 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Leveraging Large Language Models for Zero-shot Lay Summarisation in Biomedicine and Beyond
Jan 09, 2025



In this work, we explore the application of Large Language Models to zero-shot Lay Summarisation. We propose a novel two-stage framework for Lay Summarisation based on real-life processes, and find that summaries generated with this method are increasingly preferred by human judges for larger models. To help establish best practices for employing LLMs in zero-shot settings, we also assess the ability of LLMs as judges, finding that they are able to replicate the preferences of human judges. Finally, we take the initial steps towards Lay Summarisation for Natural Language Processing (NLP) articles, finding that LLMs are able to generalise to this new domain, and further highlighting the greater utility of summaries generated by our proposed approach via an in-depth human evaluation.
Observing Micromotives and Macrobehavior of Large Language Models
Dec 10, 2024Thomas C. Schelling, awarded the 2005 Nobel Memorial Prize in Economic Sciences, pointed out that ``individuals decisions (micromotives), while often personal and localized, can lead to societal outcomes (macrobehavior) that are far more complex and different from what the individuals intended.'' The current research related to large language models' (LLMs') micromotives, such as preferences or biases, assumes that users will make more appropriate decisions once LLMs are devoid of preferences or biases. Consequently, a series of studies has focused on removing bias from LLMs. In the NLP community, while there are many discussions on LLMs' micromotives, previous studies have seldom conducted a systematic examination of how LLMs may influence society's macrobehavior. In this paper, we follow the design of Schelling's model of segregation to observe the relationship between the micromotives and macrobehavior of LLMs. Our results indicate that, regardless of the level of bias in LLMs, a highly segregated society will emerge as more people follow LLMs' suggestions. We hope our discussion will spark further consideration of the fundamental assumption regarding the mitigation of LLMs' micromotives and encourage a reevaluation of how LLMs may influence users and society.
From Facts to Insights: A Study on the Generation and Evaluation of Analytical Reports for Deciphering Earnings Calls
Oct 01, 2024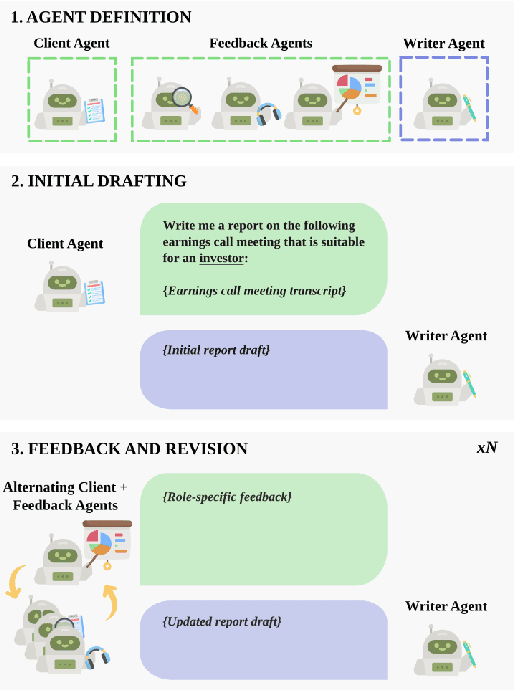
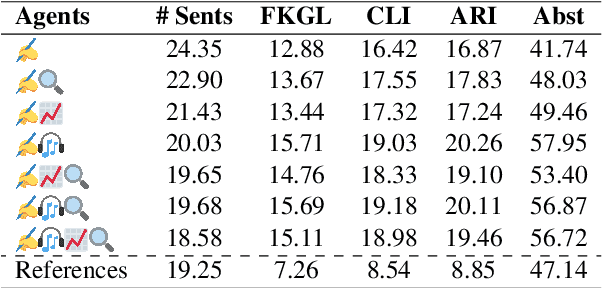
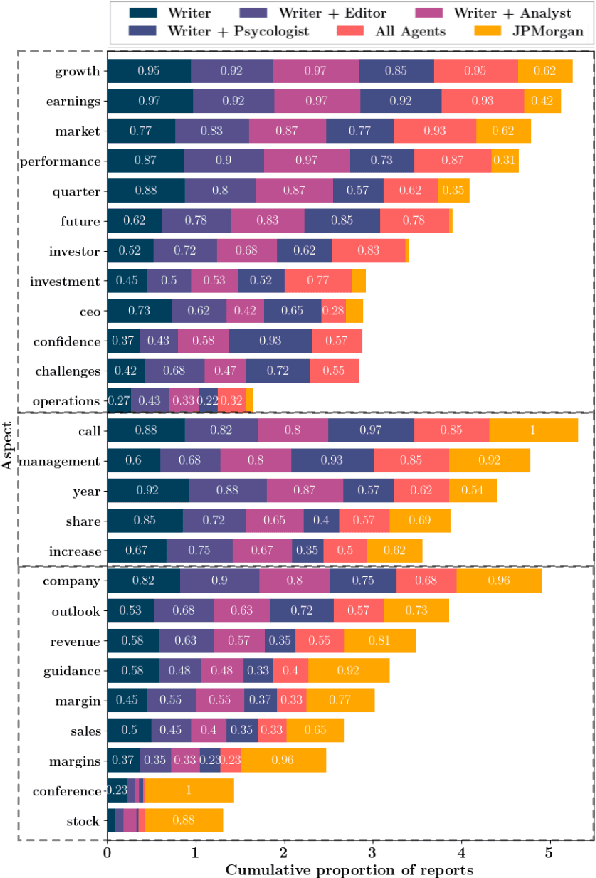

This paper explores the use of Large Language Models (LLMs) in the generation and evaluation of analytical reports derived from Earnings Calls (ECs). Addressing a current gap in research, we explore the generation of analytical reports with LLMs in a multi-agent framework, designing specialized agents that introduce diverse viewpoints and desirable topics of analysis into the report generation process. Through multiple analyses, we examine the alignment between generated and human-written reports and the impact of both individual and