 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThoughtFold: Folding Reasoning Chains via Introspective Preference Learning
Jun 02, 2026Large Reasoning Models (LRMs) have achieved remarkable progress thanks to Reinforcement Learning with Verifiable Rewards (RLVR) on Chain-of-Thoughts (CoTs). However, since long CoTs naturally contain trial and errors and mainstream RLVR approaches choose outcome-correct CoT trajectories for memorization, the redundant explorations in long CoTs are inevitably reinforced, which results in the over-thinking issues of LRMs. Previous attempts to resolve this issue mainly give more advantage to shorter trajectories, yet their learning signals are still outcome-based and cannot reduce the memorization of redundant explorations in long CoTs. Therefore, we propose ThoughtFold, a framework that leverages fine-grained preference learning to mitigate redundant explorations for efficient reasoning. ThoughtFold employs an introspective strategy to identify redundancy within each correct trajectory, which yields a spectrum of candidate sub-trajectories. Leveraging this spectrum, we introduce a masked preference optimization objective that explicitly penalizes redundant explorations and encourages the model to directly bridge essential reasoning segments, effectively folding its reasoning chains into a more concise path. Extensive experiments show that ThoughtFold significantly enhances efficiency. It reduces the token usage of DeepSeek-R1-Distill-Qwen-7B by approximately 56% while maintaining state-of-the-art accuracy.
Graphs of Research: Citation Evolution Graphs as Supervision for Research Idea Generation
May 14, 2026Research idea generation is the innovation-driving step of automated scientific research. Recently, large language models (LLMs) have shown potential for automating idea generation at scale. However, existing methods mainly condition LLMs on eliciting idea generation through static retrieval of relevant literature or complex prompt engineering, without discarding the structural relations among references. We propose Graphs of Research (GoR), a supervised fine-tuning method that extracts a 2-hop reference neighborhood for each seed paper, derives the relations among those references from citation position, frequency, predecessor links, and publication time, and organizes them into a paper-evolution directed acyclic graph (DAG). We construct an automated extraction pipeline that draws data from five major ML/NLP venues, comprising 498/50/50 train/validation/test seed papers and approximately 7,600 cited references. Qwen2.5-7B-Instruct-1M is fine-tuned on a structured-text prompt that includes the citation graph, edge signals, reference information, and task definition to predict the idea for the seed paper. Across head-to-head LLM-judge tournaments against gpt-4o-driven baselines, GoR-SFT achieves SOTA, demonstrating the effectiveness of citation-evolution graphs as supervision signal for LLM-based idea generation. We hope that this reduces the barrier for citation evolution graphs as a supervision, accelerating automated scientific innovation.
EVPO: Explained Variance Policy Optimization for Adaptive Critic Utilization in LLM Post-Training
Apr 21, 2026Reinforcement learning (RL) for LLM post-training faces a fundamental design choice: whether to use a learned critic as a baseline for policy optimization. Classical theory favors critic-based methods such as PPO for variance reduction, yet critic-free alternatives like GRPO have gained widespread adoption due to their simplicity and competitive performance. We show that in sparse-reward settings, a learned critic can inject estimation noise that exceeds the state signal it captures, increasing rather than reducing advantage variance. By casting baseline selection as a Kalman filtering problem, we unify PPO and GRPO as two extremes of the Kalman gain and prove that explained variance (EV), computable from a single training batch, identifies the exact boundary: positive EV indicates the critic reduces variance, while zero or negative EV signals that it inflates variance. Building on this insight, we propose Explained Variance Policy Optimization (EVPO), which monitors batch-level EV at each training step and adaptively switches between critic-based and batch-mean advantage estimation, provably achieving no greater variance than the better of the two at every step. Across four tasks spanning classical control, agentic interaction, and mathematical reasoning, EVPO consistently outperforms both PPO and GRPO regardless of which fixed baseline is stronger on a given task. Further analysis confirms that the adaptive gating tracks critic maturation over training and that the theoretically derived zero threshold is empirically optimal.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Long-horizon Reasoning Agent for Olympiad-Level Mathematical Problem Solving
Dec 12, 2025Large Reasoning Models (LRMs) have expanded the mathematical reasoning frontier through Chain-of-Thought (CoT) techniques and Reinforcement Learning with Verifiable Rewards (RLVR), capable of solving AIME-level problems. However, the performance of LRMs is heavily dependent on the extended reasoning context length. For solving ultra-hard problems like those in the International Mathematical Olympiad (IMO), the required reasoning complexity surpasses the space that an LRM can explore in a single round. Previous works attempt to extend the reasoning context of LRMs but remain prompt-based and built upon proprietary models, lacking systematic structures and training pipelines. Therefore, this paper introduces Intern-S1-MO, a long-horizon math agent that conducts multi-round hierarchical reasoning, composed of an LRM-based multi-agent system including reasoning, summary, and verification. By maintaining a compact memory in the form of lemmas, Intern-S1-MO can more freely explore the lemma-rich reasoning spaces in multiple reasoning stages, thereby breaking through the context constraints for IMO-level math problems. Furthermore, we propose OREAL-H, an RL framework for training the LRM using the online explored trajectories to simultaneously bootstrap the reasoning ability of LRM and elevate the overall performance of Intern-S1-MO. Experiments show that Intern-S1-MO can obtain 26 out of 35 points on the non-geometry problems of IMO2025, matching the performance of silver medalists. It also surpasses the current advanced LRMs on inference benchmarks such as HMMT2025, AIME2025, and CNMO2025. In addition, our agent officially participates in CMO2025 and achieves a score of 102/126 under the judgment of human experts, reaching the gold medal level.
