 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-SIEVE: Exploring Instruction Tuning Large Language Models for Systematic Review Automation
Aug 12, 2023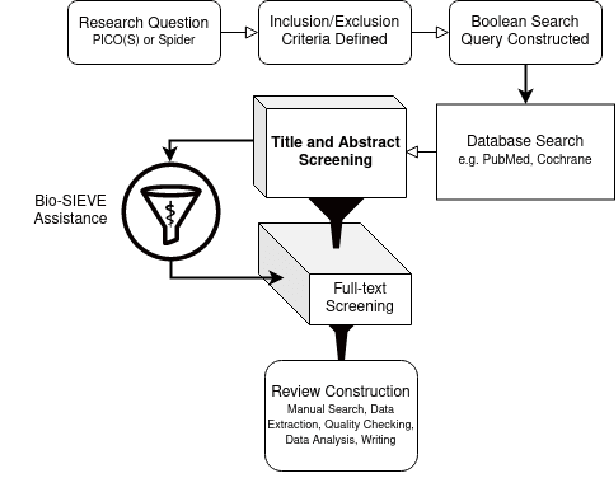
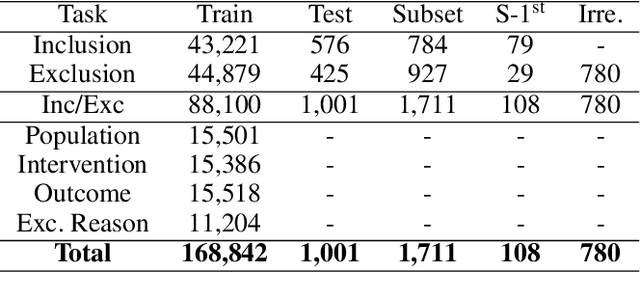
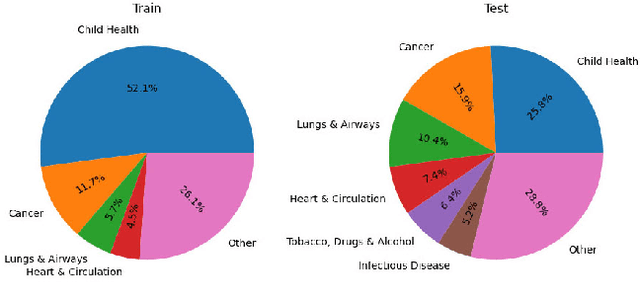
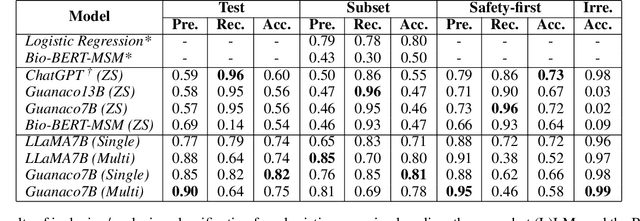
Medical systematic reviews can be very costly and resource intensive. We explore how Large Language Models (LLMs) can support and be trained to perform literature screening when provided with a detailed set of selection criteria. Specifically, we instruction tune LLaMA and Guanaco models to perform abstract screening for medical systematic reviews. Our best model, Bio-SIEVE, outperforms both ChatGPT and trained traditional approaches, and generalises better across medical domains. However, there remains the challenge of adapting the model to safety-first scenarios. We also explore the impact of multi-task training with Bio-SIEVE-Multi, including tasks such as PICO extraction and exclusion reasoning, but find that it is unable to match single-task Bio-SIEVE's performance. We see Bio-SIEVE as an important step towards specialising LLMs for the biomedical systematic review process and explore its future developmental opportunities. We release our models, code and a list of DOIs to reconstruct our dataset for reproducibility.
Navigating Prompt Complexity for Zero-Shot Classification: A Study of Large Language Models in Computational Social Science
May 23, 2023
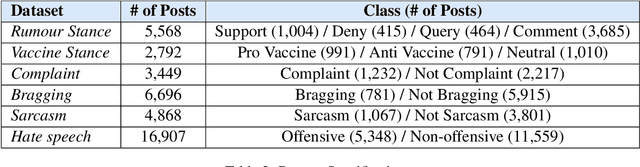
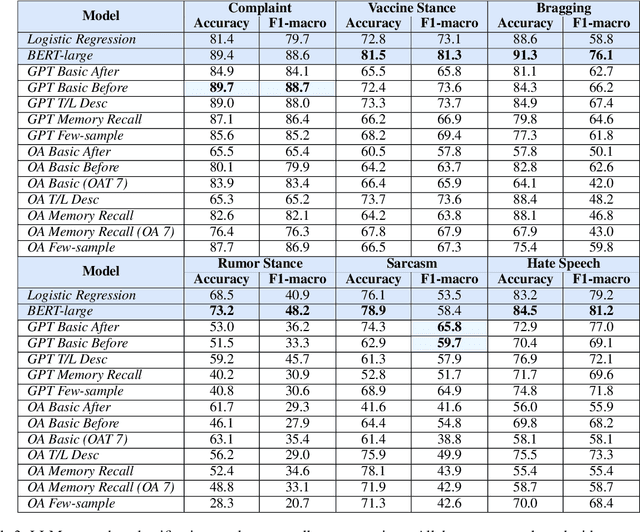
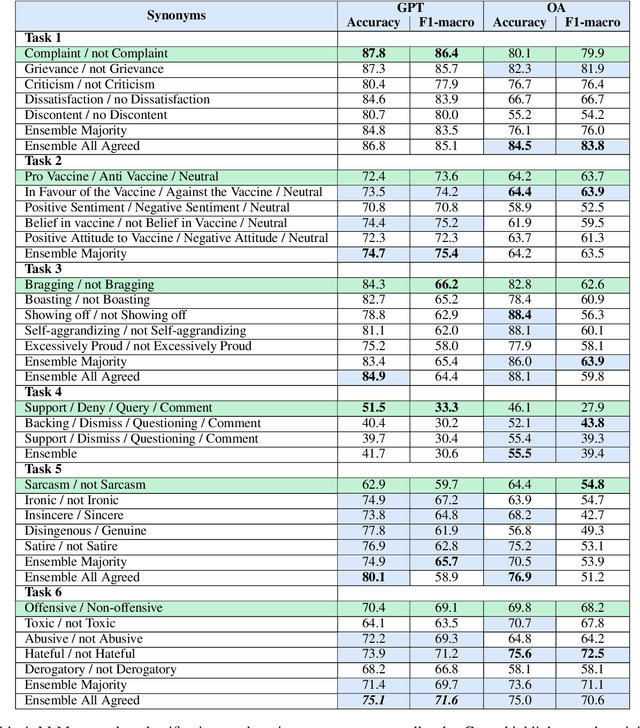
Instruction-tuned Large Language Models (LLMs) have exhibited impressive language understanding and the capacity to generate responses that follow specific instructions. However, due to the computational demands associated with training these models, their applications often rely on zero-shot settings. In this paper, we evaluate the zero-shot performance of two publicly accessible LLMs, ChatGPT and OpenAssistant, in the context of Computational Social Science classification tasks, while also investigating the effects of various prompting strategies. Our experiment considers the impact of prompt complexity, including the effect of incorporating label definitions into the prompt, using synonyms for label names, and the influence of integrating past memories during the foundation model training. The findings indicate that in a zero-shot setting, the current LLMs are unable to match the performance of smaller, fine-tuned baseline transformer models (such as BERT). Additionally, we find that different prompting strategies can significantly affect classification accuracy, with variations in accuracy and F1 scores exceeding 10%.