collective agents. Our findings suggest that the introduction of additional agents results in more insightful reports, although reports generated by human experts remain preferred in the majority of cases. Finally, we address the challenging issue of report evaluation, we examine the limitations and strengths of LLMs in assessing the quality of generated reports in different settings, revealing a significant correlation with human experts across multiple dimensions.
Overview of the BioLaySumm 2024 Shared Task on the Lay Summarization of Biomedical Research Articles
Aug 16, 2024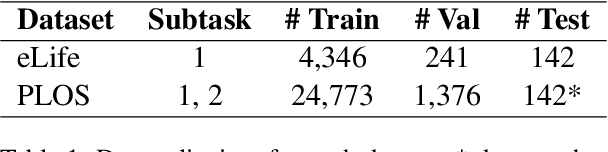
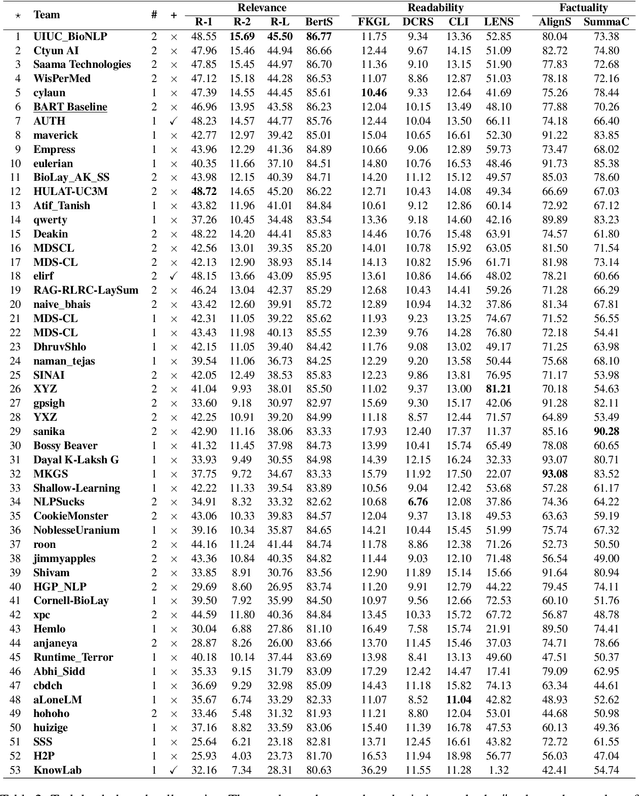
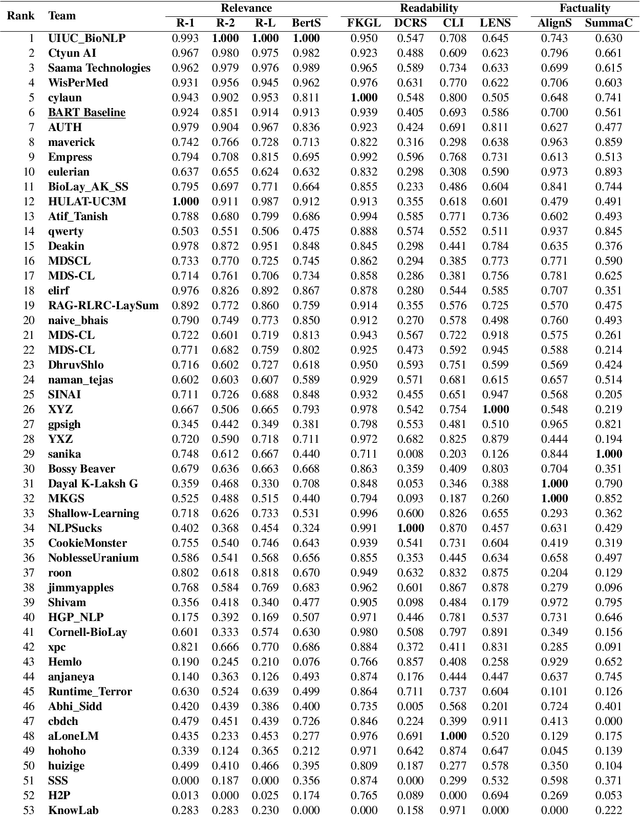
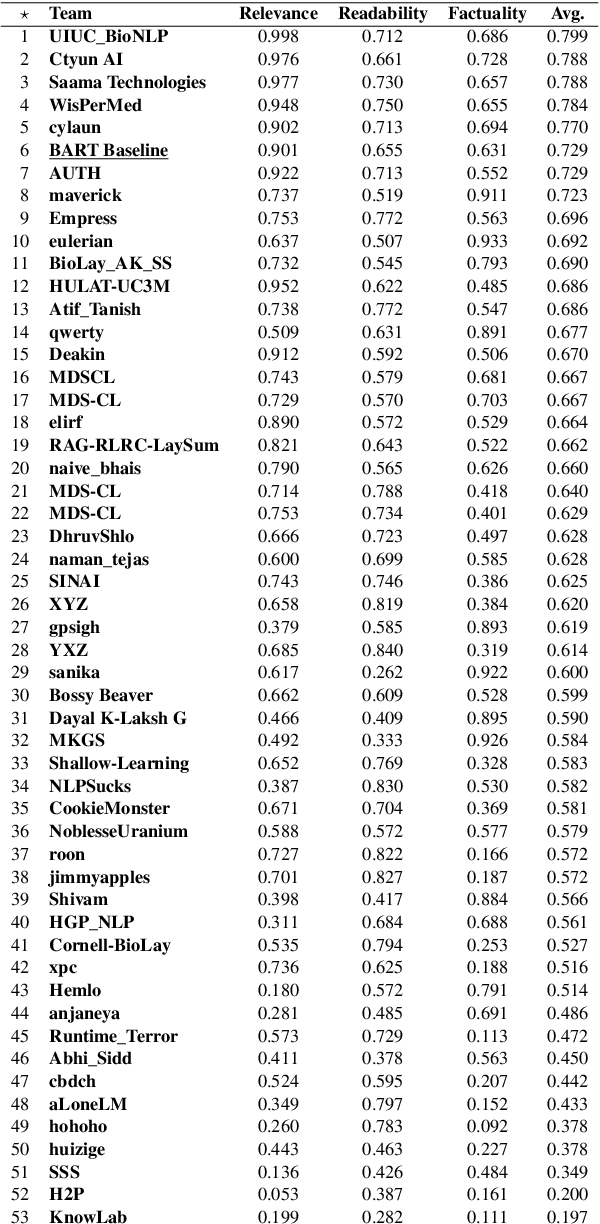
This paper presents the setup and results of the second edition of the BioLaySumm shared task on the Lay Summarisation of Biomedical Research Articles, hosted at the BioNLP Workshop at ACL 2024. In this task edition, we aim to build on the first edition's success by further increasing research interest in this important task and encouraging participants to explore novel approaches that will help advance the state-of-the-art. Encouragingly, we found research interest in the task to be high, with this edition of the task attracting a total of 53 participating teams, a significant increase in engagement from the previous edition. Overall, our results show that a broad range of innovative approaches were adopted by task participants, with a predictable shift towards the use of Large Language Models (LLMs).