Achieving Olympia-Level Geometry Large Language Model Agent via Complexity Boosting Reinforcement Learning
Dec 12, 2025Large language model (LLM) agents exhibit strong mathematical problem-solving abilities and can even solve International Mathematical Olympiad (IMO) level problems with the assistance of formal proof systems. However, due to weak heuristics for auxiliary constructions, AI for geometry problem solving remains dominated by expert models such as AlphaGeometry 2, which rely heavily on large-scale data synthesis and search for both training and evaluation. In this work, we make the first attempt to build a medalist-level LLM agent for geometry and present InternGeometry. InternGeometry overcomes the heuristic limitations in geometry by iteratively proposing propositions and auxiliary constructions, verifying them with a symbolic engine, and reflecting on the engine's feedback to guide subsequent proposals. A dynamic memory mechanism enables InternGeometry to conduct more than two hundred interactions with the symbolic engine per problem. To further accelerate learning, we introduce Complexity-Boosting Reinforcement Learning (CBRL), which gradually increases the complexity of synthesized problems across training stages. Built on InternThinker-32B, InternGeometry solves 44 of 50 IMO geometry problems (2000-2024), exceeding the average gold medalist score (40.9), using only 13K training examples, just 0.004% of the data used by AlphaGeometry 2, demonstrating the potential of LLM agents on expert-level geometry tasks. InternGeometry can also propose novel auxiliary constructions for IMO problems that do not appear in human solutions. We will release the model, data, and symbolic engine to support future research.
OPV: Outcome-based Process Verifier for Efficient Long Chain-of-Thought Verification
Dec 11, 2025Large language models (LLMs) have achieved significant progress in solving complex reasoning tasks by Reinforcement Learning with Verifiable Rewards (RLVR). This advancement is also inseparable from the oversight automated by reliable verifiers. However, current outcome-based verifiers (OVs) are unable to inspect the unreliable intermediate steps in the long reasoning chains of thought (CoTs). Meanwhile, current process-based verifiers (PVs) have difficulties in reliably detecting errors in the complex long CoTs, limited by the scarcity of high-quality annotations due to the prohibitive costs of human annotations. Therefore, we propose the Outcome-based Process Verifier (OPV), which verifies the rationale process of summarized outcomes from long CoTs to achieve both accurate and efficient verification and enable large-scale annotation. To empower the proposed verifier, we adopt an iterative active learning framework with expert annotations to progressively improve the verification capability of OPV with fewer annotation costs. Specifically, in each iteration, the most uncertain cases of the current best OPV are annotated and then subsequently used to train a new OPV through Rejection Fine-Tuning (RFT) and RLVR for the next round. Extensive experiments demonstrate OPV's superior performance and broad applicability. It achieves new state-of-the-art results on our held-out OPV-Bench, outperforming much larger open-source models such as Qwen3-Max-Preview with an F1 score of 83.1 compared to 76.3. Furthermore, OPV effectively detects false positives within synthetic dataset, closely align with expert assessment. When collaborating with policy models, OPV consistently yields performance gains, e.g., raising the accuracy of DeepSeek-R1-Distill-Qwen-32B from 55.2% to 73.3% on AIME2025 as the compute budget scales.
