 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Adversarial Persuasion Attacks on Fact-Checking Systems
Jan 23, 2026Automated fact-checking (AFC) systems are susceptible to adversarial attacks, enabling false claims to evade detection. Existing adversarial frameworks typically rely on injecting noise or altering semantics, yet no existing framework exploits the adversarial potential of persuasion techniques, which are widely used in disinformation campaigns to manipulate audiences. In this paper, we introduce a novel class of persuasive adversarial attacks on AFCs by employing a generative LLM to rephrase claims using persuasion techniques. Considering 15 techniques grouped into 6 categories, we study the effects of persuasion on both claim verification and evidence retrieval using a decoupled evaluation strategy. Experiments on the FEVER and FEVEROUS benchmarks show that persuasion attacks can substantially degrade both verification performance and evidence retrieval. Our analysis identifies persuasion techniques as a potent class of adversarial attacks, highlighting the need for more robust AFC systems.
It's All About In-Context Learning! Teaching Extremely Low-Resource Languages to LLMs
Aug 26, 2025



Extremely low-resource languages, especially those written in rare scripts, as shown in Figure 1, remain largely unsupported by large language models (LLMs). This is due in part to compounding factors such as the lack of training data. This paper delivers the first comprehensive analysis of whether LLMs can acquire such languages purely via in-context learning (ICL), with or without auxiliary alignment signals, and how these methods compare to parameter-efficient fine-tuning (PEFT). We systematically evaluate 20 under-represented languages across three state-of-the-art multilingual LLMs. Our findings highlight the limitation of PEFT when both language and its script are extremely under-represented by the LLM. In contrast, zero-shot ICL with language alignment is impressively effective on extremely low-resource languages, while few-shot ICL or PEFT is more beneficial for languages relatively better represented by LLMs. For LLM practitioners working on extremely low-resource languages, we summarise guidelines grounded by our results on adapting LLMs to low-resource languages, e.g., avoiding fine-tuning a multilingual model on languages of unseen scripts.
GateNLP at SemEval-2025 Task 10: Hierarchical Three-Step Prompting for Multilingual Narrative Classification
May 28, 2025The proliferation of online news and the increasing spread of misinformation necessitate robust methods for automatic data analysis. Narrative classification is emerging as a important task, since identifying what is being said online is critical for fact-checkers, policy markers and other professionals working on information studies. This paper presents our approach to SemEval 2025 Task 10 Subtask 2, which aims to classify news articles into a pre-defined two-level taxonomy of main narratives and sub-narratives across multiple languages. We propose Hierarchical Three-Step Prompting (H3Prompt) for multilingual narrative classification. Our methodology follows a three-step Large Language Model (LLM) prompting strategy, where the model first categorises an article into one of two domains (Ukraine-Russia War or Climate Change), then identifies the most relevant main narratives, and finally assigns sub-narratives. Our approach secured the top position on the English test set among 28 competing teams worldwide. The code is available at https://github.com/GateNLP/H3Prompt.
SCRum-9: Multilingual Stance Classification over Rumours on Social Media
May 25, 2025We introduce SCRum-9, a multilingual dataset for Rumour Stance Classification, containing 7,516 tweet-reply pairs from X. SCRum-9 goes beyond existing stance classification datasets by covering more languages (9), linking examples to more fact-checked claims (2.1k), and including complex annotations from multiple annotators to account for intra- and inter-annotator variability. Annotations were made by at least three native speakers per language, totalling around 405 hours of annotation and 8,150 dollars in compensation. Experiments on SCRum-9 show that it is a challenging benchmark for both state-of-the-art LLMs (e.g. Deepseek) as well as fine-tuned pre-trained models, motivating future work in this area.
UKElectionNarratives: A Dataset of Misleading Narratives Surrounding Recent UK General Elections
May 08, 2025Misleading narratives play a crucial role in shaping public opinion during elections, as they can influence how voters perceive candidates and political parties. This entails the need to detect these narratives accurately. To address this, we introduce the first taxonomy of common misleading narratives that circulated during recent elections in Europe. Based on this taxonomy, we construct and analyse UKElectionNarratives: the first dataset of human-annotated misleading narratives which circulated during the UK General Elections in 2019 and 2024. We also benchmark Pre-trained and Large Language Models (focusing on GPT-4o), studying their effectiveness in detecting election-related misleading narratives. Finally, we discuss potential use cases and make recommendations for future research directions using the proposed codebook and dataset.