ATLAS: Improving Lay Summarisation with Attribute-based Control
Jun 09, 2024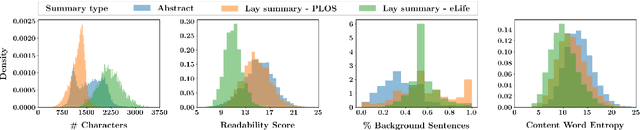
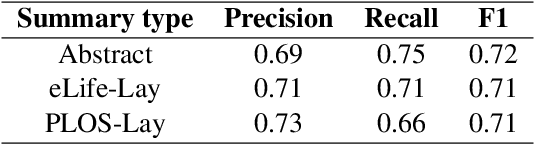
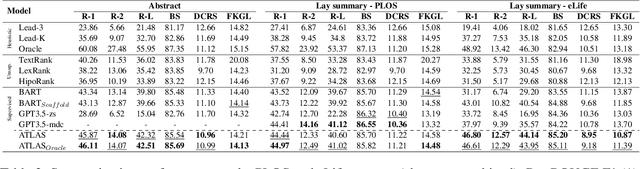
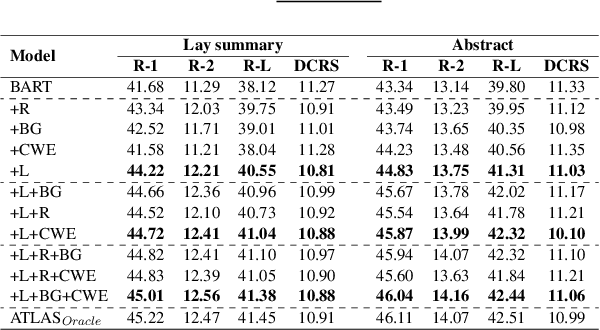
Lay summarisation aims to produce summaries of scientific articles that are comprehensible to non-expert audiences. However, previous work assumes a one-size-fits-all approach, where the content and style of the produced summary are entirely dependent on the data used to train the model. In practice, audiences with different levels of expertise will have specific needs, impacting what content should appear in a lay summary and how it should be presented. Aiming to address this, we propose ATLAS, a novel abstractive summarisation approach that can control various properties that contribute to the overall "layness" of the generated summary using targeted control attributes. We evaluate ATLAS on a combination of biomedical lay summarisation datasets, where it outperforms state-of-the-art baselines using mainstream summarisation metrics. Additional analyses provided on the discriminatory power and emergent influence of our selected controllable attributes further attest to the effectiveness of our approach.
Enhancing Biomedical Lay Summarisation with External Knowledge Graphs
Oct 24, 2023Previous approaches for automatic lay summarisation are exclusively reliant on the source article that, given it is written for a technical audience (e.g., researchers), is unlikely to explicitly define all technical concepts or state all of the background information that is relevant for a lay audience. We address this issue by augmenting eLife, an existing biomedical lay summarisation dataset, with article-specific knowledge graphs, each containing detailed information on relevant biomedical concepts. Using both automatic and human evaluations, we systematically investigate the effectiveness of three different approaches for incorporating knowledge graphs within lay summarisation models, with each method targeting a distinct area of the encoder-decoder model architecture. Our results confirm that integrating graph-based domain knowledge can significantly benefit lay summarisation by substantially increasing the readability of generated text and improving the explanation of technical concepts.