Semi-off-Policy Reinforcement Learning for Vision-Language Slow-thinking Reasoning
Jul 22, 2025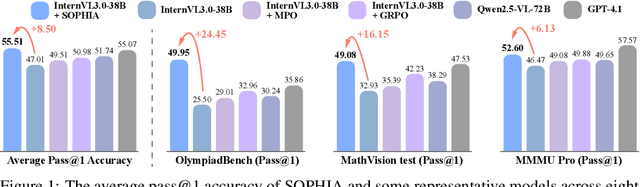
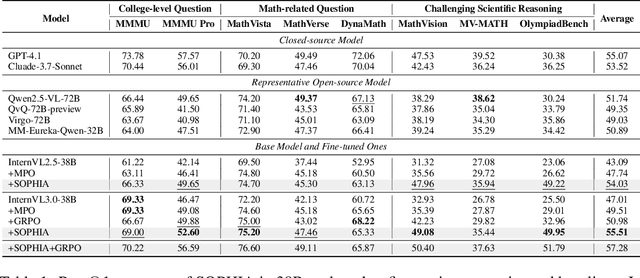
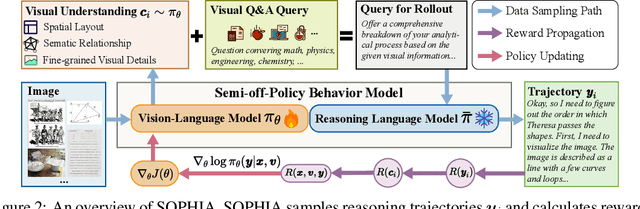
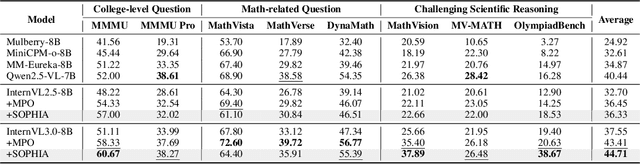
Enhancing large vision-language models (LVLMs) with visual slow-thinking reasoning is crucial for solving complex multimodal tasks. However, since LVLMs are mainly trained with vision-language alignment, it is difficult to adopt on-policy reinforcement learning (RL) to develop the slow thinking ability because the rollout space is restricted by its initial abilities. Off-policy RL offers a way to go beyond the current policy, but directly distilling trajectories from external models may cause visual hallucinations due to mismatched visual perception abilities across models. To address these issues, this paper proposes SOPHIA, a simple and scalable Semi-Off-Policy RL for vision-language slow-tHInking reAsoning. SOPHIA builds a semi-off-policy behavior model by combining on-policy visual understanding from a trainable LVLM with off-policy slow-thinking reasoning from a language model, assigns outcome-based rewards to reasoning, and propagates visual rewards backward. Then LVLM learns slow-thinking reasoning ability from the obtained reasoning trajectories using propagated rewards via off-policy RL algorithms. Extensive experiments with InternVL2.5 and InternVL3.0 with 8B and 38B sizes show the effectiveness of SOPHIA. Notably, SOPHIA improves InternVL3.0-38B by 8.50% in average, reaching state-of-the-art performance among open-source LVLMs on multiple multimodal reasoning benchmarks, and even outperforms some closed-source models (e.g., GPT-4.1) on the challenging MathVision and OlympiadBench, achieving 49.08% and 49.95% pass@1 accuracy, respectively. Analysis shows SOPHIA outperforms supervised fine-tuning and direct on-policy RL methods, offering a better policy initialization for further on-policy training.
The Imitation Game: Turing Machine Imitator is Length Generalizable Reasoner
Jul 17, 2025Length generalization, the ability to solve problems of longer sequences than those observed during training, poses a core challenge of Transformer-based large language models (LLM). Although existing studies have predominantly focused on data-driven approaches for arithmetic operations and symbolic manipulation tasks, these approaches tend to be task-specific with limited overall performance. To pursue a more general solution, this paper focuses on a broader case of reasoning problems that are computable, i.e., problems that algorithms can solve, thus can be solved by the Turing Machine. From this perspective, this paper proposes Turing MAchine Imitation Learning (TAIL) to improve the length generalization ability of LLMs. TAIL synthesizes chain-of-thoughts (CoT) data that imitate the execution process of a Turing Machine by computer programs, which linearly expands the reasoning steps into atomic states to alleviate shortcut learning and explicit memory fetch mechanism to reduce the difficulties of dynamic and long-range data access in elementary operations. To validate the reliability and universality of TAIL, we construct a challenging synthetic dataset covering 8 classes of algorithms and 18 tasks. Without bells and whistles, TAIL significantly improves the length generalization ability as well as the performance of Qwen2.5-7B on various tasks using only synthetic data, surpassing previous methods and DeepSeek-R1. The experimental results reveal that the key concepts in the Turing Machine, instead of the thinking styles, are indispensable for TAIL for length generalization, through which the model exhibits read-and-write behaviors consistent with the properties of the Turing Machine in their attention layers. This work provides a promising direction for future research in the learning of LLM reasoning from synthetic data.
Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law
Jun 16, 2025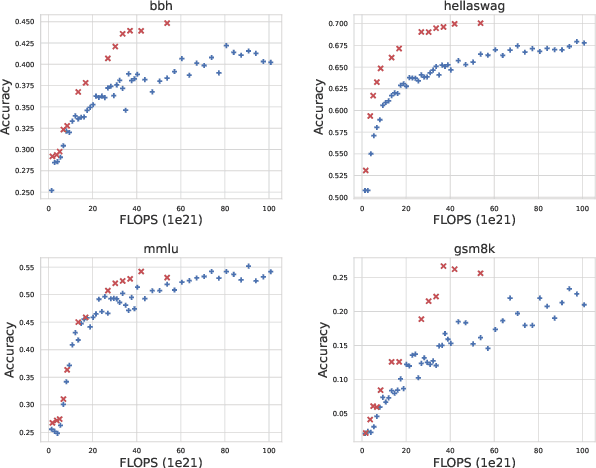
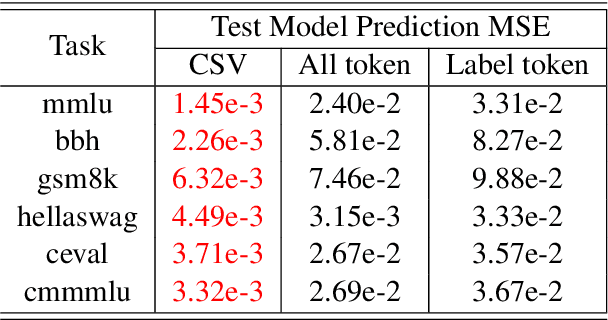
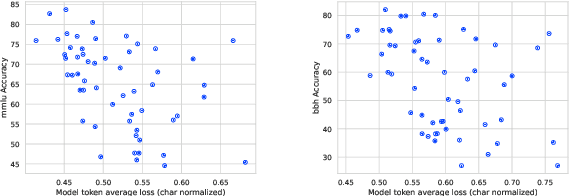
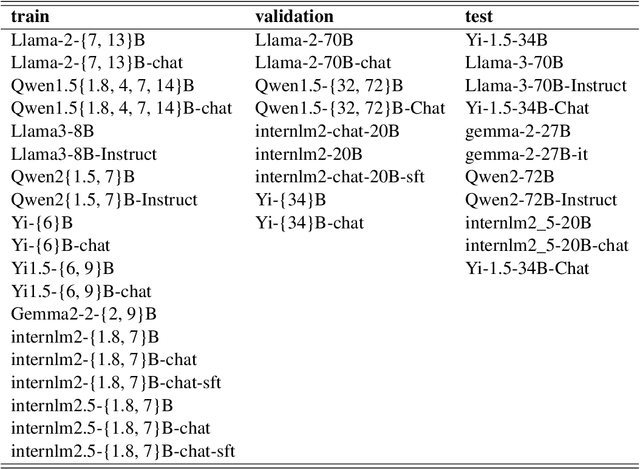
Scaling law builds the relationship between training computation and validation loss, enabling researchers to effectively predict the loss trending of models across different levels of computation. However, a gap still remains between validation loss and the model's downstream capabilities, making it untrivial to apply scaling law to direct performance prediction for downstream tasks. The loss typically represents a cumulative penalty for predicted tokens, which are implicitly considered to have equal importance. Nevertheless, our studies have shown evidence that when considering different training data distributions, we cannot directly model the relationship between downstream capability and computation or token loss. To bridge the gap between validation loss and downstream task capabilities, in this work, we introduce Capability Salience Vector, which decomposes the overall loss and assigns different importance weights to tokens to assess a specific meta-capability, aligning the validation loss with downstream task performance in terms of the model's capabilities. Experiments on various popular benchmarks demonstrate that our proposed Capability Salience Vector could significantly improve the predictability of language model performance on downstream tasks.