SemEval-2025 Task 1: AdMIRe -- Advancing Multimodal Idiomaticity Representation
Mar 19, 2025Idiomatic expressions present a unique challenge in NLP, as their meanings are often not directly inferable from their constituent words. Despite recent advancements in Large Language Models (LLMs), idiomaticity remains a significant obstacle to robust semantic representation. We present datasets and tasks for SemEval-2025 Task 1: AdMiRe (Advancing Multimodal Idiomaticity Representation), which challenges the community to assess and improve models' ability to interpret idiomatic expressions in multimodal contexts and in multiple languages. Participants competed in two subtasks: ranking images based on their alignment with idiomatic or literal meanings, and predicting the next image in a sequence. The most effective methods achieved human-level performance by leveraging pretrained LLMs and vision-language models in mixture-of-experts settings, with multiple queries used to smooth over the weaknesses in these models' representations of idiomaticity.
Leveraging Large Language Models for Zero-shot Lay Summarisation in Biomedicine and Beyond
Jan 09, 2025



In this work, we explore the application of Large Language Models to zero-shot Lay Summarisation. We propose a novel two-stage framework for Lay Summarisation based on real-life processes, and find that summaries generated with this method are increasingly preferred by human judges for larger models. To help establish best practices for employing LLMs in zero-shot settings, we also assess the ability of LLMs as judges, finding that they are able to replicate the preferences of human judges. Finally, we take the initial steps towards Lay Summarisation for Natural Language Processing (NLP) articles, finding that LLMs are able to generalise to this new domain, and further highlighting the greater utility of summaries generated by our proposed approach via an in-depth human evaluation.
A Cross-Domain Study of the Use of Persuasion Techniques in Online Disinformation
Dec 19, 2024Disinformation, irrespective of domain or language, aims to deceive or manipulate public opinion, typically through employing advanced persuasion techniques. Qualitative and quantitative research on the weaponisation of persuasion techniques in disinformation has been mostly topic-specific (e.g., COVID-19) with limited cross-domain studies, resulting in a lack of comprehensive understanding of these strategies. This study employs a state-of-the-art persuasion technique classifier to conduct a large-scale, multi-domain analysis of the role of 16 persuasion techniques in disinformation narratives. It shows how different persuasion techniques are employed disproportionately in different disinformation domains. We also include a detailed case study on climate change disinformation, highlighting how linguistic, psychological, and cultural factors shape the adaptation of persuasion strategies to fit unique thematic contexts.
Investigating Idiomaticity in Word Representations
Nov 04, 2024



Idiomatic expressions are an integral part of human languages, often used to express complex ideas in compressed or conventional ways (e.g. eager beaver as a keen and enthusiastic person). However, their interpretations may not be straightforwardly linked to the meanings of their individual components in isolation and this may have an impact for compositional approaches. In this paper, we investigate to what extent word representation models are able to go beyond compositional word combinations and capture multiword expression idiomaticity and some of the expected properties related to idiomatic meanings. We focus on noun compounds of varying levels of idiomaticity in two languages (English and Portuguese), presenting a dataset of minimal pairs containing human idiomaticity judgments for each noun compound at both type and token levels, their paraphrases and their occurrences in naturalistic and sense-neutral contexts, totalling 32,200 sentences. We propose this set of minimal pairs for evaluating how well a model captures idiomatic meanings, and define a set of fine-grained metrics of Affinity and Scaled Similarity, to determine how sensitive the models are to perturbations that may lead to changes in idiomaticity. The results obtained with a variety of representative and widely used models indicate that, despite superficial indications to the contrary in the form of high similarities, idiomaticity is not yet accurately represented in current models. Moreover, the performance of models with different levels of contextualisation suggests that their ability to capture context is not yet able to go beyond more superficial lexical clues provided by the words and to actually incorporate the relevant semantic clues needed for idiomaticity.