Improving Biomedical Abstractive Summarisation with Knowledge Aggregation from Citation Papers
Oct 24, 2023



Abstracts derived from biomedical literature possess distinct domain-specific characteristics, including specialised writing styles and biomedical terminologies, which necessitate a deep understanding of the related literature. As a result, existing language models struggle to generate technical summaries that are on par with those produced by biomedical experts, given the absence of domain-specific background knowledge. This paper aims to enhance the performance of language models in biomedical abstractive summarisation by aggregating knowledge from external papers cited within the source article. We propose a novel attention-based citation aggregation model that integrates domain-specific knowledge from citation papers, allowing neural networks to generate summaries by leveraging both the paper content and relevant knowledge from citation papers. Furthermore, we construct and release a large-scale biomedical summarisation dataset that serves as a foundation for our research. Extensive experiments demonstrate that our model outperforms state-of-the-art approaches and achieves substantial improvements in abstractive biomedical text summarisation.
* Accepted by EMNLP 2023
Making Science Simple: Corpora for the Lay Summarisation of Scientific Literature
Oct 18, 2022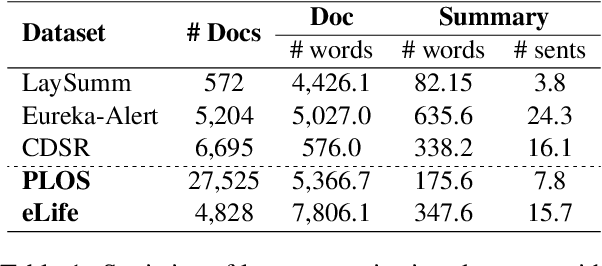
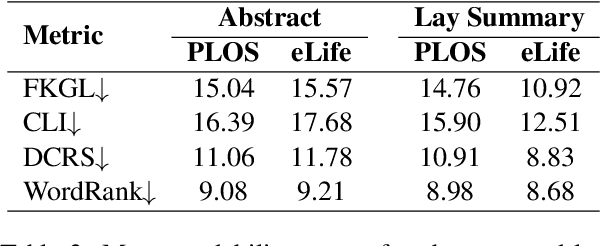
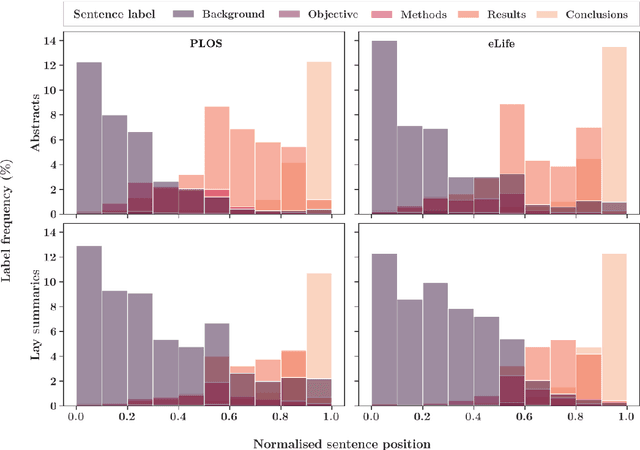
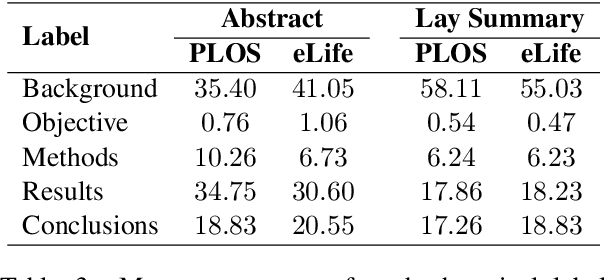
Lay summarisation aims to jointly summarise and simplify a given text, thus making its content more comprehensible to non-experts. Automatic approaches for lay summarisation can provide significant value in broadening access to scientific literature, enabling a greater degree of both interdisciplinary knowledge sharing and public understanding when it comes to research findings. However, current corpora for this task are limited in their size and scope, hindering the development of broadly applicable data-driven approaches. Aiming to rectify these issues, we present two novel lay summarisation datasets, PLOS (large-scale) and eLife (medium-scale), each of which contains biomedical journal articles alongside expert-written lay summaries. We provide a thorough characterisation of our lay summaries, highlighting differing levels of readability and abstractiveness between datasets that can be leveraged to support the needs of different applications. Finally, we benchmark our datasets using mainstream summarisation approaches and perform a manual evaluation with domain experts, demonstrating their utility and casting light on the key challenges of this task.