 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFPO: Scaling Value Modeling via Distributional Flow towards Robust and Generalizable LLM Post-Training
Feb 05, 2026Training reinforcement learning (RL) systems in real-world environments remains challenging due to noisy supervision and poor out-of-domain (OOD) generalization, especially in LLM post-training. Recent distributional RL methods improve robustness by modeling values with multiple quantile points, but they still learn each quantile independently as a scalar. This results in rough-grained value representations that lack fine-grained conditioning on state information, struggling under complex and OOD conditions. We propose DFPO (Distributional Value Flow Policy Optimization with Conditional Risk and Consistency Control), a robust distributional RL framework that models values as continuous flows across time steps. By scaling value modeling through learning of a value flow field instead of isolated quantile predictions, DFPO captures richer state information for more accurate advantage estimation. To stabilize training under noisy feedback, DFPO further integrates conditional risk control and consistency constraints along value flow trajectories. Experiments on dialogue, math reasoning, and scientific tasks show that DFPO outperforms PPO, FlowRL, and other robust baselines under noisy supervision, achieving improved training stability and generalization.
LLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
LLMEval-Med: A Real-world Clinical Benchmark for Medical LLMs with Physician Validation
Jun 04, 2025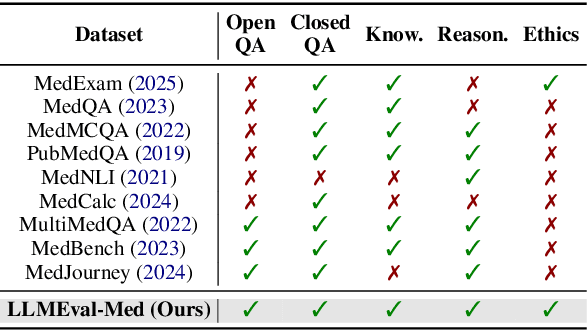
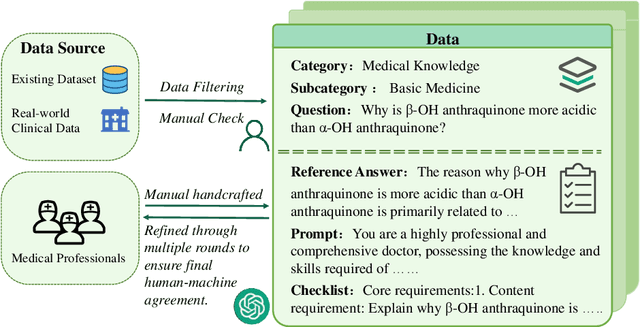
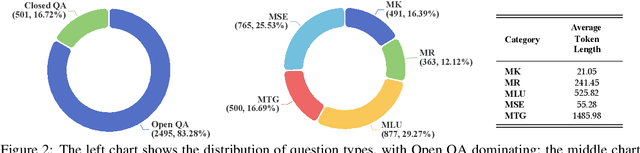
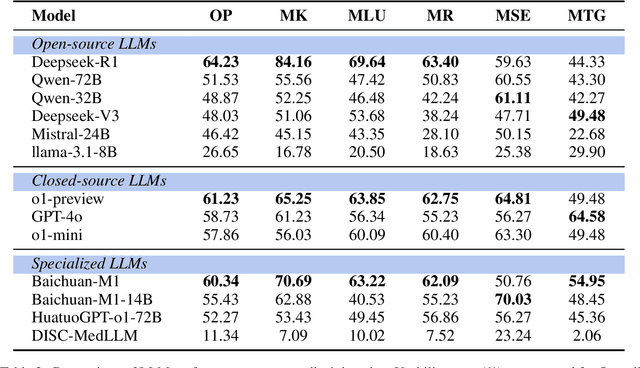
Evaluating large language models (LLMs) in medicine is crucial because medical applications require high accuracy with little room for error. Current medical benchmarks have three main types: medical exam-based, comprehensive medical, and specialized assessments. However, these benchmarks have limitations in question design (mostly multiple-choice), data sources (often not derived from real clinical scenarios), and evaluation methods (poor assessment of complex reasoning). To address these issues, we present LLMEval-Med, a new benchmark covering five core medical areas, including 2,996 questions created from real-world electronic health records and expert-designed clinical scenarios. We also design an automated evaluation pipeline, incorporating expert-developed checklists into our LLM-as-Judge framework. Furthermore, our methodology validates machine scoring through human-machine agreement analysis, dynamically refining checklists and prompts based on expert feedback to ensure reliability. We evaluate 13 LLMs across three categories (specialized medical models, open-source models, and closed-source models) on LLMEval-Med, providing valuable insights for the safe and effective deployment of LLMs in medical domains. The dataset is released in https://github.com/llmeval/LLMEval-Med.
Two Minds Better Than One: Collaborative Reward Modeling for LLM Alignment
May 19, 2025Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human values. However, noisy preferences in human feedback can lead to reward misgeneralization - a phenomenon where reward models learn spurious correlations or overfit to noisy preferences, which poses important challenges to the generalization of RMs. This paper systematically analyzes the characteristics of preference pairs and aims to identify how noisy preferences differ from human-aligned preferences in reward modeling. Our analysis reveals that noisy preferences are difficult for RMs to fit, as they cause sharp training fluctuations and irregular gradient updates. These distinctive dynamics suggest the feasibility of identifying and excluding such noisy preferences. Empirical studies demonstrate that policy LLM optimized with a reward model trained on the full preference dataset, which includes substantial noise, performs worse than the one trained on a subset of exclusively high quality preferences. To address this challenge, we propose an online Collaborative Reward Modeling (CRM) framework to achieve robust preference learning through peer review and curriculum learning. In particular, CRM maintains two RMs that collaboratively filter potential noisy preferences by peer-reviewing each other's data selections. Curriculum learning synchronizes the capabilities of two models, mitigating excessive disparities to promote the utility of peer review. Extensive experiments demonstrate that CRM significantly enhances RM generalization, with up to 9.94 points improvement on RewardBench under an extreme 40\% noise. Moreover, CRM can seamlessly extend to implicit-reward alignment methods, offering a robust and versatile alignment strategy.
DocFusion: A Unified Framework for Document Parsing Tasks
Dec 17, 2024