A Survey on Automatic Credibility Assessment of Textual Credibility Signals in the Era of Large Language Models
Oct 28, 2024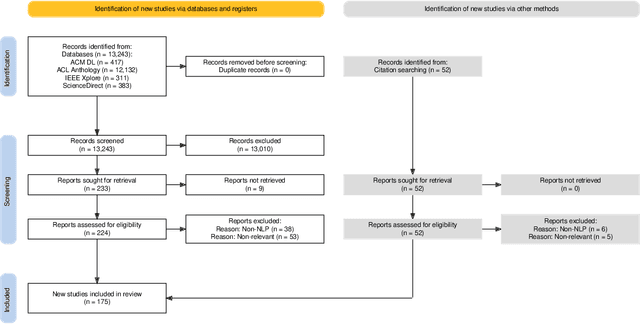
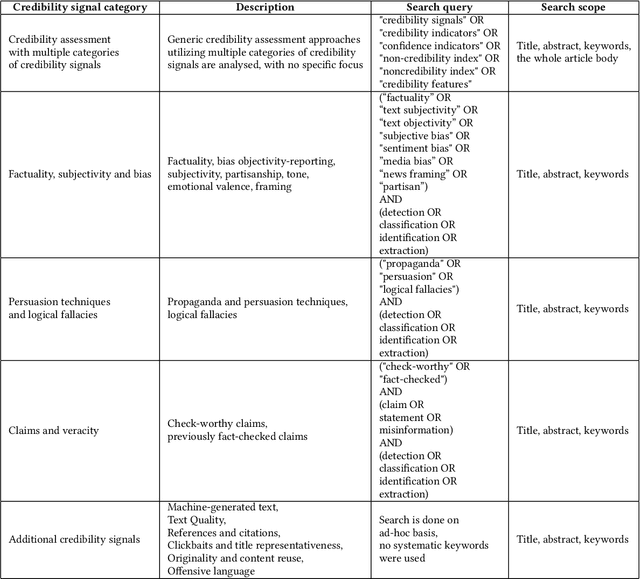
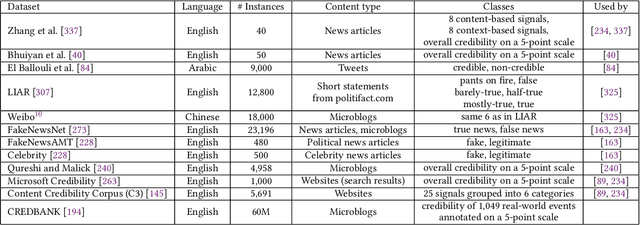
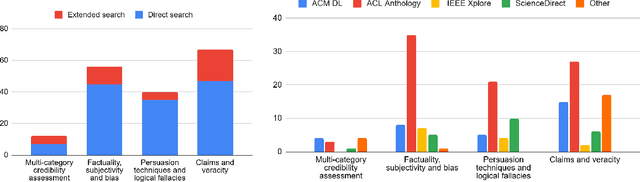
In the current era of social media and generative AI, an ability to automatically assess the credibility of online social media content is of tremendous importance. Credibility assessment is fundamentally based on aggregating credibility signals, which refer to small units of information, such as content factuality, bias, or a presence of persuasion techniques, into an overall credibility score. Credibility signals provide a more granular, more easily explainable and widely utilizable information in contrast to currently predominant fake news detection, which utilizes various (mostly latent) features. A growing body of research on automatic credibility assessment and detection of credibility signals can be characterized as highly fragmented and lacking mutual interconnections. This issue is even more prominent due to a lack of an up-to-date overview of research works on automatic credibility assessment. In this survey, we provide such systematic and comprehensive literature review of 175 research papers while focusing on textual credibility signals and Natural Language Processing (NLP), which undergoes a significant advancement due to Large Language Models (LLMs). While positioning the NLP research into the context of other multidisciplinary research works, we tackle with approaches for credibility assessment as well as with 9 categories of credibility signals (we provide a thorough analysis for 3 of them, namely: 1) factuality, subjectivity and bias, 2) persuasion techniques and logical fallacies, and 3) claims and veracity). Following the description of the existing methods, datasets and tools, we identify future challenges and opportunities, while paying a specific attention to recent rapid development of generative AI.