive for most heritage institutions. This paper presents a cost-effective approach for generating domain-specific MRC datasets with increased difficulty using Reinforcement Learning from Human Feedback (RLHF) from synthetic preference data. Our method leverages the performance of existing question-answering models on a subset of SQuAD to create a difficulty metric, assuming that more challenging questions are answered correctly less frequently. This research contributes: (1) A methodology for increasing question difficulty using PPO and synthetic data; (2) Empirical evidence of the method's effectiveness, including human evaluation; (3) An in-depth error analysis and study of emergent phenomena; and (4) An open-source codebase and set of three llama-2-chat adapters for reproducibility and adaptation.