Document parsing is essential for analyzing complex document structures and extracting fine-grained information, supporting numerous downstream applications. However, existing methods often require integrating multiple independent models to handle various parsing tasks, leading to high complexity and maintenance overhead. To address this, we propose DocFusion, a lightweight generative model with only 0.28B parameters. It unifies task representations and achieves collaborative training through an improved objective function. Experiments reveal and leverage the mutually beneficial interaction among recognition tasks, and integrating recognition data significantly enhances detection performance. The final results demonstrate that DocFusion achieves state-of-the-art (SOTA) performance across four key tasks.
Modeling Layout Reading Order as Ordering Relations for Visually-rich Document Understanding
Sep 29, 2024Modeling and leveraging layout reading order in visually-rich documents (VrDs) is critical in document intelligence as it captures the rich structure semantics within documents. Previous works typically formulated layout reading order as a permutation of layout elements, i.e. a sequence containing all the layout elements. However, we argue that this formulation does not adequately convey the complete reading order information in the layout, which may potentially lead to performance decline in downstream VrD tasks. To address this issue, we propose to model the layout reading order as ordering relations over the set of layout elements, which have sufficient expressive capability for the complete reading order information. To enable empirical evaluation on methods towards the improved form of reading order prediction (ROP), we establish a comprehensive benchmark dataset including the reading order annotation as relations over layout elements, together with a relation-extraction-based method that outperforms previous methods. Moreover, to highlight the practical benefits of introducing the improved form of layout reading order, we propose a reading-order-relation-enhancing pipeline to improve model performance on any arbitrary VrD task by introducing additional reading order relation inputs. Comprehensive results demonstrate that the pipeline generally benefits downstream VrD tasks: (1) with utilizing the reading order relation information, the enhanced downstream models achieve SOTA results on both two task settings of the targeted dataset; (2) with utilizing the pseudo reading order information generated by the proposed ROP model, the performance of the enhanced models has improved across all three models and eight cross-domain VrD-IE/QA task settings without targeted optimization.
What's Wrong with Your Code Generated by Large Language Models? An Extensive Study
Jul 08, 2024
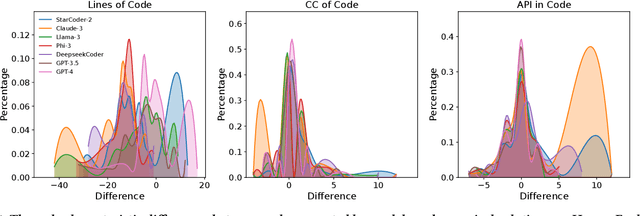


The increasing development of large language models (LLMs) in code generation has drawn significant attention among researchers. To enhance LLM-based code generation ability, current efforts are predominantly directed towards collecting high-quality datasets and leveraging diverse training technologies. However, there is a notable lack of comprehensive studies examining the limitations and boundaries of these existing methods. To bridge this gap, we conducted an extensive empirical study evaluating the performance of three leading closed-source LLMs and four popular open-source LLMs on three commonly used benchmarks. Our investigation, which evaluated the length, cyclomatic complexity and API number of the generated code, revealed that these LLMs face challenges in generating successful code for more complex problems, and tend to produce code that is shorter yet more complicated as compared to canonical solutions. Additionally, we developed a taxonomy of bugs for incorrect codes that includes three categories and 12 sub-categories, and analyze the root cause for common bug types. Furthermore, to better understand the performance of LLMs in real-world projects, we manually created a real-world benchmark comprising 140 code generation tasks. Our analysis highlights distinct differences in bug distributions between actual scenarios and existing benchmarks. Finally, we propose a novel training-free iterative method that introduces self-critique, enabling LLMs to critique and correct their generated code based on bug types and compiler feedback. Experimental results demonstrate that our approach can significantly mitigate bugs and increase the passing rate by 29.2% after two iterations, indicating substantial potential for LLMs to handle more complex problems.
EasyJailbreak: A Unified Framework for Jailbreaking Large Language Models
Mar 18, 2024



Jailbreak attacks are crucial for identifying and mitigating the security vulnerabilities of Large Language Models (LLMs). They are designed to bypass safeguards and elicit prohibited outputs. However, due to significant differences among various jailbreak methods, there is no standard implementation framework available for the community, which limits comprehensive security evaluations. This paper introduces EasyJailbreak, a unified framework simplifying the construction and evaluation of jailbreak attacks against LLMs. It builds jailbreak attacks using four components: Selector, Mutator, Constraint, and Evaluator. This modular framework enables researchers to easily construct attacks from combinations of novel and existing components. So far, EasyJailbreak supports 11 distinct jailbreak methods and facilitates the security validation of a broad spectrum of LLMs. Our validation across 10 distinct LLMs reveals a significant vulnerability, with an average breach probability of 60% under various jailbreaking attacks. Notably, even advanced models like GPT-3.5-Turbo and GPT-4 exhibit average Attack Success Rates (ASR) of 57% and 33%, respectively. We have released a wealth of resources for researchers, including a web platform, PyPI published package, screencast video, and experimental outputs.