 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreAgentive: An Agent Workflow Driven Multi-Category Creative Generation Engine
Sep 30, 2025We present CreAgentive, an agent workflow driven multi-category creative generation engine that addresses four key limitations of contemporary large language models in writing stories, drama and other categories of creatives: restricted genre diversity, insufficient output length, weak narrative coherence, and inability to enforce complex structural constructs. At its core, CreAgentive employs a Story Prototype, which is a genre-agnostic, knowledge graph-based narrative representation that decouples story logic from stylistic realization by encoding characters, events, and environments as semantic triples. CreAgentive engages a three-stage agent workflow that comprises: an Initialization Stage that constructs a user-specified narrative skeleton; a Generation Stage in which long- and short-term objectives guide multi-agent dialogues to instantiate the Story Prototype; a Writing Stage that leverages this prototype to produce multi-genre text with advanced structures such as retrospection and foreshadowing. This architecture reduces storage redundancy and overcomes the typical bottlenecks of long-form generation. In extensive experiments, CreAgentive generates thousands of chapters with stable quality and low cost (less than $1 per 100 chapters) using a general-purpose backbone model. To evaluate performance, we define a two-dimensional framework with 10 narrative indicators measuring both quality and length. Results show that CreAgentive consistently outperforms strong baselines and achieves robust performance across diverse genres, approaching the quality of human-authored novels.
A Scenario-Driven Cognitive Approach to Next-Generation AI Memory
Sep 16, 2025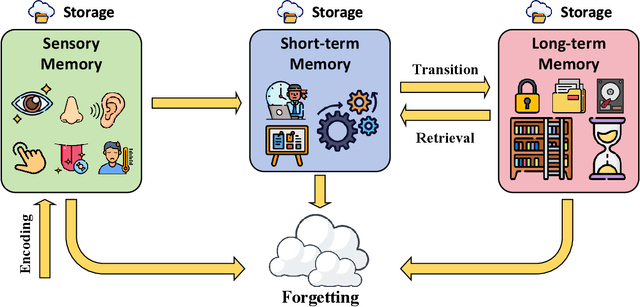
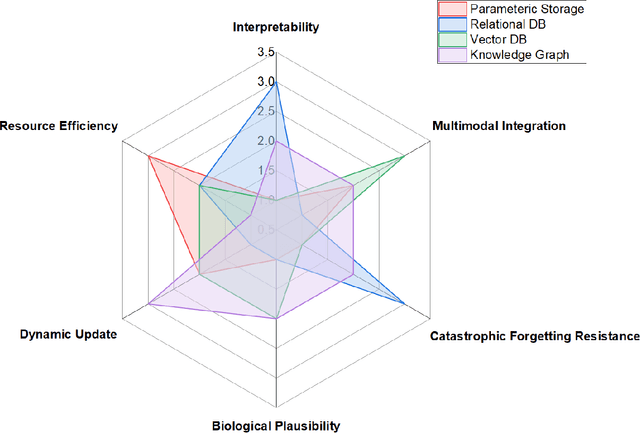
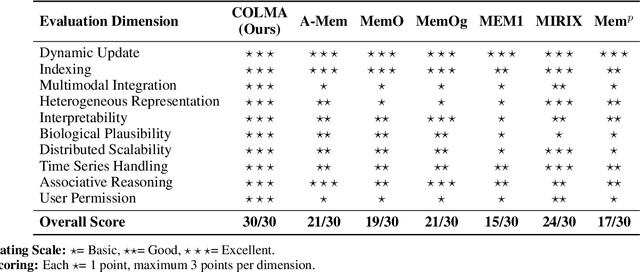
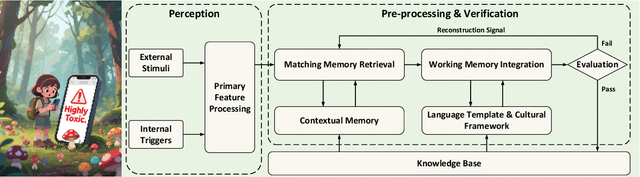
As artificial intelligence advances toward artificial general intelligence (AGI), the need for robust and human-like memory systems has become increasingly evident. Current memory architectures often suffer from limited adaptability, insufficient multimodal integration, and an inability to support continuous learning. To address these limitations, we propose a scenario-driven methodology that extracts essential functional requirements from representative cognitive scenarios, leading to a unified set of design principles for next-generation AI memory systems. Based on this approach, we introduce the \textbf{COgnitive Layered Memory Architecture (COLMA)}, a novel framework that integrates cognitive scenarios, memory processes, and storage mechanisms into a cohesive design. COLMA provides a structured foundation for developing AI systems capable of lifelong learning and human-like reasoning, thereby contributing to the pragmatic development of AGI.
Observing Micromotives and Macrobehavior of Large Language Models
Dec 10, 2024Thomas C. Schelling, awarded the 2005 Nobel Memorial Prize in Economic Sciences, pointed out that ``individuals decisions (micromotives), while often personal and localized, can lead to societal outcomes (macrobehavior) that are far more complex and different from what the individuals intended.'' The current research related to large language models' (LLMs') micromotives, such as preferences or biases, assumes that users will make more appropriate decisions once LLMs are devoid of preferences or biases. Consequently, a series of studies has focused on removing bias from LLMs. In the NLP community, while there are many discussions on LLMs' micromotives, previous studies have seldom conducted a systematic examination of how LLMs may influence society's macrobehavior. In this paper, we follow the design of Schelling's model of segregation to observe the relationship between the micromotives and macrobehavior of LLMs. Our results indicate that, regardless of the level of bias in LLMs, a highly segregated society will emerge as more people follow LLMs' suggestions. We hope our discussion will spark further consideration of the fundamental assumption regarding the mitigation of LLMs' micromotives and encourage a reevaluation of how LLMs may influence users and society.
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Apr 09, 2024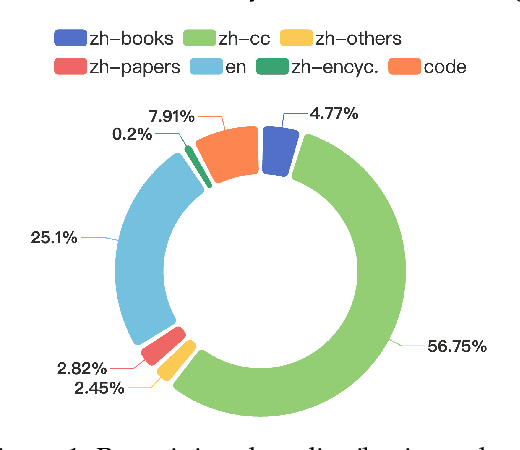

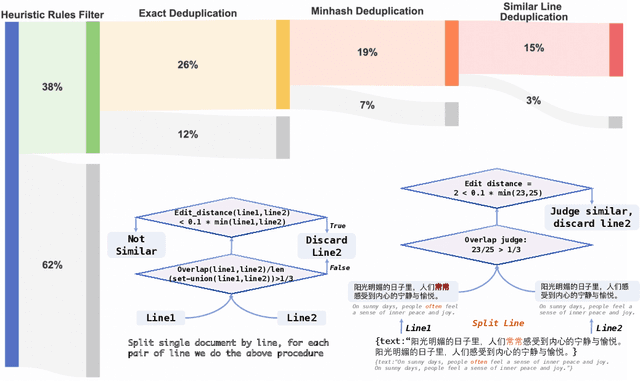

In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Jan 22, 2024As the capabilities of large multimodal models (LMMs) continue to advance, evaluating the performance of LMMs emerges as an increasing need. Additionally, there is an even larger gap in evaluating the advanced knowledge and reasoning abilities of LMMs in non-English contexts such as Chinese. We introduce CMMMU, a new Chinese Massive Multi-discipline Multimodal Understanding benchmark designed to evaluate LMMs on tasks demanding college-level subject knowledge and deliberate reasoning in a Chinese context. CMMMU is inspired by and strictly follows the annotation and analysis pattern of MMMU. CMMMU includes 12k manually collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering, like its companion, MMMU. These questions span 30 subjects and comprise 39 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. CMMMU focuses on complex perception and reasoning with domain-specific knowledge in the Chinese context. We evaluate 11 open-source LLMs and one proprietary GPT-4V(ision). Even GPT-4V only achieves accuracies of 42%, indicating a large space for improvement. CMMMU will boost the community to build the next-generation LMMs towards expert artificial intelligence and promote the democratization of LMMs by providing diverse language contexts.